Deep Dive into Spark SQL with Advanced Performance Tuning with Xiao Li & Wenchen Fan
15 likes11,597 views

The document discusses the features and performance tuning of Apache Spark SQL, highlighting its capabilities in processing and analyzing diverse data sources efficiently. It details advanced features introduced in Spark 2.3 and best practices for optimizing query execution, including memory management and data source selection. Additionally, it introduces Databricks Delta as a solution for improving data management reliability and simplifying ETL processes within cloud data lakes.









![New Features of Spark SQL in Spark 2.3
• PySpark Pandas UDFs [SPARK-22216] [SPARK-21187]
• Stable Codegen [SPARK-22510] [SPARK-22692]
• Advanced pushdown for partition pruning predicates [SPARK-20331]
• Vectorized ORC reader [SPARK-20682] [SPARK-16060]
• Vectorized cache reader [SPARK-20822]
• Histogram support in cost-based optimizer [SPARK-21975]
• Better Hive compatibility [SPARK-20236] [SPARK-17729] [SPARK-4131]
• More efficient and extensible data source API V2
10](https://image.slidesharecdn.com/2018-180620022016/85/Deep-Dive-into-Spark-SQL-with-Advanced-Performance-Tuning-with-Xiao-Li-Wenchen-Fan-10-320.jpg)






![Declarative APIs
17
When should I use SQL, DataFrames or Datasets?
• The DataFrame API provides untyped relational operations
• The Dataset API provides a typed version, at the cost of
performance due to heavy reliance on user-defined
closures/lambdas.
[SPARK-14083]
• http://dbricks.co/29xYnqR](https://image.slidesharecdn.com/2018-180620022016/85/Deep-Dive-into-Spark-SQL-with-Advanced-Performance-Tuning-with-Xiao-Li-Wenchen-Fan-17-320.jpg)

![Metadata Catalog
• Persistent Hive metastore [Hive 0.12 - Hive 2.3.3]
• Session-local temporary view manager
• Cross-session global temporary view manager
• Session-local function registry
19](https://image.slidesharecdn.com/2018-180620022016/85/Deep-Dive-into-Spark-SQL-with-Advanced-Performance-Tuning-with-Xiao-Li-Wenchen-Fan-19-320.jpg)

![Performance Tips - Catalog
Time costs of partition metadata retrieval:
- Upgrade your Hive metastore
- Avoid very high cardinality of partition columns
- Partition pruning predicates (improved in [SPARK-20331])
21](https://image.slidesharecdn.com/2018-180620022016/85/Deep-Dive-into-Spark-SQL-with-Advanced-Performance-Tuning-with-Xiao-Li-Wenchen-Fan-21-320.jpg)


![Performance Tips
Cache: not always fast if spilled to disk.
- Uncache it, if not needed.
Next releases:
- A new cache mechanism for building the snapshot in
cache. Querying stale data. Resolved by names instead
of by plans. [SPARK-24461]
24](https://image.slidesharecdn.com/2018-180620022016/85/Deep-Dive-into-Spark-SQL-with-Advanced-Performance-Tuning-with-Xiao-Li-Wenchen-Fan-24-320.jpg)

![Performance Tips
Roll your own Optimizer and Planner Rules
• In class ExperimentalMethods
• var extraOptimizations: Seq[Rule[LogicalPlan]] = Nil
• var extraStrategies: Seq[Strategy] = Nil
• Examples in the Herman’s talk Deep Dive into Catalyst
Optimizer
• Join two intervals: http://dbricks.co/2etjIDY
27](https://image.slidesharecdn.com/2018-180620022016/85/Deep-Dive-into-Spark-SQL-with-Advanced-Performance-Tuning-with-Xiao-Li-Wenchen-Fan-27-320.jpg)


















