Deploying Grid Services Using Hadoop
2 likes610 views

The document summarizes Yahoo!'s use of Hadoop for grid computing. Some key points: - Yahoo! operates multiple Hadoop grids with 10,000s of nodes to support large data processing and storage needs. - Hadoop provides an on-demand, shared resource pool for computation and storage across the company. - Yahoo! uses Hadoop MapReduce for parallel processing of large datasets and the Hadoop Distributed File System for petabytes of data storage. - Additional tools like Hadoop On Demand are used for job scheduling and resource management across the Hadoop clusters.






















Deploying Grid Services Using Hadoop
- 1. Deploying Grid Services Using Hadoop Allen Wittenauer April 11, 2008 Yahoo! @ ApacheCon 1
- 2. Agenda • Grid Computing At Yahoo! • Quick Overview of Hadoop – “Hadoop for Systems Administrators” • Scaling Hadoop Deployments • Yahoo!’s Next Generation Grid Infrastructure • Questions (and maybe even Answers!) Yahoo! @ ApacheCon 2
- 3. Grid Computing at Yahoo! • Drivers – 500M unique users per month – Billions of interesting events per day – “Data analysis is the inner-loop at Yahoo!” • Yahoo! Grid Vision and Focus – On-demand, shared access to vast pool of resources – Support for massively parallel execution (1000s of processors) – Data Intensive Super Computing (DISC) – Centrally provisioned and managed – Service-oriented, elastic • What We’re Not – Not “Grid” in the sense of scientific community (Globus, etc) – Not focused on public or 3rd-party utility (Amazon EC2/S3, etc) Yahoo! @ ApacheCon 3
- 4. Yahoo! Grid Services • Operate multiple grids within Yahoo! • 10,000s nodes, 100,000s cores, TBs RAM, PBs disk • Support large internal user community – Account management, training, etc • Manage data needs – Ingest TBs per day • Deploy and manage software (Hadoop, Pig, etc) Yahoo! @ ApacheCon 4
- 5. “Grid” Computing • What we really do is utility computing – Nobody knows what “utility computing” is, but everyone has heard of “grid computing” • Grid computing implies sharing across resources owned by multiple, independent organizations • Utility computing implies sharing one owner’s resources by multiple, independent customers • Ultimate goal is to provide shared compute and storage resources – Instead of going to a hardware committee to provision balkanized resources, a project allocates a part of its budget for use on Yahoo!’s shared grids – Pay as you go • Only buy 100 computers for 15 minutes of compute time vs. 100 computers 24x7 Yahoo! @ ApacheCon 5
- 6. What is a Yahoo! Grid Service? • Thousands of machines using basic network hardware – It’s hard to program for many machines • Clustering and sharing software – Hadoop, HOD, Torque, Maui, and other bits... • Petabytes of data – It’s an engineering challenge to load so much data from many sources • Attached development environment – A clean, well lit place to interact with a grid • User support – Learning facilitation • Usage tracking and billing – Someone has to pay the bills... Yahoo! @ ApacheCon 6
- 7. Quick MapReduce Overview • Application writer specifies Input 0 Input 1 Input 2 – two functions: Map and Reduce – set of input files • Workflow Map 0 Map 1 Map 2 – input phase generates a number of FileSplits from input files (one per Map Task) Shuffle – Map phase executes user function to transform key/value inputs into new key/value outputs Reduce 0 Reduce 1 – Framework sorts and shuffles – Reduce phase combines all k/v’s with the same key into new k/v’s – Output phase writes the resulting Out 0 Out 1 pairs to files • cat * | grep | sort | uniq -c | cat > out Yahoo! @ ApacheCon 7
- 8. Hadoop MapReduce: Process Level • Job – Map Function + Reduce Function + List of inputs Job Job Tracker Task Task Tracker Tracker Task Task Task Task Yahoo! @ ApacheCon 8
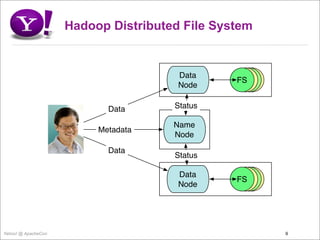
- 9. Hadoop Distributed File System Data FSFS FS FS Node Data Status Name Metadata Node Data Status Data FSFS FS FS Node Yahoo! @ ApacheCon 9
- 11. Gateways: Multi-user Land • Provided for two main purposes – Meaningful development interaction with a compute cluster • High bandwidth, low latency, and few network barriers enable a tight development loop when creating MapReduce jobs – Permission and privilege separation • Limit exposure to sensitive data – Hadoop 0.15 and lower lack users, permissions, etc. – Hadoop 0.16 has users and “weak” permissions • Characteristics – “Replacement” Lab machine – World-writable local disk space • Any single-threaded processing • Code debugging Gateway Yahoo! @ ApacheCon 11
