Design Patterns for working with Fast Data
Download as PPTX, PDF3 likes1,570 views

The document provides an introduction to Apache Kafka, explaining its capabilities as a distributed messaging system designed for fast data processing and storage. It covers various aspects of Kafka, including message delivery, partitioning, consumer groups, and performance factors, while offering code examples and demonstrations of its API. Key strategies for maximizing throughput are emphasized to help users effectively utilize Kafka in their applications.





































![© 2016 MapR Technologies 40© 2016 MapR Technologies 40
Option C?
• Create a POJO “Tick”
with a single byte[]
attribute, and getters
that return fields by
directly indexing the
byte[]
• Annotate getters with
@JsonProperty](https://image.slidesharecdn.com/pjugkafka-shareable-161020194517/85/Design-Patterns-for-working-with-Fast-Data-40-320.jpg)











![© 2016 MapR Technologies 52© 2016 MapR Technologies 52
Performance Anti-Pattern
• I want to stream JSON strings to simplify DB persistence and
columnar selections in Spark.
• Fine, I’ll just convert every message to a JSON object at the first step
of my pipeline and use a JSON serializer.
– Lesson learned: parsing is expensive! Handling parsing errors is expensive.
Custom serializers are not as easy I as thought.
– This anti-pattern is illustrated here: https://github.com/mapr-demos/finserv-ticks-
demo/commit/35a0ddaad411bf7cec34919a4817482df2bf6462
– Solution: Stream a data structure containing a byte[] to hold raw data, and
annotate it with com.fasterxml.jackson.annotation.JsonProperty.
– Example: https://github.com/mapr-demos/finserv-ticks-
demo/blob/35a0ddaad411bf7cec34919a4817482df2bf6462/src/main/java/com/mapr/demo/finserv/Tick2.java](https://image.slidesharecdn.com/pjugkafka-shareable-161020194517/85/Design-Patterns-for-working-with-Fast-Data-52-320.jpg)












Design Patterns for working with Fast Data
- 1. © 2016 MapR Technologies 1© 2016 MapR Technologies 1© 2016 MapR Technologies Design Patterns for working with Fast Data
- 2. © 2016 MapR Technologies 2© 2016 MapR Technologies 2 Abstract • This presentation provides an introduction to Apache Kafka, describes how to use the Kafka API, and illustrates strategies for maximizing the throughput of Kafka pipelines to accommodate fast data. • The code examples used during this talk are available at github.com/iandow/design-patterns-for-fast-data.
- 3. © 2016 MapR Technologies 3© 2016 MapR Technologies 3 • Ian Downard is a technical evangelist for MapR where he is focused on creating developer-friendly ways to use the MapR Converged Data Platform. • Personal Blog: http://www.bigendiandata.com • Twitter: https://twitter.com/iandownard • GitHub: https://github.com/iandow • LinkedIn: https://www.linkedin.com/in/iandownard Author
- 4. © 2016 MapR Technologies 4© 2016 MapR Technologies 4 What is Kafka? • A distributed publish-subscribe messaging system. • Persists on disk (not “in-memory”). • Supports true streaming (not just fast batching). • Can be used for data storage AND data processing (not just storage) • Oriented around small messages and dynamic data sets (i.e. “streams”).
- 5. © 2016 MapR Technologies 5© 2016 MapR Technologies 5 Service A Service B Service C Logs Service 1 Service 2 Service 3 n Producers m Consumers How many connections?
- 6. © 2016 MapR Technologies 6© 2016 MapR Technologies 6 Service A Service B Service C Logs Service 1 Service 2 Service 3 n Producers m Consumers How many connections?
