Data Science und Machine Learning im Kubernetes-Ökosystem
2 likes537 views

Die Präsentation behandelt die Nutzung von Data Science und Machine Learning im Kubernetes-Ökosystem, einschließlich spezifischer Anwendungsfälle wie der Bildgebung in der Massenspektrometrie. Die Autoren erörtern die Entwicklung von Workflows, die Nutzung verschiedener Tools und Komponenten sowie die Herausforderungen und Möglichkeiten beim Einsatz von Kubernetes für maschinelles Lernen. Ein Ausblick wird auf zukünftige Projekte und Anwendungen gegeben, wobei betont wird, dass Flexibilität, Skalierbarkeit und Benutzerfreundlichkeit entscheidend sind.






































Data Science und Machine Learning im Kubernetes-Ökosystem
- 1. DATA SCIENCE UND MACHINE LEARNING IM KUBERNETES- ÖKOSYSTEM Hans-Peter Zorn, Stefan Igel Heidelberg, 26. September 2018
- 2. ● Use-case: Analyse von bildgebender Massenspektronomie ● Data Science Workflows & ML Plattformen ● K8S als Basis für ML Plattformen ● Tools & Komponenten für DS-Workflows ● Ausblick Agenda
- 3. › Expertensystem zur Qualitätsbewertung und Auswertung 3-dimensionaler Massenspektroskopiedaten › F&E-Projekt von Hochschule Mannheim und inovex › Laufzeit: 01.11.2017 - 31.10.2019 Use Case: EMQ Projekt Setup
- 4. Data acquisition 4 von x Image Sources: Nature Reviews Cancer 10, 639-646 09/2010 Molecular Oncology 4, Issue 6, 529-538 12/2010 Bruker Rapiflex MALDI-TOF/TOF Mass spectrometer Kidney tissue slice Microscopic image Typical applications • Clinical diagnostic • Pharmaceutical monitoring • Histological research MALDI Mass Spectrometry Basic workflow & application
- 5. 5 von x MSI Datacubes A state of the art MALDI-imaging dataset comprises a huge amount of spectra (up to 100k spectra) with each raw spectrum representing intensities (usually 10k – 100k) of small m/z bins and describing up to hundreds of different molecules. Data generation time: sample preparation (30 – 90 min), data acquisition (2 pixels / sec ~ 14 h, currently with the next generation MALDI system up to 50 pixels / sec ~ 30 – 50 min), Data analysis (~ 1 h) → Total time ~ 2 – 3.5 h / tissue sample. Jones, Emrys A., et al. Journal of proteomics 75.16 (2012): 4962-4989.
- 6. 1. support data science team processes 2. democratization of data 3. democratization of machine learning Data Science / Machine Learning Plattformen Ziel: Professionalisieren von Data Science
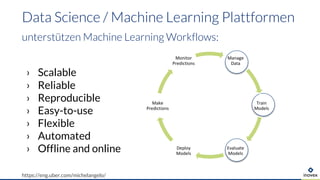
- 7. › Scalable › Reliable › Reproducible › Easy-to-use › Flexible › Automated › Offline and online Data Science / Machine Learning Plattformen unterstützen Machine Learning Workflows: https://eng.uber.com/michelangelo/ Manage Data Train Models Evaluate Models Deploy Models Make Predictions Monitor Predictions
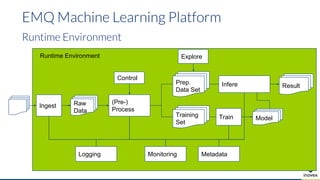
- 8. EMQ Machine Learning Platform Explore (Pre-) Process Train Raw Data Ingest Prep. Data Set Training Set Infere Model Control Result MonitoringLogging Metadata Runtime Environment
- 9. EMQ Machine Learning Platform Runtime Environment Explore (Pre-) Process Train Raw Data Ingest Prep. Data Set Training Set Infere Model Control Result MonitoringLogging Metadata Runtime Environment
- 10. Scalable? Sounds like Big Data ... Is there anything beyond Hadoop? Linux Kernel YARN, Zookeeper CoreOS, Kubernetes HDFS S3, NFS, Ceph, Quobyte, ... JVM Docker MapReduce, Tez, Spark, ... Spark, Tensorflow, ... Hadoop Stack Kubernetes Stack Distributed Processing Operating System Cluster Management Distributed Storage Processing Core Unit HBaseDistributed Serving elastic, Cassandra, Druid, ...
- 11. Scalable? Sounds like Big Data ... Is there anything beyond Hadoop? Linux Kernel YARN, Zookeeper CoreOS, Kubernetes HDFS S3, NFS, Ceph, Quobyte, ... JVM Docker MapReduce, Tez, Spark, ... Spark, Tensorflow, ... Hadoop Stack Kubernetes Stack Distributed Processing Operating System Cluster Management Distributed Storage Processing Core Unit HBaseDistributed Serving elastic, Cassandra, Druid, ...
