



































DevOps - Chaos Engineering on Kubernetes
- 1. Chaos Engineering on Kubernetes DAVID HSU
- 2. What is Chaos Engineering
- 3. - The story starts at Netflix - Chaos as daily basis - Build confidence - Identify weak points in a system - Break things on purpose What is Chaos Engineering
- 4. What is Chaos Engineering
- 5. - The network is reliable / 網絡是可靠的 - Latency is zero / 延遲是0 - Bandwidth is infinite / 帶寬是無限的 - The network is secure / 網絡是安全的 - Topology doesn't change / 拓墣結構不會變 - There is one administrator / 存在管理員的⾓⾊ - Transport cost is zero / 傳輸成本是0 - The network is homogeneous / 網絡是同質的 Fallacies of Distributed Computing
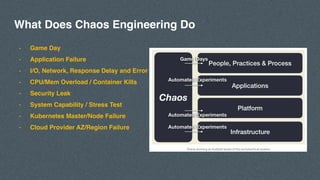
- 6. - Game Day - Application Failure - I/O, Network, Response Delay and Error - CPU/Mem Overload / Container Kills - Security Leak - System Capability / Stress Test - Kubernetes Master/Node Failure - Cloud Provider AZ/Region Failure What Does Chaos Engineering Do
- 7. Why Do We Need Chaos
- 8. Incidents Always happened in Anytime
- 9. - What if Gateway failed while traffic coming? - What if Service Discovery failed? - What if Redis/Aurora failed or started a failover? - What if the Kafka failed? - What if any of the Core Service failed? - What if Grafana/Prometheus/Victoria-Metrics failed? What’ll we do? And What’ll happen? Have You Ever Thought About…?
- 10. - CPU/MEM overload based auto-scaling - Rate Limiting - ECS Tasks auto-recovery / EKS Pods auto-recovery - Redis/Aurora/RDS/Kafka auto-failover - Monitoring and Alerting system But, How much do you know? Yes, You Might Have...
- 11. We actually know nothing about our system without any practice and testing. And Practice makes Perfect, this is why we need to implement Chaos Engineering. It’s not only to practice our systems but also to practice our confidence and flows. Why
- 12. IMPLEMENTATION
- 13. Where to Start 1 2 3 4
- 14. Phases
- 15. - An experiment should start and end with Steady-State - It’s to ensure the experiment won’t be affected by other unexpected events Example: - If we’re going to terminate Pods of a Deployment on K8S, we have to ensure the Deployment is fully healthy before we start. Otherwise, the experiment is pointless because you won’t be able to evaluate the result by running this experiment. - After executed the experiment, we always expect the Deployment will back to “Steady-State”, which means this Deployment passed the experiment, and vice versa. Steady State Steady State Action Executed Steady State
- 16. - What if Gateway fails? - What if website latency increases by 300ms? - What if Kubernetes cluster fails? - What if Aurora/Redis failover? - What if …? All of those questions don’t have a right answer! Hypothesis
- 17. - Do not run experiments in PROD at the beginning - Minimize blast radius and learning from small - Notify everyone before execution - Have a “STOP” button of experiments - Have a “RollBack” Plan Run Experiment
- 18. - Does the experiment success or failed? WHY? - Does the monitoring and alerting system detect the failures? - Are there any other services also affected by this experiment? Verify
- 19. - How do we enhance the ability of resilient? - Documents - What did “your team” learn? - It’s all about building confidence, blameless! Don’t use real outage to learn, instead of running chaos regularly. Improve
- 20. - Steady State / 穩定態定義 - Creating a Hypothesis / 假設理論 - Run Experiment / 運⾏實驗 - Verify and Learn/ 驗證並學習 - Improve / 改善並修復 How Do We Plan Normal Steady State Action Executed Normal Steady State Rollback Learning Not In Steady State FAILED Learning
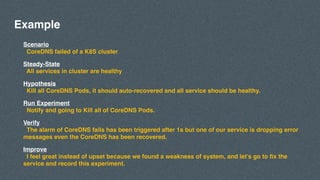
- 21. Scenario CoreDNS failed of a K8S cluster Steady-State All services in cluster are healthy Hypothesis Kill all CoreDNS Pods, it should auto-recovered and all service should be healthy. Run Experiment Notify and going to Kill all of CoreDNS Pods. Verify The alarm of CoreDNS fails has been triggered after 1s but one of our service is dropping error messages even the CoreDNS has been recovered. Improve I feel great instead of upset because we found a weakness of system, and let’s go to fix the service and record this experiment. Example
- 22. TOOL
- 23. - Kubernetes compatible - Extensible - Observable - Able to simulate - Network delay - Pod failure - Node failure - ...etc Requirements
- 24. Implementation of Netflix's Chaos Monkey for Kubernetes - Deploy: kube-monkey has a Pod to inject experiments to target Pods who set specific labels. - Types: Only Pod Kills. - Configuration: Schedule can be set https://github.com/asobti/kube-monkey Chaos Monkey (kube-monkey)
- 25. Alibaba open source experimental injection tool - Deploy: Kubernetes CRD and command line - Types: Multiple - Configuration: CRD and Yaml https://github.com/chaosblade-io/chaosblade ChaosBlade
- 26. https://aws.amazon.com/fis AWS Fault Injection Simulator (FIS)
- 27. https://github.com/chaos-mesh/chaos-mesh Chaos Mesh - Kubernetes
- 28. Gremlin (SaaS)
- 29. https://github.com/chaostoolkit/chaostoolkit-kubernetes Chaos Toolkit - kubernetes
- 30. Chaos Toolkit - kubernetes Steady State Action Executed Steady State SUCCESS Learning Not In Steady State FAILED Learning
- 31. CRD Customized Service Account and Security Context Fetch Experiment JSON from ConfigMap K8S CronJob to Run Experiment
- 32. Check Steady State Hypothesis Method Executes Check Steady State Hypothesis Experiment
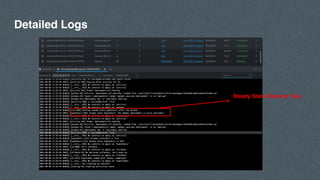
- 33. Detailed Logs Steady State Check is True
- 34. Production
- 35. ECS
- 36. ASG
- 37. PROS AND CONS Pros Cons - CRD/CRO and JSON is really handy. - All basic experiments almost support by native such as -- kill pod/node, network delay. - Use K8S CronJob to run experiments. - Documents are so much incompleted, which cost lots of time to explore and test on our own. - Notification and Report are weak. - No UI or Web console. - The method of Emergency STOP is to kill the CRO, which not easy to operate on PROD.
- 38. Principles
- 39. - Chaos engineering is not about breaking things in production only — it's a journey and it’s about confidence. - Before injecting failure, remember that it is essential to have an excellent monitoring and alerting program in place. - Minimize blast radius and learning from small. - Not just about Infrastructure, or even just the Technical. - No Lucky Principles
- 40. You don’t choose the moment, the moment chooses you. You only choose how prepared you are when it does. 不是你選擇那⼀刻,⽽是那⼀刻選擇你。⽽你唯⼀ 的選擇就是隨時做好準備。
- 41. Thanks