- 7. © 2016 MapR Technologies 7© 2016 MapR Technologies 7 • Elastic, fault tolerant, and low latency. – Fits well into microservice architectures. • Low CapEx message bus for Big Data. • Supports both real-time processing and short-term storage. • Kafka is becoming the default for inter-service communication. Kafka Strengths
- 8. © 2016 MapR Technologies 8© 2016 MapR Technologies 8 Who is streaming data? • Retail: orders, sales, shipments, price adjustments • Financial Services: stock prices, credit card fraud • Web sites: clicks, impressions, searches, web click fraud • Operating Systems: machine metrics, and logs
- 9. © 2016 MapR Technologies 9© 2016 MapR Technologies 9 Some examples of streaming datasets • Social Media – https://dev.twitter.com/streaming/overview • IoT – Lots of examples at https://data.sparkfun.com/streams/ – http://dweet.io is pretty cool • Servers: – /var/log/syslog – tcpdump • Banking – Yahoo Finance API: https://github.com/cjmatta/TwitterStream, http://meumobi.github.io/stocks%20apis/2016/03/13/get-realtime-stock-quotes- yahoo-finance-api.html – NYSE markets: http://www.nyxdata.com/Data-Products/Daily-TAQ • Other – screen scrape anything
- 10. © 2016 MapR Technologies 10© 2016 MapR Technologies 10
- 11. © 2016 MapR Technologies 11© 2016 MapR Technologies 11 “Text mining is the application of natural language processing techniques and analytical methods to text data in order to derive relevant information.” http://adilmoujahid.com/posts/2014/07/twitter-analytics/
- 12. © 2016 MapR Technologies 12© 2016 MapR Technologies 12 https://heroku.github.io/kafka-demo/
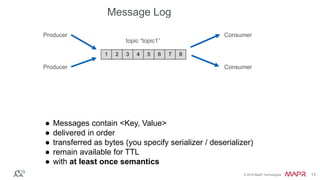
- 13. © 2016 MapR Technologies 13© 2016 MapR Technologies 13 ● Messages contain <Key, Value> ● delivered in order ● transferred as bytes (you specify serializer / deserializer) ● remain available for TTL ● with at least once semantics 1 2 3 4 5 6 7 8 topic “topic1” ConsumerProducer ConsumerProducer Message Log
- 14. © 2016 MapR Technologies 14© 2016 MapR Technologies 14 ● Producers send messages one at a time ● Consumers subscribe to topics, poll for messages, and receive records many at a time “topic1” ConsumerProducer ConsumerProducer 1 2 3 4 5 6 7 8 Message Log
- 15. © 2016 MapR Technologies 15© 2016 MapR Technologies 15 ● Producer sees a topic as one logic object. ● The order of messages within a single partition is guaranteed 1 2 3 4 “topic1”, partition 1 Producer 1 2 3 4 “topic1”, partition 2 Partitioning
- 16. © 2016 MapR Technologies 16© 2016 MapR Technologies 16 ● A single partition can only be read by one consumer. ● Partitioning facilitates concurrent consumers. ● New consumers are automatically assigned a partition. Producer Load balanced Consumer(s) 1 2 3 4 1 2 3 4 “topic1”, partition 1 “topic1”, partition 2 Partitioning
- 17. © 2016 MapR Technologies 17© 2016 MapR Technologies 17 ● Calling commit marks where a consumer has finished processing. 1 2 3 4 5 6 7 8 “topic1”, partition 1 Consumer commit (p1, o6) Commit
- 18. © 2016 MapR Technologies 18© 2016 MapR Technologies 18 ● Thanks to commit, when a consumer crashes, we let it. 1 2 3 4 5 6 7 8 “topic1”, partition 1 Consumer Commit
- 19. © 2016 MapR Technologies 19© 2016 MapR Technologies 19 ● When another consumer takes its place, it continues where the old consumer left off. 1 2 3 4 5 6 7 8 “topic1”, partition 1 New Consumer Commit cursor
- 20. © 2016 MapR Technologies 20© 2016 MapR Technologies 20 Kafka depends on Zookeeper • Leader election – each partition has a leader • Cluster membership – broker up/down status • Topic Configurations – topic names, partitions, replicas, TTLs…
- 21. © 2016 MapR Technologies 21© 2016 MapR Technologies 21 DEMO: Kafka CLI • Create, alter, pub/sub, and delete topic. • See where topics are saved.
- 22. © 2016 MapR Technologies 22© 2016 MapR Technologies 22 DEMO: Java API • Basic producer/consumer example
- 23. © 2016 MapR Technologies 23© 2016 MapR Technologies 23 DEMO: Heroku Kafka-as-a-Service • Demo app: – https://github.com/iandow/heroku-kafka-demo-java • Docs and Pricing: – https://devcenter.heroku.com/articles/kafka-on-heroku – $1,500/month !!! – Oh, but rounding credits.
