2. ❑ A distributed database is essentially a database that is dispersed
across numerous sites, i.e., on various computers or over a network
of computers, and is not restricted to a single system.
❑ A distributed database system is spread across several locations with
distinct physical components.
❑ A distributed database system consists of loosely coupled sites that
share no physical component
❑ Database systems that run on each site are independent of each
other
❑ Transactions may access data at one or more sites
❑ A database which is distributed over some form of network to bring
down the cost or the difficulty in accessing data and to increase the
efficiency of the whole system.
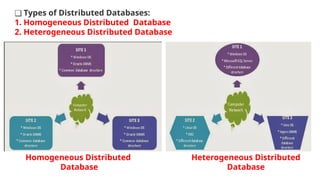
4. Homogeneous & Heterogeneous Distributed Databases
❖ Homogeneous Distributed Database
● Identical software are used in all the sites
○ Here, a site refers to a server which is part of the distributed database system
○ Software would mean OS, DBMS software, and even the structure of the database
used
○ In some cases, identical hardware are also used
● All sites are well known.
○ As they are similar in terms of DBMS software and hardware used, are aware of
each other and agree to cooperate in processing user requests.
● Partial control over the data of other sites
○ As we know the structure of databases, software and hardware used in other
sites, each site surrenders part of its autonomy in terms of right to change
schemas or software. Hence the partial control over the data is possible.
● Looks like a single central database system
A homogeneous database stores data uniformly across all locations. All sites utilize the
same operating system, database management system, and data structures. They are
therefore simple to handle.
5. Homogeneous & Heterogeneous Distributed Databases
❖ Heterogeneous Distributed Database
● Different sites uses different database schemas and software
○ Difference in schema is a major problem for query processing
○ Difference in software is a major problem for transaction processing
● The structure of databases reside in different sites may be different (because of data
partitions)
● Co-operation between sites are limited. That is, it is not easy to alter the structure of the
database or any other software used.
○ Sites may not be aware of each other and may provide only limited facilities for
cooperation in transaction processing
● Various operating systems and database applications may be used by various
machines. They could even employ separate database data models. Translations are
therefore necessary for communication across various sites.
6. Why Distributed Database?
We are interested in Distributed database for various reasons. Some of them are;
1. Data are always available to end users, i.e., they are easily accessible. The availability
makes the total system reliable.
2. Distributed database increases the performance of the overall system. Because, the
servers are available near the place where it is very much needed.
3. Support organizational growth. Because, the distributed database structure would not
cause stopping of all ongoing services. Only new distributed server may need to be
established to handle the new details.
4. Handling addition of any server, modification of existing modules etc. are easy.
5. Distributed data handling increases the parallelism. That is, a number of queries can be
handled simultaneously over multiple distributed server when compared to the central
server approach.
7. Components of Distributed DBMS Architecture
User processor and Data processor are
the two major components of Distributed
DBMS architecture.
These major components handle different
user requests using several sub-
components in a Peer-to-Peer Distributed
DBMS. Those are;
8. ❖ User Processor:
● User interface handler – interpreting user commands when they are given in, and
formatting the result sets when the request is answered.
● Semantic data controller – uses the Global Conceptual Schema to check the
integrity constraints defined on database elements and also to check the
authorizations on accessing the requested database.
● Global query optimizer and decomposer – devises a best execution strategy to
execute the given user requests in minimal cost (in terms of time, processor,
memory). It is like Query Optimizer in Centralized database systems. Only exception
is it has to devise a strategy which is globally optimal.
● Distributed execution monitor – it is the Transaction manager. The Transaction
managers of various sites that are participated in a query execution communicate
with each other as part of execution monitoring.
9. ❖ Data Processor:
● Local query optimizer – it optimizes data access by choosing the best access path.
For example, Local query optimizer decides which index to be used for optimally
executing the given query.
● Local recovery manager – deals with the consistency of the local database. In case
of failure, local recovery manager is responsible for maintaining a consistent
database.
● Run-time support processor – it accesses the database physically according to the
strategy suggested by the local query optimizer. The run-time support processor
is the interface to the operating system and contains the database buffer (or
cache) manager, which is responsible for maintaining the main memory buffers
and managing the data accesses.
10. Important considerations in distributed database over Centralized database
When compared to the centralized database system, the distributed database system should
be capable of or should have the following things.
1. Data allocation - We need to know the answers for the following questions; What to
store? Where to store? and How to store?