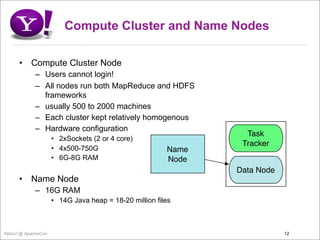
- 12. Compute Cluster and Name Nodes • Compute Cluster Node – Users cannot login! – All nodes run both MapReduce and HDFS frameworks – usually 500 to 2000 machines – Each cluster kept relatively homogenous – Hardware configuration Task • 2xSockets (2 or 4 core) Tracker • 4x500-750G Name • 6G-8G RAM Node Data Node • Name Node – 16G RAM • 14G Java heap = 18-20 million files Yahoo! @ ApacheCon 12
- 13. Queuing and Scheduling • Hadoop does not have an advanced scheduling system – MapReduce JobTracker manages one or more jobs running within a set of machines – Works well for “dedicated” applications, but does not work so well for shared resources • Grid Services are intended to be a shared multi-user, multi-application environment – Need to combine Hadoop with an external queuing and scheduling system... Yahoo! @ ApacheCon 13
- 14. Hadoop On Demand (HoD) Resource • Wrapper around PBS commands Mgmt/Sched – We use freely available Torque and Maui • Big win: virtual private JobTracker clusters maui – Job isolation – Users create clusters of the size they need pbs_server – Submit jobs to their private JT • Big costs: – Lose data locality pbs_mom – Increased complexity – Lose a node for private JobTracker – Single reducer doesn’t free unused nodes • ~ 30% efficiency lost! • Looking at changing Hadoop scheduling – Task scheduling flexibility combined with node elasticity Yahoo! @ ApacheCon 14
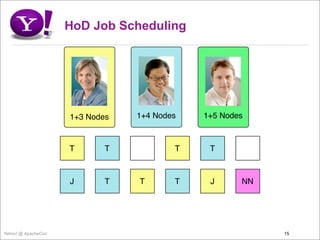
- 15. HoD Job Scheduling 1+3 Nodes 1+4 Nodes 1+5 Nodes T T T T J T T T J NN Yahoo! @ ApacheCon 15
- 16. The Reality of a 1000 Node Grid 200 400 500 10 Yahoo! @ ApacheCon 16
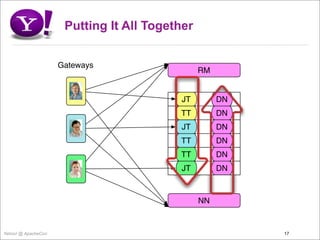
- 17. Putting It All Together Gateways RM JT DN TT DN JT DN TT DN TT DN JT DN NN Yahoo! @ ApacheCon 17
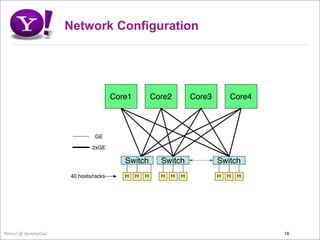
- 18. Network Configuration Core1 Core2 Core3 Core4 GE 2xGE Switch Switch Switch 40 hosts/racks H H H H H H H H H Yahoo! @ ApacheCon 18
- 19. Yahoo!’s Next Generation Grid Infrastructure A Work In Progress 19
- 20. Background Information • Internal deployments – Mostly Yahoo! proprietary technologies • M45 – Educational outreach grid – Non-Yahoo!’s using Yahoo! resources • Legal required us not to use any Y! technology! • Decision made to start from scratch! – Hard to share best practices – Potential legal issues – Don’t want to support two ways to do the same operation • Internal grids converting to be completely OSS as possible – Custom glue code to deal with any Y!<-->OSS incompatibilities • user and group data Yahoo! @ ApacheCon 20
- 21. Naming and Provisioning Services • Naming services – Kerberos for secure authentication – DNS for host resolution – LDAP for everything else • ISC DHCP – Reads table information from LDAP – In pairs for redundancy • Kickstart – We run RHEL 5.x – base image + bcfg2 • bcfg2 – host customization – centralized configuration management Yahoo! @ ApacheCon 21
- 22. NFS for Multi-user Support • NFS – Home Directories – Project Directories • Group shared data • Grids with service level agreements (SLAs) shouldn’t use NFS ! – Single point of failure • HA-NFS == $$$ – Performance – Real data should be in HDFS Yahoo! @ ApacheCon 22
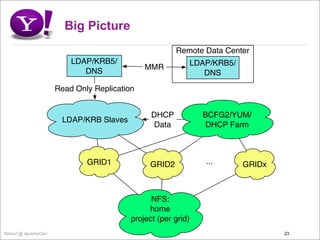
- 23. Big Picture Remote Data Center LDAP/KRB5/ LDAP/KRB5/ MMR DNS DNS Read Only Replication DHCP BCFG2/YUM/ LDAP/KRB Slaves Data DHCP Farm GRID1 GRID2 ... GRIDx NFS: home project (per grid) Yahoo! @ ApacheCon 23
- 24. Self Healing/Reporting • Torque – Use the Torque node health mechanism to disable/fix ‘sick’ nodes • Great reduction in amount of support issues • Address problems in bulk • Nagios – Usual stuff – Custom hooks into Torque • Simon – Yahoo!’s distributed cluster and application monitoring tools – Similar to Ganglia – On the roadmap to be open sourced Yahoo! @ ApacheCon 24
- 25. Node Usage Report Yahoo! @ ApacheCon 25
- 26. Ranges and Groups • Range: group of hosts – example: @GRID == all grid hosts – custom tools to manipulate hosts based upon ranges: • ssh -r @GRID uptime – Report uptime on all of the hosts in @GRID • Netgroup – Used to implement ranges – The most underrated naming service switch ever? • Cascaded! • Scalable! • Supported in lots of useful places! – PAM (e.g., _succeed_if on Linux) – NFS Yahoo! @ ApacheCon 26
- 27. Some Links • Apache Hadoop – http://hadoop.apache.org/ • Yahoo! Hadoop Blog – http://developer.yahoo.com/blogs/hadoop/ • M45 Press Release – http://research.yahoo.com/node/1879 • Hadoop Summit and DISC Slides – http://research.yahoo.com/node/2104 Yahoo! @ ApacheCon 27
- 28. 28