- 24. © 2016 MapR Technologies 24© 2016 MapR Technologies 24 DEMO: Kafka in a web app • How to send a message – How to ensure delivery guarantee – How to handle failure • Demonstrate it: – Change 20 second timeout in DemoResources.java – Observe the java.util.concurrent.Timeout in the user specified callback – Also observe that the message may ultimately get there, (if its in transit) • To get rid of Dropwizard metrics, change timeout in DemoApplication.java – reporter.start(1, TimeUnit.MINUTES);
- 25. © 2016 MapR Technologies 25© 2016 MapR Technologies 25© 2016 MapR Technologies© 2016 MapR Technologies Consumer Groups, Cursors, and Partitions
- 26. © 2016 MapR Technologies 26© 2016 MapR Technologies 26 ProducerRecord vs ConsumerRecord • Producers send messages one at a time as ProducerRecord • Consumers subscribe to topics and poll for messages and receive them many-at-a-time as ConsumerRecords
- 27. © 2016 MapR Technologies 27© 2016 MapR Technologies 27 Consumer Groups, Cursors, and Partitions • Consumer Groups – groups of consumers working together • Cursors – track positions of consumers • Partitions – subdivide a topic for scale • Replication Factor – replicate partitions across nodes for fault tolerance
- 28. © 2016 MapR Technologies 28© 2016 MapR Technologies 28 Partition Balancing • Available partitions are balanced among consumers for a given group – Single partition can be read by only one consumer – A single consumer can read multiple partitions – Examples: • 3 partitions, 2 consumers: 2 & 1 • 5 partitions, 1 consumer: 5 • 3 partitions, 4 consumers: 1, 1, 1, 0 (4th consumer gets no messages) • When new consumers join or new partitions added, rebalance occurs – Some consumers will gain or lose partitions and there may be a slight pause in message delivery while this happens – Can cause duplicates if consumers don’t properly commit cursors
- 29. © 2016 MapR Technologies 29© 2016 MapR Technologies 29 Consumer Groups • Only one consumer IN A GROUP can consume one topic/partition simultaneously • Consumers in different groups will see the same messages if they read the same topic/partition http://kafka.apache.org/documentation.html
- 30. © 2016 MapR Technologies 30© 2016 MapR Technologies 30 Cursor Persistence • Ensure consumers pick up from where they left off after a stop • Tracks last known commit point for message reads • By default, auto commit after 5s (auto.commit.interval.ms) – If slow consumer code, auto commit() might go out before processed – You can explicitly commit with consumer.commit() • If you need to concurrent consumers, would you use consumer groups or topic partitions? 8 7 6 5 4 3 2 1 topic “topic1” Consumer Group A Consumer Group B Cursor A Cursor B
- 31. © 2016 MapR Technologies 31© 2016 MapR Technologies 31 At Least Once semantics • Messages may be seen multiple times – Producer side • Retransmit on network • Producer might fail and resend previously sent messages on restart – Consumer side • Client might crash after get but before cursor.commit() • Applications must be idempotent message processors
- 32. © 2016 MapR Technologies 32© 2016 MapR Technologies 32 Batching Behavior • Producer.send() places messages in client-side memory buffer • That buffer is not flushed until one of three criteria met: – Timeout (linger.ms) – Max memory (buffer.memory) – Producer.flush() called
- 33. © 2016 MapR Technologies 33© 2016 MapR Technologies 33 Serialization • Each Kafka message is a byte array. • You must convert <K,V> to/from bytes with a serializer • Two provided out of the box – ByteArraySerializer/ByteArrayDeserializer – StringSerializer/StringDeserializer • You can write your own serializer.
- 34. © 2016 MapR Technologies 34© 2016 MapR Technologies 34 Key Concept - Serialization • If you’re streaming data that is a byte array, use the byte array serializer. • If you’re streaming data that is a String, use the String serializer. • If you’re streaming data that is a POJO, use ???
- 35. © 2016 MapR Technologies 35© 2016 MapR Technologies 35 How to stream a POJO 1. Make it serializable – Otherwise you’ll get a java.io.NotSerializableException later when we write the object to a byte array 2. Write the object to a byte array 3. Send that byte array – Why can’t we just send the Person object? 4. In the consumer, poll the topic, then convert record.value() to your POJO.