2. Data fragmentation - It is about, How one should organize the data?
3. Distributed queries and transactions - We must find a way to handle the data using
queries and to handle transactions which are happening in multiple distributed sites
(Here site means a server).
11. 1. Data allocation
Data allocation deals with the establishment of servers and maintenance of data in any
locations. Data allocation strategies can be made by keeping the following things in mind;
● The data should be available in or near a site where it is needed most.
● The storage of data in a site should increase the availability and reliability of data.
● The strategy chosen for data allocation should increase the performance. That is,
some of the drawbacks like bottleneck problem of central server concept or limited
usability of data should be avoided.
● The idea should reduce the cost involved in storage and manipulation of data
● There should be a much reduced traffic or utilization of network. It should also
ensure that there should never be a unnecessary use of network provided the data
available near.
As a whole, data allocation deals with the where to keep the fragmented or replicated data
for ease of access.
12. 2. Data fragmentation
Data fragmentation is about how to break a table into fragments?, how many fragments
need to be created? A table can be fragmented based on
a) what are the frequent applications accesses the data?,
b) what conditions are frequently used to access the data?, and
c) what is the simplest way of maintaining the table schema at any locations?
Here, the questions (a) and (b) mean the attributes and their values used for accessing a
table frequently. For example, for the query "SELECT * FROM student WHERE
campus='Mumbai'", campus='Mumbai' is the attribute name and value combination
Fragmentation is of two major types;
1. Horizontal fragmentation
1. Primary Horizontal fragmentation
2. Derived Horizontal fragmentation
2. Vertical fragmentation
13. 3. Distributed queries and Transactions
When the data are fragmented or replicated and distributed over many sites in the
network, then retrieval of the data involves the following;
● The identification of the location of requested data,
● A protocol to fetch the data, and
● A way to organize the data, if it was spread over multiple sites.
Hence, Distributed Database System must be able to handle the data over the network. It
just needs a special way to handle the queries and transactions over the conventional
centralized database. That is, the system must understand the query and the query
components and must be able to locate the data over network.
14. Distributed Data Storage
■ Replication
● System maintains multiple copies of data, stored in different sites, for faster retrieval
and fault tolerance.
● This has advantages since it makes more data accessible at many locations. Moreover,
query requests can now be handled in parallel.
● But, there are some drawbacks as well. Data must be updated often. All changes
performed at one site must be documented at every site where that relation is stored in
order to avoid inconsistent results. Moreover, since concurrent access must now be
monitored across several sites, concurrency management becomes far more
complicated.
■ Fragmentation
● Relation is partitioned into several fragments stored in distinct sites
● To ensure there is no data loss, the pieces must be created in a way that allows for the
reconstruction of the original relation.
■ Replication and fragmentation can be combined
● Relation is partitioned into several fragments: system maintains several identical
replicas of each such fragment.
15. Data Replication
■ A relation or fragment of a relation is replicated if it is stored
redundantly in two or more sites.
■ Full replication of a relation is the case where the relation is stored at
all sites.
■ Fully redundant databases are those in which every site contains a
copy of the entire database.
16. ■ Advantages of Replication
● Availability: failure of site containing relation r does not result in
unavailability of r is replicas exist.
● Parallelism: queries on r may be processed by several nodes in parallel.
● Reduced data transfer: relation r is available locally at each site containing
a replica of r.
■ Disadvantages of Replication
● Increased cost of updates: each replica of relation r must be updated.
● Increased complexity of concurrency control: concurrent updates to distinct
replicas may lead to inconsistent data unless special concurrency control
mechanisms are implemented.
17. Data Fragmentation
■ Division of relation r into fragments r1, r2, …, rn which contain sufficient
information to reconstruct relation r.
■ Horizontal fragmentation: each tuple of r is assigned to one or more
fragments
■ Vertical fragmentation: the schema for relation r is split into several
smaller schemas
● All schemas must contain a common candidate key (or superkey) to ensure
lossless join property.
● A special attribute, the tuple-id attribute may be added to each
schema to serve as a candidate key.
■ Example : relation account with following schema
■ Account = (branch_name, account_number, balance )
20. Advantages of Fragmentation
■ Horizontal:
● allows parallel processing on fragments of a relation
● allows a relation to be split so that tuples are located where they are most
frequently accessed
■ Vertical:
● allows tuples to be split so that each part of the tuple is stored where it is most
frequently accessed
● tuple-id attribute allows efficient joining of vertical fragments
● allows parallel processing on a relation
■ Vertical and horizontal fragmentation can be mixed.