Deep Dive into Spark SQL with Advanced Performance Tuning with Xiao Li & Wenchen Fan
- 1. Deep Dive Into Xiao Li & Wenchen Fan Spark Summit | SF | Jun 2018 1 SQL with Advanced Performance Tuning
- 2. About US • Software Engineers at • Apache Spark Committers and PMC Members Xiao Li (Github: gatorsmile) Wenchen Fan (Github: cloud-fan)
- 3. Databricks’ Unified Analytics Platform DATABRICKS RUNTIME COLLABORATIVE NOTEBOOKS Delta SQL Streaming Powered by Data Engineers Data Scientists CLOUD NATIVE SERVICE Unifies Data Engineers and Data Scientists Unifies Data and AI Technologies Eliminates infrastructure complexity
- 4. Spark SQL A highly scalable and efficient relational processing engine with ease-to-use APIs and mid-query fault tolerance. 4
- 5. Run Everywhere Processes, integrates and analyzes the data from diverse data sources (e.g., Cassandra, Kafka and Oracle) and file formats (e.g., Parquet, ORC, CSV, and JSON) 5
- 6. The not-so-secret truth... 6 is not only SQL.SQL
- 7. Spark SQL 7
- 8. Not Only SQL Powers and optimizes the other Spark applications and libraries: • Structured streaming for stream processing • MLlib for machine learning • GraphFrame for graph-parallel computation • Your own Spark applications that use SQL, DataFrame and Dataset APIs 8
- 9. Lazy Evaluation 9 Optimization happens as late as possible, therefore Spark SQL can optimize across functions and libraries Holistic optimization when using these libraries and SQL/DataFrame/Dataset APIs in the same Spark application.
- 10. New Features of Spark SQL in Spark 2.3 • PySpark Pandas UDFs [SPARK-22216] [SPARK-21187] • Stable Codegen [SPARK-22510] [SPARK-22692] • Advanced pushdown for partition pruning predicates [SPARK-20331] • Vectorized ORC reader [SPARK-20682] [SPARK-16060] • Vectorized cache reader [SPARK-20822] • Histogram support in cost-based optimizer [SPARK-21975] • Better Hive compatibility [SPARK-20236] [SPARK-17729] [SPARK-4131] • More efficient and extensible data source API V2 10
- 11. Spark SQL 11 A compiler from queries to RDDs.
- 12. Performance Tuning for Optimal Plans Run EXPLAIN Plan. Interpret Plan. Tune Plan. 12
- 13. 13 Get the plans by running Explain command/APIs, or the SQL tab in either Spark UI or Spark History Server
- 14. 14 More statistics from the Job page
- 16. Declarative APIs Declare your intentions by • SQL API: ANSI SQL:2003 and HiveQL. • Dataset/DataFrame APIs: richer, language- integrated and user-friendly interfaces 16
- 17. Declarative APIs 17 When should I use SQL, DataFrames or Datasets? • The DataFrame API provides untyped relational operations • The Dataset API provides a typed version, at the cost of performance due to heavy reliance on user-defined closures/lambdas. [SPARK-14083] • http://dbricks.co/29xYnqR
- 19. Metadata Catalog • Persistent Hive metastore [Hive 0.12 - Hive 2.3.3] • Session-local temporary view manager • Cross-session global temporary view manager • Session-local function registry 19
- 20. Metadata Catalog Session-local function registry • Easy-to-use lambda UDF • Vectorized PySpark Pandas UDF • Native UDAF interface • Support Hive UDF, UDAF and UDTF • Almost 300 built-in SQL functions • Next, SPARK-23899 adds 30+ high-order built-in functions. • Blog for high-order functions: https://dbricks.co/2rR8vAr 20
- 21. Performance Tips - Catalog Time costs of partition metadata retrieval: - Upgrade your Hive metastore - Avoid very high cardinality of partition columns - Partition pruning predicates (improved in [SPARK-20331]) 21
- 22. Cache Manager 22
- 23. Cache Manager • Automatically replace by cached data when plan matching • Cross-session • Dropping/Inserting tables/views invalidates all the caches that depend on it • Lazy evaluation 23
- 24. Performance Tips Cache: not always fast if spilled to disk. - Uncache it, if not needed. Next releases: - A new cache mechanism for building the snapshot in cache. Querying stale data. Resolved by names instead of by plans. [SPARK-24461] 24
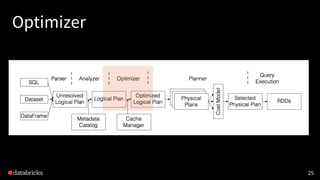
- 25. Optimizer 25
- 26. Optimizer Rewrites the query plans using heuristics and cost. 26 • Outer join elimination • Constraint propagation • Join reordering and many more. • Column pruning • Predicate push down • Constant folding