- 36. © 2016 MapR Technologies 36© 2016 MapR Technologies 36 Problems with streaming POJOs • What if your raw data is dirty, and casting fails because you streamed a record with missing POJO fields? • The overhead of encoding/decoding a POJO to/from bytes is redundant, especially if this is done at multiple stages in the Kafka pipeline. • It’s better to postpone parsing/casting downstream.
- 37. © 2016 MapR Technologies 37© 2016 MapR Technologies 37 How would you stream this? 080449201DAA T 00000195700000103000N0000000000000004CT1000100710071007 080449201DAA T 00000131000000107000N0000000000000005CT10031007 080449201DAA T 00000066600000089600N0000000000000006CT10041005 080449201DAA T 00000180200000105100N0000000000000007CT100310051009 080449201DAA T 00000132200000089700N0000000000000008CT100410051005 080449201DAA T 00000093500000089400N0000000000000009CT10031007 080449201DAA T 00000075100000105400N0000000000000010CT100410081006 080449201DAA T 00000031300000088700N0000000000000011CT1004100810081007 080449201DAA T 00000021800000105100N0000000000000012CT100410091005 080449201DAA T 00000191300000104500N0000000000000013CT10041006 080449201DAA T 00000124500000105100N0000000000000014CT1001100610071008
- 38. © 2016 MapR Technologies 38© 2016 MapR Technologies 38 Option A? • Parse each record into a JSON object, • Publish json_object.toString() • Stream with with String serializer
- 39. © 2016 MapR Technologies 39© 2016 MapR Technologies 39 Option B? • Create a POJO (“Tick”) with attributes for each field • Parse each record and create a Tick object • Stream Tick objects using a custom serializer
- 40. © 2016 MapR Technologies 40© 2016 MapR Technologies 40 Option C? • Create a POJO “Tick” with a single byte[] attribute, and getters that return fields by directly indexing the byte[] • Annotate getters with @JsonProperty
- 41. © 2016 MapR Technologies 41© 2016 MapR Technologies 41 A B C
- 42. © 2016 MapR Technologies 42© 2016 MapR Technologies 42 Major Performance Factors • Replication turned on? • Streaming large messages? • Producers sending synchronously or async.? • Send buffer flushed until one of three criteria met: – Timeout (linger.ms) – Max memory (buffer.memory) – Producer.flush() called • Topics / Producer affinity
- 43. © 2016 MapR Technologies 43© 2016 MapR Technologies 43 • What affects producer latency? – Using send futures? (i.e. synchronous sends) – acks=all,1,or 0 (ack after leader logs / after all replicas log / or not at all) – ”Nagle’s algorithm” and the linger.ms config • What affects producer throughput? – Producer batch.size – Concurrent producer.send() – Number of topics – Message size • What affects consumer throughput? – Partitions Major Performance Factors
- 44. © 2016 MapR Technologies 44© 2016 MapR Technologies 44 Major Performance Factors • What affects Kafka server stability? – Garbage Collection: Long GCs from sending large messages can break the kafka/zookeeper connection. – Topics can easily consume disk space – May need to increase file handles • Topic data and index files are in log.dir (e.g. /tmp/kafka-logs) • Kafka keeps an open file for each topic. – Reference: http://www.michael-noll.com/blog/2013/03/13/running-a-multi-broker-apache-kafka-cluster-on-a-single-node/
- 45. © 2016 MapR Technologies 45© 2016 MapR Technologies 45 Read vs Processing Parallelism • Consumer read parallelism – Concurrent reads can be achieved via topic partitioning and consumer groups – If your consumer logic is CPU-bound, use partitions or consumer groups • Downstream Processing Parallelism – If you need more processing threads than read threads, then “fan-out” the data to more topics.
- 46. © 2016 MapR Technologies 46© 2016 MapR Technologies 46 What I mean by, “Fan-out”: vv SQL 15 min. roll Intra-day Trades Ingest trades archived trades Microservice Index by sender/receiver Tick stream Microservice STREAMING https://www.mapr.com/appblueprint/overview
- 47. © 2016 MapR Technologies 47© 2016 MapR Technologies 47 Performance Anti-Pattern • Problem: I want to count all the messages read in each consumer thread. • Anti-pattern: I’ll just increment a counter in a synchronized block.