● Fragments may be successively fragmented to an arbitrary depth.
21. Distributed Transactions
■ Transaction may access data at several sites.
■ Each site has a local transaction manager responsible for:
● Maintaining a log for recovery purposes
● Participating in coordinating the concurrent execution of the
transactions executing at that site.
■ Each site has a transaction coordinator, which is responsible for:
● Starting the execution of transactions that originate at the site.
● Distributing subtransactions at appropriate sites for execution.
● Coordinating the termination of each transaction that originates at the site,
which may result in the transaction being committed at all sites or aborted at
all sites.
23. Commit Protocols
■ Commit protocols are used to ensure atomicity across sites
● a transaction which executes at multiple sites must either be
committed at all the sites, or aborted at all the sites.
● not acceptable to have a transaction committed at one site and
aborted at another
■ The two-phase commit (2PC) protocol is widely used
■ The three-phase commit (3PC) protocol is more complicated and more
expensive, but avoids some drawbacks of two-phase commit protocol.
This protocol is not used in practice.
24. Two Phase Commit Protocol (2PC)
■ Assumes fail-stop model – failed sites simply stop working, and do not
cause any other harm, such as sending incorrect messages to other
sites.
■ Execution of the protocol is initiated by the coordinator after the last
step of the transaction has been reached.
■ The protocol involves all the local sites at which the transaction
executed
■ Let T be a transaction initiated at site Si, and let the transaction
coordinator at Si be Ci
25. Phase 1: Obtaining a Decision
■ Coordinator asks all participants to prepare to commit transaction Ti.
● Ci adds the records <prepare T> to the log and forces log to stable
storage
● sends prepare T messages to all sites at which T executed
■ Upon receiving message, transaction manager at site determines if it can
commit the transaction
● if not, add a record <no T> to the log and send abort T message to Ci
● if the transaction can be committed, then:
● add the record <ready T> to the log
● force all records for T to stable storage
● send ready T message to Ci
26. Phase 2: Recording the Decision
■ T can be committed of Ci received a ready T message from all the
participating sites: otherwise T must be aborted.
■ Coordinator adds a decision record, <commit T> or <abort T>, to the
log and forces record onto stable storage. Once the record stable
storage it is irrevocable (even if failures occur)
■ Coordinator sends a message to each participant informing it of the
decision (commit or abort)
■ Participants take appropriate action locally.
31. Two Phase Commit (2PC) protocol aborts the transaction, if any of the participating sites
are not ready for a commit.
Following are the steps :-
36. How does 2PC protocol handles failures in
distributed database?
❑Failure of a participating site
❑Failure of a coordinator
❑Network partition
37. Failure of a participating site
• There are two things we need to look into to handle such failure:-
1. The response of the Transaction Coordinator of transaction T.
If the failed site have not sent any <ready T> message, the TC cannot
decide to commit the transaction. Hence, the transaction T should be
aborted and other participating sites to be informed.
If the failed site have sent a <ready T> message, the TC can
assume that the failed site also was ready to commit, hence the
transaction can be committed by TC and the other sites will be
informed to commit. In this case, the site which recovers from failure
has to execute the 2PC protocol to set its local database up-to-date.
38. Failure of a participating site
2. The response of the failed site when it recovers.
The recovering site Si must identify the fate of the transactions which were
going on during the failure of Si. This can be done by examining the log file
entries of site Si.
The following are the possible cases and relevant actions:-
A) If the log contains a <commit T> entry - It means that all the other sites
including Si have responded with <ready T> message to TC and TC must have
send <commit T> to all the participants. Because, the participating sites are
not allowed to insert <commit T> message in the log file without the
coordinator’s decision. Hence, the recovered site Si can perform redo(T). That
is, T is executed once again locally by Si.
39. Failure of a participating site
B) If the log contains an <abort T> entry – Any site can have <abort T> message in its entry, if the decision
taken by the coordinator TC is to abort the transaction T. Hence, site Si executes undo(T).
C) If the log contains a <ready T> entry – This means that the site Si failed immediately after sending its own
status on transaction T. Now, it has contact the TC or other sites for deciding the fate of the transaction T.
The first choice is to contact the TC of transaction T. If the TC have an entry <commit T>, then
according to the above discussions, it is clear that the Si have to perform redo(T). If the TC have an entry
<abort T>, then Si performs undo(T).
The second choice is to contact the other sites which have participated in transaction T (this choice is
chosen only if TC is not available). Then the decision can be taken based on the other sites’ log entries.