- 12. › everything you need to build and scale › build, ship and run any app, anywhere › container orchestration, automated management, deployment, scaling › package manager for K8S Apps Ingredients for K8S Solutions Bare Metal, Public & Private Cloud https://www.inovex.de/fileadmin/files/Vortraege/2017/big-data-in-der-cloud-zorn-kreiling-29.09.2017.pdf
- 13. ● Meistverbreitetes Containerformat ● Leichtgewichtig ● Resource Limitation ● Verfügbarkeit von Registries Packaging Docker, weil… https://www.inovex.de/fileadmin/files/Vortraege/2017/big-data-in-der-cloud-zorn-kreiling-29.09.2017.pdf
- 14. ● Hardware-Abstraktion ● Container Scheduling und Management ● Service Discovery & Networking ● Konfigurationsmanagement ● Monitoring ● Load Balancing ● Rolling upgrades Deployment Kubernetes, wegen… https://www.inovex.de/fileadmin/files/Vortraege/2017/big-data-in-der-cloud-zorn-kreiling-29.09.2017.pdf
- 15. ● Paketmanager ● Convenience ● Zahlreiche Vorlagen ● Templating Funktionalität Dependency Management Helm, für... https://www.inovex.de/fileadmin/files/Vortraege/2017/big-data-in-der-cloud-zorn-kreiling-29.09.2017.pdf
- 16. › Infrastructure as Code › Cloud Provider agnostic › Software Defined Networking › Disposable Environments Continuous Integration Terraform, weil ...
- 17. • Integration mit Gitlab • Einfach zu definierende CI-Pipelines • Integrierte Docker Registry Continuous Integration Gitlab-CI, weil https://www.inovex.de/fileadmin/files/Vortraege/2017/big-data-in-der-cloud-zorn-kreiling-29.09.2017.pdf
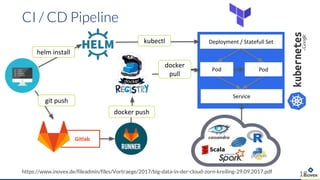
- 18. CI / CD Pipeline https://www.inovex.de/fileadmin/files/Vortraege/2017/big-data-in-der-cloud-zorn-kreiling-29.09.2017.pdf 18 Gitlab docker push git push helm install Service Deployment / Statefull Setkubectl docker pull PodPod
- 19. EMQ Machine Learning Platform Ingest & Store Explore (Pre-) Process Train Raw Data Ingest Prep. Data Set Training Set Infere Model Control Result MonitoringLogging Metadata Runtime Environment
- 20. Distributed File System Ingest & Store Data Lake Stream Processing NoSQL DB File Transfer Runtime Environment Msg Online - Streaming Offline - Batch NoSQL DB
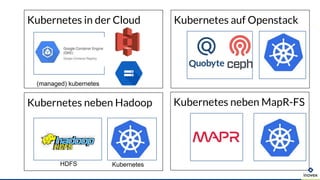
- 21. Kubernetes auf OpenstackKubernetes in der Cloud Kubernetes neben Hadoop HDFS Kubernetes (managed) kubernetes Kubernetes neben MapR-FS
- 22. EMQ Machine Learning Platform (Pre-)Processing Explore (Pre-) Process Train Raw Data Ingest Prep. Data Set Training Set Infere Model Control Result MonitoringLogging Metadata Runtime Environment
- 23. • integrate legacy algorithms • different programming languages (C++, R, Python, ...) • different base images (Pre-)Processing Standardized Data Processing
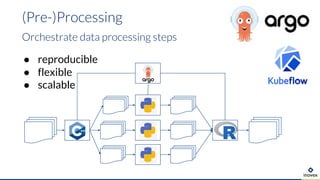
- 24. (Pre-)Processing Orchestrate data processing steps ● reproducible ● flexible ● scalable
- 25. (Pre-)Processing argo Architecture › Kubernetes API Erweiterung (CRD) › Batch Job Pattern › Data Handling per Buckets (S3)
- 26. EMQ Machine Learning Platform Explore & Analyze Explore (Pre-) Process Train Raw Data Ingest Prep. Data Set Training Set Infere Model Control Result MonitoringLogging Metadata Runtime Environment
- 27. › Jupyter notebooks › Language of choice (Python, R, Scala, ... › Notebooks can be shared (git, ...) › Big data integration (Apache Spark) › pandas, scikit-learn, ggplot2, TensorFlow › Jupyter Hub › Multi-user Hub for Data Science Workgroups › spawns, manages, and proxies multiple instances of the single-user Jupyter notebook server. Train Models Jupyter Hub
- 28. › multi-user Hub (tornado process) › configurable http proxy (node-http-proxy) › multiple single-user Jupyter notebook servers (Python/Jupyter/tornado) › REST API for administration of the Hub and its users. Train Models Jupyter Hub https://github.com/jupyterhub/jupyterhub https://jupyterhub.readthedocs.io/en/stable/
