





















Data Science Week 2016. NVIDIA. "Платформы и инструменты для реализации систем искусственного интеллекта"
- 1. Антон Джораев ПЛАТФОРМА NVIDIA ДЛЯ РЕАЛИЗАЦИИ СИСТЕМ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА
- 2. 2 AI IS EVERYWHERE “Find where I parked my car” “Find the bag I just saw in this magazine” “What movie should I watch next?”
- 3. 3 TOUCHING OUR LIVES Bringing grandmother closer to family by bridging language barrier Predicting sick baby’s vitals like heart rate, blood pressure, survival rate Enabling the blind to “see” their surrounding, read emotions on faces
- 4. 4 FUELING ALL INDUSTRIES Increasing public safety with smart video surveillance at airports & malls Providing intelligent services in hotels, banks and stores Separating weeds as it harvests, reduces chemical usage by 90%
- 5. 5 NVIDIA DEEP LEARNING SOFTWARE PLATFORM NVIDIA DEEP LEARNING SDK DEVELOP WITH DIGITS TensorRT TRAINED NETWORK TRAINING DATA TRAINING DATA MANAGEMENT MODEL ASSESSMENT EMBEDDED AUTOMOTIVE DATA CENTER
- 7. 7 TENSORRT INFERENCE RUNTIME High-performance deep learning inference for production deployment developer.nvidia.com/TensorRT 0 1 2 3 4 5 6 7 8 1 8 128 CPU-Only Tesla M4 + TensorRT Up to 16x More Inference Perf/Watt Batch Sizes GoogLenet, CPU-only vs Tesla M4 + TensorRT on Single-socket Haswell E5-2698 [email protected] with HT Images/Second/Watt EMBEDDED Jetson TX1 AUTOMOTIVE Drive PX DATA CENTER Tesla M4
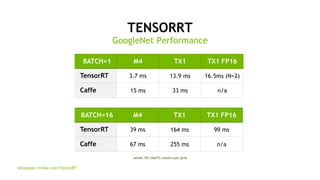
- 8. 8 TENSORRT GoogleNet Performance BATCH=1 M4 TX1 TX1 FP16 TensorRT 3.7 ms 13.9 ms 16.5ms (N=2) Caffe 15 ms 33 ms n/a developer.nvidia.com/TensorRT BATCH=16 M4 TX1 TX1 FP16 TensorRT 39 ms 164 ms 99 ms Caffe 67 ms 255 ms n/a Jetson TX1 HALF2 column uses fp16
- 9. 9 DEEP LEARNING DEMANDS NEW CLASS OF HPC TRAINING INFERENCING Data / Users Scalable Performance Throughput + Efficiency Billions of TFLOPS per training run Years of compute-days on Xeon CPU GPU turns years to days Billions of FLOPS per inference Seconds for response on Xeon CPU GPU for instant response
- 10. 10 BAIDU DEEP SPEECH 2 12K Neurons 100M Parameters 2.5x Deep Speech 1 4x Deep Speech 1 15 Exaflops Super-human Accuracy 10x Deep Speech 1 2 Months on CPU Server | 2 Days on DGX-1 Word Error Rate DS2: 5% | Human: 6% | DS1: 8% “Deep Speech 2: End-to-End Speech Recognition in English and Mandarin”, 12/2015 | Dataset: LibriSpeech test-clean
- 11. 11 MODERN AI NEEDS NEW INFERENCE SOLUTION 0 0,5 1 1,5 2 2,5 Network Network Deep Speech 2 User Wait Time (seconds) “Where is the nearest Szechuan restaurant?” User Experience: From Seconds to Instant Wait Time for Text after Speech is Complete 6 sec CPU 0.1 sec Pascal GPU Deep Speech 2 inference performance on 16 user server | CPU: 170 ms of estimated compute time required for each 100 ms of speech sample | Pascal GPU: 51 ms of compute required for each 100 ms of speech sample 2.2 sec CPU
- 12. 12 40x Efficient vs CPU, 8x Efficient vs FPGA 0 50 100 150 200 AlexNet CPU FPGA 1x M4 (FP32) 1x P4 (INT8) Images/Sec/Watt Maximum Efficiency for Scale-out Servers P4 # of CUDA Cores 2560 Peak Single Precision 5.5 TeraFLOPS Peak INT8 22 TOPS Low Precision 4x 8-bit vector dot product with 32-bit accumulate Video Engines 1x decode engine, 2x encode engine GDDR5 Memory 8 GB @ 192 GB/s Power 50W & 75 W AlexNet, batch size = 128, CPU: Intel E5-2690v4 using Intel MKL 2017, FPGA is Arria10-115 1x M4/P4 in node, P4 board power at 56W, P4 GPU power at 36W, M4 board power at 57W, M4 GPU power at 39W, Perf/W chart using GPU power TESLA P4
