Design Patterns for Large-Scale Real-Time Learning
14 likes4,367 views

The document discusses design patterns for large-scale real-time learning using technologies like Apache Hadoop and HBase. It emphasizes the importance of operational analytics, machine learning models, and the distinction between batch and real-time processing through a Lambda architecture. Key components include model building, serving, and the use of PMML for standardized predictive modeling.




























Design Patterns for Large-Scale Real-Time Learning
- 1. Design Patterns for Large-Scale Real-Time Learning Sean Owen / Director of Data Science / Cloudera 1
- 2. What We Talk About When We Talk About Data Science 2
- 4. 4
- 5. tist 5
- 6. Data Science Is Exploratory Analytics? www.tc.umn.edu/~zief0002/Comparing-Groups/blog.html thenextweb.com/microsoft/2013/07/08/microsoft-brings-the-office-store-to-22-new-markets-adds-power-bi-an-intelligence-tool-to-office-365/ 6
- 7. 7
- 8. Example: • • • • • • Search, ML over Patient Data MapReduce for indexing, learning HBase for storage and fast access Also: Storm for incremental update And: relational DB for most recent derived data API façade for input; API for querying learning Engineering 8 Machine Learning engineering.cerner.com/2013/02/near-real-time-processing-over-hadoop-and-hbase/
- 10. 2014: Lab to Factory 10
- 11. Data Science Will Be Operational Analytics 11
- 12. I Built A Model. Now What? Collect Input Repeat 12 Build Model Query Model
- 13. I Built A Model On Hadoop. Now What? ? Collect Input ? Repeat 13 Build Model ? Query Model
- 14. Example: Oryx 14
- 16. cloudera/ml + 16
- 17. Gaps to fill, and Goals • Model Building • • • • • Model Serving • • 17 Large-scale Continuous Apache Hadoop™-based Few, good algorithms Real-time query Real-time update • Algorithms • • • • Parallelizable Updateable Works on diverse input Interoperable • • • PMML model format Simple REST API Open source
- 18. Large-Scale or Real-Time? Large-Scale Offline Batch vs Real-Time Online Streaming Why Don’t We Have Both? λ! 18
- 19. Lambda Architecture Batch, Stream Processing are different • Tackle separately in 2+ Layers • Batch Layer: offline, asynchronous • Serving / Speed Layer: real-time, incremental, approximate • … λ? jameskinley.tumblr.com/post/37398560534/the-lambda-architecture-principles-for-architecting 19
- 21. Two Layers • Computation Layer • • • • • Java-based server process Client of Hadoop 2.x Periodically builds “generation” from recent data and past model Baby-sits MapReduce* jobs (or, locally in-core) Publishes models • Serving Layer • • • • • • * Apache Spark later 21 Apache Tomcat™-based server process Consumes models from HDFS (or local FS) Serves queries from model in memory Updates from new input Also writes input to HDFS Replicas for scale
- 22. Collaborative Filtering : ALS • • • • • • 22 Alternating Least Squares Latent-factor model Accepts implicit or explicit feedback Real-time update via fold-in of input No cold-start Parallelizable YT X
- 23. Clustering : k-means++ Well-known and understood • Parallelizable • Clusters updateable • cwiki.apache.org/confluence/display/MAHOUT/K-Means+Clustering 23
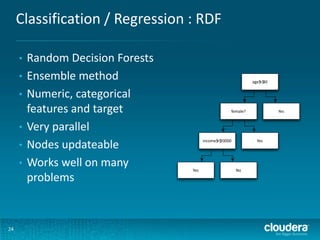
- 24. Classification / Regression : RDF • • • • • • 24 Random Decision Forests Ensemble method Numeric, categorical features and target Very parallel Nodes updateable Works well on many problems age$ 30 >$ female? income$ 20000 >$ Yes Yes Yes No
- 25. PMML Predictive Modeling Markup Language • XML-based format for predictive models • Standardized by Data Mining Group (www.dmg.org) • Wide tool support • <PMML xmlns="http://www.dmg.org/PMML-4_1" version="4.1"> <Header copyright="www.dmg.org"/> <DataDictionary numberOfFields="5"> <DataField name="temperature" optype="continuous" dataType="double"/> … </DataDictionary> <TreeModel modelName="golfing" functionName="classification"> <MiningSchema> <MiningField name="temperature"/> … </MiningSchema> <Node score="will play"> <Node score="will play"> <SimplePredicate field="outlook" operator="equal" value="sunny"/> … </Node> </Node> </TreeModel> </PMML> www.dmg.org/v4-1/TreeModel.html 25
- 26. HTTP REST API • • • • • 26 Convention for RPC-like request / response HTTP verbs, transport GET : query POST : add input Easy from browser, CLI, Java, Python, Scala, etc. GET /recommend/jwills HTTP/1.1 200 OK Content-Type: text/plain "Ray LaMontagne",0.951 "Fleet Foxes",0.7905 "The National",0.688 "Shearwater",0.3017
- 27. Wish List • Revamp workflow • • • De-emphasize model building • • • Well-solved Bring your own Emphasize integration • 27 Oozie? Spark / Crunch-like API, not raw M/R PMML, etc. More component-ized • Less black-box service • More “push” options • • • Flume? “Pull” options • • Kafka? Hive / Impala ?
- 28. Open Source github.com/cloudera/oryx 100% Apache License 2.0 28