D) If the log contains no control messages, i.e, no <abort T>, <commit T>, or <ready T> - It clearly shows that
the site Si has failed well before responding to the <prepare T> message. Hence, the TC must have aborted
the transaction. So, Si needs to execute a undo(T).
This is how the 2PC handles the failure of a participating Site.
40. Handling of Failures - Site Failure
When site Si recovers, it examines its log to determine the fate of
transactions active at the time of the failure.
■ Log contain <commit T> record: site executes redo (T)
■ Log contains <abort T> record: site executes undo (T)
■ Log contains <ready T> record: site must consult Ci to determine the fate of T.
● If T committed, redo (T)
● If T aborted, undo (T)
■ The log contains no control records concerning T replies that Sk failed before
responding to the prepare T message from Ci
● since the failure of Sk precludes the sending of such a response C1
must abort T
● Sk must execute undo (T)
41. Handling the Failure of a Coordinator Site
• Let us suppose that the Coordinator Site failed during execution of 2 Phase
Commit (2PC) protocol for a transaction T.
This situation can be handled in two ways:-
1. The other sites which are participating in the transaction T may try to
decide the fate of the transaction. That is, they may try to decide on Commit
or Abort of T using the control messages available in every site.
2. The second way is to wait until the coordinator site recovers.
42. Handling the Failure of a Coordinator Site
1.
A) If an active site has <commit T> message in its log - <commit T> message is
decided by the coordinator site. If the coordinator site sends the <commit T>
message to all the participating sites, then only they can write the message into
their log files. Hence, the decision is to commit the transaction T.
B) If an active site recorded <abort T> message in its log – This clearly shows that
the decision taken by the coordinator site before it fails was to abort the
transaction T. Hence, the decision should be abort T.
C) If some active sites do not hold a <ready T> message in their log files – As stated
in 2PC protocol, if one or more of the participating sites do not contain <ready T>
message in their log files, then it clearly shows that those sites must not have
responded to the coordinator on the <prepare T> message. Hence, the coordinator
must have taken a decision to abort the transaction T. So, we abort T.
43. Handling the Failure of a Coordinator Site
2.
If none of the cases A) ,B) , C) holds, we can apply only the second way
of handling the failure of coordinator site. That is, we need to wait until
the transaction coordinator recovers.
44. Handling of Failures- Coordinator
Failure
■ If coordinator fails while the commit protocol for T is executing then
participating sites must decide on T’s fate:
1. If an active site contains a <commit T> record in its log, then T must be
committed.
2. If an active site contains an <abort T> record in its log, then T must be
aborted.
3. If some active participating site does not contain a <ready T> record in
its log, then the failed coordinator Ci cannot have decided to commit T.
Can therefore abort T.
4. If none of the above cases holds, then all active sites must have a
<ready T> record in their logs, but no additional control records (such as
<abort T> of <commit T>). In this case active sites must wait for Ci to
recover, to find decision.
■ Blocking problem : active sites may have to wait for failed coordinator to
recover.
45. Handling of Network Partition Failure
• It refers to the failure of a network device that leads to the break of one network into two.
• During the execution of a transaction T, if any Network Partition happens, then there are
two possibilities of execution of transaction T.
Possibility 1
• The coordinator site and all the other participating sites may belong to one of the
partitions. That is, no sites are disconnected from the other physically. For this case, we do
not need to worry. The reason is, all the components executing transaction T are available
in one partition. Hence, 2PC does not have anything to do with this failure.
Possibility 2
• The coordinator site and all the other participating sites may belong to several partitions.
In this case, the Network Partition affects the execution.
• Now, the sites that are in a partition which is disconnected from coordinator execute 2PC
for handling coordinator failure.
46. Handling of Failures - Network Partition
■ If the coordinator and all its participants remain in one partition, the
failure has no effect on the commit protocol.
■ If the coordinator and its participants belong to several partitions:
●Sites that are not in the partition containing the coordinator think the
coordinator has failed, and execute the protocol to deal with failure of
the coordinator.
No harm results, but sites may still have to wait for decision from
coordinator.
■ The coordinator and the sites are in the same partition as the
coordinator think that the sites in the other partition have failed, and
follow the usual commit protocol.
Again, no harm results
47. Recovery and Concurrency Control
■ In-doubt transactions have a <ready T>, but neither a <commit T>, nor an <abort
T> log record.