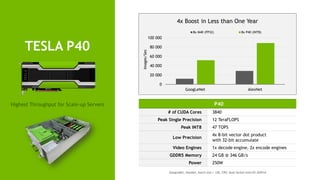
- 13. 13 TESLA P40 P40 # of CUDA Cores 3840 Peak Single Precision 12 TeraFLOPS Peak INT8 47 TOPS Low Precision 4x 8-bit vector dot product with 32-bit accumulate Video Engines 1x decode engine, 2x encode engines GDDR5 Memory 24 GB @ 346 GB/s Power 250W 0 20 000 40 000 60 000 80 000 100 000 GoogLeNet AlexNet 8x M40 (FP32) 8x P40 (INT8) Images/Sec 4x Boost in Less than One Year GoogLeNet, AlexNet, batch size = 128, CPU: Dual Socket Intel E5-2697v4 Highest Throughput for Scale-up Servers
- 14. 14NVIDIA CONFIDENTIAL. DO NOT DISTRIBUTE. P40/P4 – NEW “INT8” FOR INFERENCE A0A1A2A3 B0B1B2B3 A0 * B0 A1 * B1 A2 * B2 A3 * B3 4x INT8 4x INT8 INT32 intermediate INT32 intermediate INT32 intermediate INT32 intermediate INT32C INT32 PRODUCT PRECISION INFERENCE TOPS* M4 FP32 2.2 M40 FP32 7 P100 FP16 21.2 P4 INT8 22 P40 INT8 47 • Integer 8-bit Dot Product with 32-bit accumulate • New in Pascal, only in P40/P4 *TOPS = Tera-Operations per second, base on boost clocks
- 15. 15NVIDIA CONFIDENTIAL. DO NOT DISTRIBUTE. 178 480 1 514 4 121 3 200 6 514 0 1 000 2 000 3 000 4 000 5 000 6 000 7 000 E5-2690v4 14 Core M4 (FP32) M40 (FP32) P100 (FP16) P4 (INT8) P40 (INT8) InferenceImage/sec All results are measured, based on GoogLenet with batch size 128 Xeon uses MKL 2017 GOLD with FP32, GPU uses TensorRT internal development ver. P40/P4+TensorRT DELIVER MAX INFERENCE PERFORMANCE >35x 1,4 12,3 10,6 27,9 91,1 56,3 0 20 40 60 80 100 E5-2690v4 14 Core M4 (FP32) M40 (FP32) P100 (FP16) P4 (INT8) P40 (INT8) InferenceImg/s/watt >60x P40 For Max Inference Throughput P4 For Max Inference Efficiency
- 16. 16 NVIDIA DEEPSTREAM SDK Delivering Video Analytics at Scale Inference Preprocess Hardware Decode “Boy playing soccer” Simple, high performance API for analyzing video Decode H.264, HEVC, MPEG-2, MPEG-4, VP9 CUDA-optimized resize and scale TensorRT 0 20 40 60 80 100 1x Tesla P4 Server + DeepStream SDK 13x E5-2650 v4 Servers ConcurrentVideoStreams Concurrent Video Streams Analyzed 720p30 decode | IntelCaffe using dual socket E5-2650 v4 CPU servers, Intel MKL 2017 Based on GoogLeNet optimized by Intel: https://github.com/intel/caffe/tree/master/models/mkl2017_googlenet_v2
- 17. 18 TESLA DEEP LEARNING PLATFORM TRAINING INFERENCING DIGITS Training System Deep Learning Frameworks Tesla P100 DeepStream SDK TensorRT Tesla P40 & P4
- 18. 19NVIDIA CONFIDENTIAL. DO NOT DISTRIBUTE. END-TO-END PRODUCT FAMILY MIXED-APPS HPC Tesla P100 PCIE STRONG-SCALE HPC Tesla P100 SXM2 DL SUPERCOMPUTER DGX-1 Get going now with fully integrated DL solution Hyperscale & HPC data centers running apps that scale to multiple GPUs HPC data centers running mix of CPU and GPU workloads HYPERSCALE HPC Tesla P4, P40 Hyperscale deployment for DL training, inference, video & image processing
- 19. 20 Jetson TX1 JETSON TX1 GPU 1 TFLOP/s 256-core Maxwell CPU 64-bit ARM A57 CPUs Memory 4 GB LPDDR4 | 25.6 GB/s Video decode 4K 60Hz Video encode 4K 30Hz CSI Up to 6 cameras | 1400 Mpix/s Display 2x DSI, 1x eDP 1.4, 1x DP 1.2/HDMI Wifi 802.11 2x2 ac Networking 1 Gigabit Ethernet PCIE Gen 2 1x1 + 1x4 Storage 16 GB eMMC, SDIO, SATA Other 3x UART, 3x SPI, 4x I2C, 4x I2S, GPIOs
- 20. 21 Jetson TX1 Developer Kit
- 22. 23 DL-TRACK НА КОНФЕРЕНЦИИ В МОСКВЕ Russian Supercomputing Days 2016 26 сентября