- 27. Performance Tips Roll your own Optimizer and Planner Rules • In class ExperimentalMethods • var extraOptimizations: Seq[Rule[LogicalPlan]] = Nil • var extraStrategies: Seq[Strategy] = Nil • Examples in the Herman’s talk Deep Dive into Catalyst Optimizer • Join two intervals: http://dbricks.co/2etjIDY 27
- 28. Planner 28
- 29. Planner • Turn logical plans to physical plans. (what to how) • Pick the best physical plan according to the cost 29 table1 table2 Join broadcast hash join sort merge join OR broadcast join has lower cost if one table can fit in memory table1 table2 table1 table2
- 30. Performance Tips - Join Selection 30 table 1 table 2 join result broadcast broadcast join table 1 table 2 shuffled shuffled join result shuffle join
- 31. Performance Tips - Join Selection broadcast join vs shuffle join (broadcast is faster) • spark.sql.autoBroadcastJoinThreshold • Keep the statistics updated • broadcastJoin Hint 31
- 32. Performance Tips - Equal Join … t1 JOIN t2 ON t1.id = t2.id AND t1.value < t2.value … t1 JOIN t2 ON t1.value < t2.value Put at least one equal predicate in join condition 32
- 33. Performance Tips - Equal Join … t1 JOIN t2 ON t1.id = t2.id AND t1.value < t2.value … t1 JOIN t2 ON t1.value < t2.value 33 O(n ^ 2) O(n)
- 35. Query Execution • Memory Manager: tracks the memory usage, efficiently distribute memory between tasks/operators. • Code Generator: compiles the physical plan to optimal java code. • Tungsten Engine: efficient binary data format and data structure for CPU and memory efficiency. 35
- 36. Performance Tips - Memory Manager Tune spark.executor.memory and spark.memory.fraction to leave enough space for unsupervised memory. Some memory usages are NOT tracked by Spark(netty buffer, parquet writer buffer). Set spark.memory.offHeap.enabled and spark.memory.offHeap.size to enable offheap, and decrease spark.executor.memory accordingly. 36
- 37. Whole Stage Code Generation
- 38. Performance Tip - WholeStage codegen Tune spark.sql.codegen.hugeMethodLimit to avoid big method(> 8k) that can’t be compiled by JIT compiler. 38
- 39. Data Sources • Spark separates computation and storage. • Complete data pipeline: • External storage feeds data to Spark. • Spark processes the data • Data source can be a bottleneck if Spark processes data very fast. 39
- 40. Scan Vectorization • More efficient to read columnar data with vectorization. • More likely for JVM to generate SIMD instructions. • ……
- 41. Partitioning and Bucketing • A special file system layout for data skipping and pre-shuffle. • Can speed up query a lot by avoid unnecessary IO and shuffle. • The summit talk: http://dbricks.co/2oG6ZBL
- 42. Performance Tips • Pick data sources that supports vectorized reading. (parquet, orc) • For file-based data sources, creating partitioning/bucketing if possible. 42
- 43. 43 Yet challenges still remain Raw Data InsightData Lake Reliability & Performance Problems • Performance degradation at scale for advanced analytics • Stale and unreliable data slows analytic decisions Reliability and Complexity • Data corruption issues and broken pipelines • Complex workarounds - tedious scheduling and multiple jobs/staging tables • Many use cases require updates to existing data - not supported by Spark / Data lakes Big data pipelines / ETL Multiple data sources Batch & streaming data Machine Learning / AI Real-time / streaming analytics (Complex) SQL analytics Streaming magnifies these challenges AnalyticsETL
- 44. 44 Databricks Delta address these challenges Raw Data Insight Big data pipelines / ETL Multiple data sources Batch & streaming data Machine Learning / AI Real-time / streaming analytics (Complex) SQL analytics DATABRICKS DELTA Builds on Cloud Data Lake Reliability & Automation Transactions guarantees eliminates complexity Schema enforcement to ensure clean data Upserts/Updates/Deletes to manage data changes Seamlessly support streaming and batch Performance & Reliability Automatic indexing & caching Fresh data for advanced analytics Automated performance tuning ETL Analytics
- 45. Thank you Xiao Li ([email protected]) Wenchen Fan ([email protected]) 45