Data-Defined Typed Schema Generation in Accumulo
0 likes204 views

The document discusses a method for schema-less storage and processing of semi-structured data in Accumulo, focusing on automatically discovering and applying schemas for records represented in formats like JSON. It outlines an approach for merging and collapsing data types, utilizing Spark SQL to query the stored data effectively. Key implementation strategies include using a custom combiner iterator in Accumulo and integrating with Spark for schema management and querying capabilities.








![©Koverse 9
Merging Record Schemas {
“name” : [
“string”
],
“age” : [
“integer”
],
“homeTown” : [
“string”
],
“favoriteColor” : [
“string”,
“boolean”
]
}
{
“name” : “string”,
“age” : “integer”,
“homeTown” : “string”,
“favoriteColor” : “string”
}
{
“name” : “string”,
“age” : “integer”,
“favoriteColor” : “boolean”
}
S
S
S](https://image.slidesharecdn.com/2017-data-definedtypedschemagenerationinaccumulo-171016161430/85/Data-Defined-Typed-Schema-Generation-in-Accumulo-9-320.jpg)

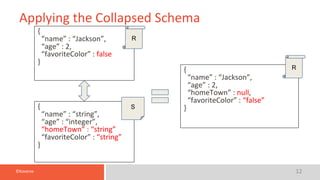
![©Koverse 11
Collapsing the Schema
{
“name” : [
“string”
],
“age” : [
“integer”
],
“homeTown” : [
“string”
],
“favoriteColor” : [
“string”,
“boolean”
]
}
{
“name” : “string”,
“age” : “integer”,
“homeTown” : “string”
“favoriteColor” : “string”
}
S
S](https://image.slidesharecdn.com/2017-data-definedtypedschemagenerationinaccumulo-171016161430/85/Data-Defined-Typed-Schema-Generation-in-Accumulo-11-320.jpg)






Data-Defined Typed Schema Generation in Accumulo
- 2. ● Store semi-structured data in Accumulo ● Not require any type of schema to be defined before storing it. ● Query or otherwise process that data with an existing schema-oriented framework like Spark SQL. ● Discover the schema instead of create it. ©Koverse 2 Motivation What do we want to do?
- 3. ©Koverse 3 The Problem A lack of: • Methodologies • Algorithms • Experience What keeps us from doing this?
- 4. ©Koverse 4 Approach ● Represent all data as records. ● Store records in a data set. ● Determine the schema of each record. ● Combine the schema of all records into a data set schema. ● Apply the data set schema to all records.
- 8. ©Koverse 8 The schemas? A Data Set has as many schemas as it does records. So what is the schema of the Data Set? S S S S S SS S S S ?R R R RR R R R
- 10. When records have different types for the same field, we have to decide what the ultimate type will be. The string type is the most general. ©Koverse 10 Merging field types How to handle conflicts of data types? string boolean integer double string string string string string boolean string boolean string string integer string string integer double double string string double double
- 13. ● Key – Row ID: Data Set Identifier + Record Identifier – Column Family: Field Name – Column Qualifier: N/A – Visibility: Whatever you need – Timestamp: Write time ● Value (byte array) – 1st byte: Field type – Remaining bytes: Field value ©Koverse 13 Record Implementation in Accumulo Many possibilities. A basic idea for storing records in a table...
- 14. ● Key – Row ID: Data Set Id – Column Family: Field Name – Column Qualifier: N/A – Visibility: Whatever you need – Timestamp: Write time ● Value: Field Type ©Koverse 14 Schema Implementation in Accumulo Write record schemas to a different table, use a Combiner Iterator (next slide)
- 15. Combine the Accumulo field value using this table. ©Koverse 15 Schema Combiner Iterator Create a custom Combiner Iterator to reduce the schema types. string boolean integer double string string string string string boolean string boolean string string integer string string integer double double string string double double
- 16. 1. Read the records of a data set into an RDD (from Accumulo) 2. Read the data set schema (from Accumulo) 3. Convert that schema into a Spark Data Frame Schema 4. Map the RDD so that every record conforms to the schema 5. Create a Spark Data Frame using the schema and the RDD 6. You can now use SQL queries for your schema-less records. ©Koverse 16 Spark SQL How to make it work?
- 17. Use Spark SQL hooks: ● Column Filtering (Pruned Scans) ● Push-Down Predicates (Pruned Filtered Scans) ● Use a Spark SQL Data Set (same name but different) ● Use Spark SQL Catalogs (like a real SQL database!) ● Use Spark SQL Data Streams ©Koverse 17 Spark SQL Future Improvements