Dictionary Based Annotation at Scale with Spark by Sujit Pal
Download as PPTX, PDF7 likes3,912 views

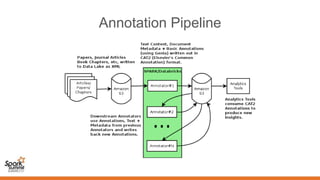
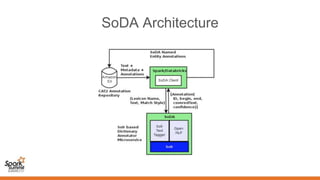
This document summarizes a presentation about annotating millions of documents at scale using dictionary-based annotation with Apache Spark, Apache Solr, and Apache OpenNLP. The key points discussed include: - The problem of annotating millions of documents from science corpora and the need to do it efficiently without model training. - The architecture of SoDA (Dictionary Based Named Entity Annotator), which uses Apache Solr, SolrTextTagger, and OpenNLP for annotation and can be run on Spark for scaling. - Performance optimizations made including combining paragraphs, tuning Solr garbage collection, using a larger Spark cluster, and scaling out Solr. These helped achieve over 25 documents per second annotation throughput.











![Annotation Service I/O
Example annotation request
{
“lexicon” : “countries”,
“text” : “Institute of Clean Coal Technology, East
China University”,
“matching” : “exact”
}
Example annotated response
[
{
“id” : “http://www.geonames.org/CHN”,
“lexicon” : “countries”,
“begin” : 41,
“end” : 46,
“coveredText” : “China”,
“confidence” : 1.0
}
]](https://image.slidesharecdn.com/07sujitpal-151029175243-lva1-app6891/85/Dictionary-Based-Annotation-at-Scale-with-Spark-by-Sujit-Pal-14-320.jpg)




![Loading Dictionaries
• Dictionary entries represented by:
– Lexicon Name
– Entry ID (unique across lexicons)
– List of possible synonym terms
• JSON Request to add an entry for MeSH dictionary.
{ “id”: http://id.nlm.nih.gov/mesh/2015/M0021699,
“lexicon”: “mesh”,
“names”: [“Baby Tooth”, “Dentitions, Primary”, “Milk Tooth”, ...],
“commit”: false }
• Preferable to commit periodically and after batch.](https://image.slidesharecdn.com/07sujitpal-151029175243-lva1-app6891/85/Dictionary-Based-Annotation-at-Scale-with-Spark-by-Sujit-Pal-19-320.jpg)