- 48. © 2016 MapR Technologies 48© 2016 MapR Technologies 48 Performance Anti-Pattern • I want to count all the messages read in each consumer thread. • Fine, I’ll just increment a counter in a synchronized block. – Lesson learned: synchronization really hurts throughput. – Solution: I decreased the cost of metric collection to near zero by giving each thread its own metrics structure, and every second or so, updating a shared metric structure with locks.
- 49. © 2016 MapR Technologies 49© 2016 MapR Technologies 49 Performance Anti-Pattern • I want to be sure never to read a duplicate message. • Fine, I’ll just commit the read point for every message I consume.
- 50. © 2016 MapR Technologies 50© 2016 MapR Technologies 50 Performance Anti-Pattern • I want to be sure never to read a duplicate message. • Fine, I’ll just commit the read point for every message I consume. – Lesson learned, you’re still not guaranteed not to get a duplicate message. Kafka consumers must be idempotent. – Solution: Postpone deduplication downstream. (i.e. Give up till’ later.)
- 51. © 2016 MapR Technologies 51© 2016 MapR Technologies 51 Performance Anti-Pattern • I want to stream JSON strings to simplify DB persistence and columnar selections in Spark. • Fine, I’ll just convert every message to a JSON object at the first step of my pipeline and use a JSON serializer.
- 52. © 2016 MapR Technologies 52© 2016 MapR Technologies 52 Performance Anti-Pattern • I want to stream JSON strings to simplify DB persistence and columnar selections in Spark. • Fine, I’ll just convert every message to a JSON object at the first step of my pipeline and use a JSON serializer. – Lesson learned: parsing is expensive! Handling parsing errors is expensive. Custom serializers are not as easy I as thought. – This anti-pattern is illustrated here: https://github.com/mapr-demos/finserv-ticks- demo/commit/35a0ddaad411bf7cec34919a4817482df2bf6462 – Solution: Stream a data structure containing a byte[] to hold raw data, and annotate it with com.fasterxml.jackson.annotation.JsonProperty. – Example: https://github.com/mapr-demos/finserv-ticks- demo/blob/35a0ddaad411bf7cec34919a4817482df2bf6462/src/main/java/com/mapr/demo/finserv/Tick2.java
- 53. © 2016 MapR Technologies 53© 2016 MapR Technologies 53 Good Practices • Design your data structures to prefer arrays of objects, and primitive types, instead of the standard Java or Scala collection classes (e.g. HashMap). • Maintain affinity between topic and producer thread. – Kafka will batch multiple sends together. If a send hits only one topic, it will benefit from writes to sequential memory locations. – Reference code: https://github.com/mapr-demos/finserv-application- blueprint/blob/master/src/test/java/com/mapr/demo/finserv/ThreadCountS peedIT.java • Consider using numeric IDs or enumeration objects instead of strings for keys.
- 54. © 2016 MapR Technologies 54© 2016 MapR Technologies 54 Three Performance Takeaways 1. Process as little as possible in the pipeline. – Transfer byte arrays. It’s faster than serializers based on strings, POJOs, or custom serialization. 2. Use JSON annotation. It makes persistence easier in the final stages. It also makes data analysis easier because it gives you an easy schema. 3. Categorize raw data into multiple topics (aka “fan-out”). It makes real-time analysis easier. 4. Use parameterized tests in Junit to tune Kafka.
- 55. © 2016 MapR Technologies 55© 2016 MapR Technologies 55 DEMO: Tuning Kafka with Junit https://github.com/iandow/kafka_junit_tests
- 56. © 2016 MapR Technologies 56© 2016 MapR Technologies 56 How to create Junit parameterized tests 1. Annotate test class with @RunWith(Parameterized.class). 2. Create a public static method annotated with @Parameters that returns a Collection of Objects (as Array) as test data set. 3. Create a public constructor that takes in one "row" of test data.
- 57. © 2016 MapR Technologies 57© 2016 MapR Technologies 57 Benchmarks • Lazy benchmark, by Jay Kreps at LinkedIn (2014): – https://engineering.linkedin.com/kafka/benchmarking-apache-kafka-2- million-writes-second-three-cheap-machines • Answers questions like these: – Will Kafka slow down if I never consumer messages? – Should I stream small messages or large messages (in order to maximize Throughput)? – Should I stream small messages or large messages?