- 29. EMQ Machine Learning Platform Model Training & Inference Explore (Pre-) Process Train Raw Data Ingest Prep. Data Set Training Set Infere Model Control Result MonitoringLogging Metadata Runtime Environment
- 30. › Herbst 2015, Google › “library for high performance numerical computation” › ML/ DL support › TensorBoard Deep Learning https://www.inovex.de/fileadmin/files/Vortraege/2018/skalieren-von-deep-learning-frameworks-m3-26.04.2018.pdf Tensorflow
- 31. › Parameter Server › multi CPU/ GPU, multi Node › Infrastruktur: keine Voraussetzungen › IP-Adressen/ Hostnamen + Port Deep Learning Scaling Tensorflow Carnegie Mellon University, Baidu, Google: “Scaling Distributed Machine Learning with the Parameter Server” (2014) Worker Worker Worker Parameter Server
- 32. › Distributed (Deep) Machine Learning Community (DMLC) › “A flexible and efficient library for deep learning.” › Amazons Framework der Wahl › (TensorBoard Support) Deep Learning Apache MXNet https://www.inovex.de/fileadmin/files/Vortraege/2018/skalieren-von-deep-learning-frameworks-m3-26.04.2018.pdf
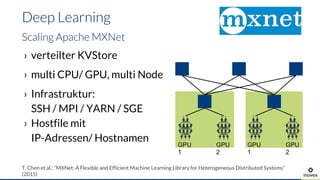
- 33. › verteilter KVStore › multi CPU/ GPU, multi Node › Infrastruktur: SSH / MPI / YARN / SGE › Hostfile mit IP-Adressen/ Hostnamen Deep Learning Scaling Apache MXNet T. Chen et al.: “MXNet: A Flexible and Efficient Machine Learning Library for Heterogeneous Distributed Systems” (2015) GPU 1 GPU 2 GPU 1 GPU 2
- 34. › DevicePlugin installieren › Base Image: nvidia/cuda › GPU Ressourcen verwenden Deep Learning GPU Support mit Kubernetes https://www.inovex.de/fileadmin/files/Vortraege/2018/skalieren-von-deep-learning-frameworks-m3-26.04.2018.pdf 1 resources: 2 limits: 3 nvidia.com/gpu: {{ $numGpus }}
- 35. 3 Ways to run Spark on k8s: ● Spark in standalone mode: https://github.com/helm/charts/tree/master/stable/spark ● Spark operator on Kubernetes: https://github.com/GoogleCloudPlatform/spark-on-k8s-operator ● Using spark-submit: https://spark.apache.org/docs/2.3.0/running-on-kubernetes.html Train Models Distributed Machine Learning
- 36. spark-submit: ● Spark creates a Spark driver running within a k8s pod. ● The driver creates executors running within k8s pods, connects to them, and executes application code. Train Models Distributed Machine Learning https://spark.apache.org/docs/2.3.0/running-on-kubernetes.html
- 37. EMQ Machine Learning Platform Logging & Monitoring Explore (Pre-) Process Train Raw Data Ingest Prep. Data Set Training Set Infere Model Control Result MonitoringLogging Metadata Runtime Environment
- 38. Logging & Monitoring } } } } Buffering und Transformation Sammeln von Logs Datenbank Frontend
- 39. Logging & Monitoring } } Sammeln von Metriken Frontend } Datenbank
- 40. EMQ Machine Learning Platform Metadata Management Explore (Pre-) Process Train Raw Data Ingest Prep. Data Set Training Set Infere Model Control Result MonitoringLogging Metadata Runtime Environment
- 41. ● über die Umgebung ● über die Daten ● über die Workflows ● über die Modelle ● über die Fachlichkeit ● ... Metadata … Daten über Daten
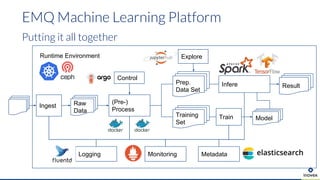
- 42. EMQ Machine Learning Platform Putting it all together Explore (Pre-) Process Train Raw Data Ingest Prep. Data Set Training Set Infere Model Control Result MonitoringLogging Metadata Runtime Environment
- 43. › Platform hardening › Adaption und Erweiterung für neue use-cases › NLP/Semantische Suche › IIoT › Metadaten › Modell-Management › Verbreitung Ausblick Manage Data Train Models Evaluat e Models Deploy Models Make Predicti ons Monitor Predicti ons
- 44. › Sebastian Schmidt › Alexander Grizschancew › Sebastian Jäger › Alexander Lontke › Julien Heitmann › Marcel Hofmann › Kevin Exel › David Waidner Das Team … ohne das es das alles bei uns nicht gäbe › Matthias Schwartz › Stanislav Frolov › David Schmidt › Daniel Bäurer › Nils Domrose › Hans-Peter Zorn › Stefan Igel
- 45. Vielen Dank Hans-Peter Zorn Head of Machine Perception & AI [email protected] Dr. Stefan Igel Head of Big Data Solutions [email protected]