Dictionary Based Annotation at Scale with Spark by Sujit Pal
- 1. Dictionary Based Annotation at scale with Spark, SolrTextTagger and OpenNLP Sujit Pal, Elsevier Labs
- 2. Introduction • About Me – Work at Elsevier Labs. – Interested in Search, NLP and Distributed Processing. – URL: labs.elsevier.com – Email: [email protected] – Twitter: @palsujit • About Elsevier – World’s largest publisher of STM Books and Journals. – Uses Data to inform and enable consumers of STM info. – And like everybody else, we are hiring!
- 3. Agenda • Overview and Background • Features and API • Scaling out • Q&A
- 5. Problem Definition • What is the problem? – Annotate millions of documents from different corpora. • 14M docs from Science Direct alone. • More from other corpora, dependency parsing, etc. – Critical step for Machine Reading and Knowledge Graph applications. • Why is this such a big deal? – Takes advantage of existing linked data. – No model training for multiple complex STM domains. – However, simple until done at scale.
- 7. Dictionary Based NE Annotator (SoDA) • Part of Document Annotation Pipeline. • Annotates text with Named Entities from external Dictionaries. • Built with Open Source Components – Apache Solr – Highly reliable, scalable and fault-tolerant search index. – SolrTextTagger – Solr component for text tagging, uses Lucene FST technology. – Apache OpenNLP – Machine Learning based toolkit for processing Natural Language Text. – Apache Spark – Lightning fast, large scale data processing. • Uses ideas from other Open Source libraries – FuzzyWuzzy – Fuzzy String Matching like a boss. • Contributed back to Open Source – https://github.com/elsevierlabs-os/soda
- 9. How does it work (exact/case matching)? • Uses Aho-Corasick algorithm – treats the dictionary as a FST and streams text against it. Matches all patterns simultaneously. Diagram shows FST for vocabulary {“his”, “he”, “her”, “hers”, “she”}. • Michael McCandless implemented FSTs in Lucene (blog post). • David Smiley built SolrTextTagger to use Lucene FSTs. • SoDA uses SolrTextTagger for streaming exact and case-insensitive matching.
- 10. How does it work (fuzzy matching)? • Pre-normalizes each dictionary entry into various forms – Original – “Astrocytoma, Subependymal Giant Cell” – Lowercased – “astrocytoma, subependymal giant cell” – Punctuation – “astrocytoma subependymal giant cell” – Sorted – “astrocytoma cell giant subependymal” – Stemmed – “astrocytoma cell giant subependym” • Uses OpenNLP to parse input text into phrases, normalizes each phrase into the desired normalization level and matches against corresponding field. • Caller specifies normalization level.
- 11. Features and API
- 12. Feature Overview • Provides JSON over HTTP interface – Compose request as JSON document – HTTP POST document to JSON endpoint URL (HTTP GET for URL only requests). – Receive response as JSON document. • Language-Agnostic and Cross-Platform. • API can be used from standalone clients, Spark jobs and Databricks notebooks. • Examples in Scala and Python
- 13. Services • Status – index.json – returns a JSON (suitable for health check monitoring) • Single Lexicon Services – annot.json – annotates a block of text in streaming manner. Supports different levels of matching (strict to permissive). – matchphrase.json – annotates short phrases. Supports same matching levels as annot.json. • Multi-Lexicon Services – dicts.json – lists all lexicons available. – coverage.json – returns number of annotations by lexicon found for text across all available lexicons. • Indexing Services – delete.json – deletes entire lexicon from index. – add.json – adds an entry to the specified lexicon.
- 14. Annotation Service I/O Example annotation request { “lexicon” : “countries”, “text” : “Institute of Clean Coal Technology, East China University”, “matching” : “exact” } Example annotated response [ { “id” : “http://www.geonames.org/CHN”, “lexicon” : “countries”, “begin” : 41, “end” : 46, “coveredText” : “China”, “confidence” : 1.0 } ]
- 15. Calling Annotation Service • Client originally written in Python, using built-in json and requests libraries. • For Scala client, SoDA JAR provides classes to mimic json and requests functionality in Scala. • Input to both our (somewhat contrived) examples are: (pii: String, affStr: String) tuples as shown. • Match against a country lexicon to find country names.
- 16. Annotation Service – Python Client
- 17. Annotation Service – Scala Client
- 18. Annotation Service - Outputs • Each Annotation result provides: – Entity ID (not shown) – Begin position in text – End position in text – Matched Text – Confidence (not shown) • Zero or more Annotations possible per input text.
- 19. Loading Dictionaries • Dictionary entries represented by: – Lexicon Name – Entry ID (unique across lexicons) – List of possible synonym terms • JSON Request to add an entry for MeSH dictionary. { “id”: http://id.nlm.nih.gov/mesh/2015/M0021699, “lexicon”: “mesh”, “names”: [“Baby Tooth”, “Dentitions, Primary”, “Milk Tooth”, ...], “commit”: false } • Preferable to commit periodically and after batch.
- 20. Loading Dictionaries – Scala Client
- 21. Scaling Out
- 22. SoDA Performance – Expected • Test: annotate 14M docs in “reasonable time”. – Approx. 3s/doc with SoDA+Solr on ec2 r3.large box (15.5GB RAM, 32GB SSD, 2vCPU). – Total estimated time: 16.2 months! • Questions – Can we make the process faster? – Can we scale out the process?
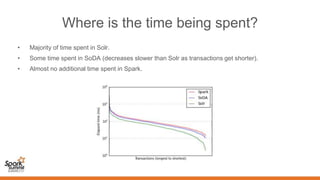
- 23. Where is the time being spent? • Majority of time spent in Solr. • Some time spent in SoDA (decreases slower than Solr as transactions get shorter). • Almost no additional time spent in Spark.
- 24. Optimization #1: Combine Paragraphs • Performance measured using 10K random articles. • Time to annotate 1 article: Mean 2.9s, Median 2.1s. • Annotation done per paragraph, 40 paragraphs/article on average. • Reduce HTTP network + parsing overhead by sending full document. • Time to annotate 1 article: Mean 1.4s, Median 0.3s. • 2x - 7x improvement.
- 25. Optimization #2: Tune Solr GC • OOB Solr would GC very frequently, slowing down Spark and causing timeouts. • Current Index Size: 2.1 GB • Need to size box so approximately 75% RAM given to OS and remaining 25% allocated to Solr (Uwe Schindler's Blog Post). • Heap size should be 3-4x index size (Internal Guideline). • Current Solr Heap Size = 8 GB • RAM is 30.5 GB • CMS (Concurrent Mark-Sweep) Garbage Collection.
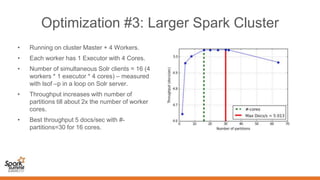
- 26. Optimization #3: Larger Spark Cluster • Running on cluster Master + 4 Workers. • Each worker has 1 Executor with 4 Cores. • Number of simultaneous Solr clients = 16 (4 workers * 1 executor * 4 cores) – measured with lsof –p in a loop on Solr server. • Throughput increases with number of partitions till about 2x the number of worker cores. • Best throughput 5 docs/sec with #- partitions=30 for 16 cores.
- 27. Optimization #4: Solr Scaleout • Upgrade to r3.xlarge (30.5GB RAM, 80GB SSD, 4vCPU) – Throughput 7.9 docs/s • Upgrade to 2x r3.2xlarge (61GB RAM, 160GB SSD, 8vCPU) with c3.large LB (3.75GB RAM, 32GB Disk, 2vCPU) running HAProxy. #-workers #- requests/serv er Throughput (docs/sec) 4 8 8.62 8 16 17.334 12 24 20.64 16 32 26.845
- 28. Performance – Did we meet expectations? • At 26 docs/sec and 14M documents, it will take our current cluster little over 6 days to annotate against our largest dictionary (8M entries). • Throughput scales linearly @ 1.5 docs/sec per additional worker, as long as Solr servers have enough capacity to serve requests. • Each Solr box (as configured) can serve sustained loads of up to 30-35 simultaneous requests. • Number of simultaneous requests approximately equal to number of worker cores. • Example: annotate 14M documents in 3 days. – Throughput required: 14M / (3 * 86400) = 54 docs/s – Number of workers: 54 / 1.5 = 36 workers – Number of simultaneous requests (4 cores/worker) = 36 * 4 = 144 – Number of Solr servers: 144 / 32 = 4.5 = 5 servers
- 29. Future Work • More Lexicons • Investigate Lexicon-Centric scale out. – Allows more lexicons. – Not limited to single index. • Move to Lucene, eliminate network overhead. – Asynchronous model – Use Kafka topic with multiple partitions – Lucene based tagging consumers – Write output to S3.
- 30. Q&A
- 31. Thank you for listening! • Questions? • SoDA available on GitHub – https://github.com/elsevierlabs-os/soda • Contact me – [email protected]