- 58. © 2016 MapR Technologies 58© 2016 MapR Technologies 58 Kafka MapR Streams Complies with standard Kafka API ✓ ✓ Scale to 1000s of topics ✗ ✓ Automatically span large partitions across cluster nodes ✗ ✓ Failover consumers & producers across mirrored clusters ✗ ✓ Real-time cluster replication across data centers ✗ ✓ Kafka vs MapR Streams
- 59. © 2016 MapR Technologies 59© 2016 MapR Technologies 59 • Inherits efficient I/O patterns from MapR-FS, allowing topics to save much more data and replicate much faster • Load balances topics and partitions more effectively • Span topics across clusters in multi-datacenters and synchronize offsets across clusters • Inherits efficient I/O patterns from the core MapR platform MapR Streams is a more scalable Kafka
- 60. © 2016 MapR Technologies 60© 2016 MapR Technologies 60 Blueprint of a Converged Application for real-time tick streaming vv SQL 15 min. roll Intra-day Trades Ingest trades archived trades Microservice Index by sender/receiver Tick stream Microservice STREAMING https://www.mapr.com/appblueprint/overview
- 61. © 2016 MapR Technologies 61© 2016 MapR Technologies 61 Open Source Engines & Tools Commercial Engines & Applications Enterprise-Grade Platform Services DataProcessing Web-Scale Storage MapR-FS MapR-DB Search and Others Real Time Unified Security Multi-tenancy Disaster Recovery Global NamespaceHigh Availability MapR Streams Cloud and Managed Services Search and Others UnifiedManagementandMonitoring Search and Others Event StreamingDatabase Custom Apps HDFS API POSIX, NFS HBase API JSON API Kafka API MapR Converged Data Platform
- 62. © 2016 MapR Technologies 62© 2016 MapR Technologies 62 • Read about Kafka and Spark Streaming • https://www.mapr.com/blog/real-time-streaming-data-pipelines- apache-apis-kafka-spark-streaming-and-hbase • Read the Streaming Architecture ebook • https://www.mapr.com/streaming-architecture-using-apache-kafka- mapr-streams • Check out this presentation and demo code • https://github.com/iandow/design-patterns-for-fast-data Next Steps:
- 63. © 2016 MapR Technologies 63© 2016 MapR Technologies 63 Free training http://learn.mapr.com
- 64. © 2016 MapR Technologies 64© 2016 MapR Technologies 64 Q&A @mapr @iandownard Engage with us! mapr-technologies
Editor's Notes
- #3: This presentation provides an introduction to Apache Kafka, describes how to use the Kafka API, and illustrates strategies for maximizing the throughput of Kafka pipelines to accommodate fast data. The code examples used during this talk are available at github.com/iandow/design-patterns-for-fast-data.
- #5: originally developed at LinkedIn and became an Apache project in July, 2011.
- #6: N*M links If one of those services restarts, you have to recover a lot of connections. ad-hoc data pipelines are… hard to scale and manage as the systems that use them also scale
- #7: N+M links Kafka as a universal message bus Transports messages Provides a streaming api whereby apps can pub/sub topics but also create new derived topics which can feed other apps You might look at this and say that’s a single point of failure. but kafka is highly distributed and scalable.
- #8: Decoupling is one of the most important things that make microservices scalable.
- #9: What can you do with streaming data? Text Mining: Train a SPAM filter with every email Detect anomalies through processing of logs and monitoring data, and take corrective action ASAP. detect mechanical part failures, samsung phone example
- #14: They call a topic a “log” (basically a distributed message bus). Default retention period = 7 days.
- #20: When a consumer goes down, we let it.
- #21: Kafka uses Zookeeper which is good at managing cluster related stuff, like who’s the leader for each topic? which brokers are alive (and when have they failed)? which topics exist, and how are they configured (partitions, ttl, replica, etc) No need for Kafka to reinvent it. This is why we can’t just remove the kafka log.dir to purge data. Also have to remove zookeeper data.dir.
- #22: DEMO WORKFLOW: cd ~/development/kafka_2.11-0.10.0.1/ bin/kafka-topics.sh --zookeeper ubuntu:2181 --list bin/kafka-topics.sh --create --zookeeper ubuntu:2181 --replication-factor 1 --partitions 1 --topic test --config retention.ms=10000 bin/kafka-topics.sh --describe --zookeeper ubuntu:2181 --topic test bin/kafka-topics.sh --zookeeper ubuntu:2181 --alter --topic test --config retention.ms=600000 What’s the default TTL? What’s the default log.dir? bin/kafka-console-producer.sh --broker-list ubuntu:9092 --topic test bin/kafka-console-consumer.sh --zookeeper ubuntu:2181 --topic test --from-beginning Pipe tcpdump to the producer. bin/kafka-topics.sh --delete --zookeeper ubuntu:2181 --topic test
- #23: DEMO WORKFLOW: Open kafka_intro project in Intellij Open terminal in Intellij Git checkout initial Go thru BasicConsumer, then BasicProducer
- #24: DEMO WORKFLOW Open ~/development/heroku-kafka-demo-java/ in IntelliJ Double check the KAFKA_URL env variable in the Run config. Then run, or type this: java $JAVA_OPTS -cp target/classes:target/dependency/* com.heroku.kafka.demo.DemoApplication server config.yml Then open http://localhost:8081 Then on the ubuntu kafka server, run this: while true; do fortune | bin/kafka-console-producer.sh --broker-list localhost:9092 --topic mytest; done index.js calls http://localhost:8081/api/messages DemoResource.java is the controller for those GETs Note, this example sets consumer/producer properties differently than other examples.
- #32: Kafka producer property to disable retries is simply ‘retries’ retries - # of retries before giving up. Setting to 0 prevent duplicate sends consumer side at the risk of possible message loss. Can we control?
- #33: linger.ms – how long messages are buffered once the last send was acknowledged by the server. 0 is default (no wait). block.on.buffer.full - default is true but if false kafka will raise an exception warning the client that messages aren’t being sent fast enough: acks - number of servers required to ack of the current in sync set.
- #36: If you skip converting Person to bytes, you’ll get a SerializationException when Kafka tries to convert it to bytes using whatever serializer you specified (unless you wrote a custom serializer). DEMO WORKFLOW: Open kafka-study project. 1. compile: mvn package 2. Right click on the consumer class and say run java -cp target/:target/kafka-study-1.0-jar-with-dependencies.jar com.mapr.demo.finserv.PersonConsumer 3. run a CLI producer to see the streamed bytes ~/development/kafka_2.11-0.10.0.1/bin/kafka-console-consumer.sh --zookeeper ubuntu:2181 --topic persons --from-beginning 4. Right click on the producer class and say run java -cp target/:target/kafka-study-1.0-jar-with-dependencies.jar com.mapr.demo.finserv.PersonProducer
- #38: Knowing that one of your consumers will want to access various fields.
- #39: Easy field access downstream (easy for the developer). But, creates lots of objects, and objects are most costly than native types. Calls substring A LOT! Calls json.toString A LOT!
- #40: Parsing is expensive. Creates lots of objects, and objects are most costly than native types Creates lots of strings with potentially inefficient memory locations
- #41: Gives us the convenience of easy field access, easy JSON object creation, and fast lookup into a byte[], and we can push parsing way downstream. Keeping our data in one large array has the best possible locality, all the data is on one area of memory, cache-thrashing will be kept to a minimum.
- #47: This is a fanout example. Another good example: https://heroku.github.io/kafka-demo/images/kafka-diagram.html
- #53: It was much faster for us to ingest raw data into a byte array primitive type, and stream that using the ByteArray serializers, and only parse it to JSON as the last step in our pipeline.
- #56: DEMO WORKFLOW:
- #57: https://github.com/junit-team/junit4/wiki/parameterized-tests
- #60: Kafka, “More Clusters, More Problems” https://www.mapr.com/blog/scaling-kafka-common-challenges-solved -no global namespace -unsynchronized offsets across clusters)
- #62: All the components you need to build streaming big data applications can run on the same cluster using the MapR converged data platform. MCDP combines Hadoop, Kafka, Spark, nosql data stores, DFS in one cluster. This is much preferred over creating different silos for each app. Adhoc clusters are much harder to secure, much harder to move data between, much harder to admin.
- #63: You can read an explanation of the example code and find a download like for the code in these 2 blogs.
- #64: There is free on demand training , spark , hbase , mapr streams and more at learn.mapr.com