■ The recovering site must determine the commit-abort status of such
transactions by contacting other sites; this can slow and potentially block
recovery.
■ Recovery algorithms can note lock information in the log.
● Instead of <ready T>, write out <ready T, L> L = list of locks held by T when
the log is written (read locks can be omitted).
● For every in-doubt transaction T, all the locks noted in the <ready T, L> log
record are reacquired.
■ After lock reacquisition, transaction processing can resume; the commit or
rollback of in-doubt transactions is performed concurrently with the execution
of new transactions.
48. Concurrency Control
■ Modify concurrency control schemes for use in distributed environment.
■ We assume that each site participates in the execution of a commit protocol
to ensure global transaction automicity.
■ We assume all replicas of any item are updated
Single-Lock-Manager Approach
■ System maintains a single lock manager that resides in a single chosen site, say Si
■ When a transaction needs to lock a data item, it sends a lock request to Si and lock
manager determines whether the lock can be granted immediately
● If yes, lock manager sends a message to the site which initiated the request
● If no, request is delayed until it can be granted, at which time a message is sent to
the initiating site
■ The transaction can read the data item from any one of the sites at which a replica of the
data item resides.
■ Writes must be performed on all replicas of a data item
■ On successful completion of transaction, the Transaction manager of initiating site can
release the lock through unlock request to the lock-manager site.
50. Advantages:
● Locking can be handled easily. We need two messages for lock (one for request, the other
for grant), and one message for unlock requests. Also, this method is simple as it
resembles the centralized database.
● Deadlocks can be handled easily. The reason is, we have one lock manager who is
responsible for handling the lock requests.
Disadvantages:
● The lock-manager site becomes the bottleneck as it is the only site to handle all the lock
requests generated at all the sites in the system.
● Highly vulnerable to single point-of-failure. If the lock-manager site failed, then we lose
the concurrency control.
51. Distributed Lock Manager
■ In this approach, the function of lock-manager is distributed over several sites.
[Every DBMS server (site) has all the components like Transaction Manager, Lock-
Manager, Storage Manager, etc.]
■ In Distributed Lock-Manager, every site owns the data which is stored locally.
■ This is true for a table that is fragmented into n fragments and stored in n sites. In
this case, every fragment is unique from every other fragment and completely owned
by the site in which it is stored. For those fragments, the local Lock-Manager is
responsible to handle lock and unlock requests generated by the same site or by
other sites.
■ If the data stored in a site is replicated in other sites, then a site cannot own the data
completely. In such case, we cannot handle any lock request for a data item stored in
a site as the case of fragmented data. If we handle like fragmented data, it leads to
inconsistency problems as there are multiple copies stored in several sites. This case
can be handled using several protocols which are specifically designed for handling
lock requests on replicated data. The protocols are, Primary copy, Majority protocol,
Biased protocol, Quorum consensus
52. Distributed Lock Manager
Advantages:
● Simple implementation is required for the data which are fragmented. They can be
handled as in the case of Single Lock-Manager approach.
● For replicated data, again the work can be distributed over several sites using one of
the above listed protocols.
● Lock-Manager site is not the bottleneck as the work of lock-manager is distributed
over several sites.
Disadvantages:
● Handling of Deadlock is difficult, because, a transaction T1 which acquired a lock on
a data item Q at site S1 may be waiting for lock on another data item R as site S2.
This wait is genuine or a deadlock has occurred is not easily identifiable.

















































![Distributed Lock Manager
■ In this approach, the function of lock-manager is distributed over several sites.
[Every DBMS server (site) has all the components like Transaction Manager, Lock-
Manager, Storage Manager, etc.]
■ In Distributed Lock-Manager, every site owns the data which is stored locally.
■ This is true for a table that is fragmented into n fragments and stored in n sites. In
this case, every fragment is unique from every other fragment and completely owned
by the site in which it is stored. For those fragments, the local Lock-Manager is
responsible to handle lock and unlock requests generated by the same site or by
other sites.
■ If the data stored in a site is replicated in other sites, then a site cannot own the data
completely. In such case, we cannot handle any lock request for a data item stored in
a site as the case of fragmented data. If we handle like fragmented data, it leads to
inconsistency problems as there are multiple copies stored in several sites. This case
can be handled using several protocols which are specifically designed for handling
lock requests on replicated data. The protocols are, Primary copy, Majority protocol,
Biased protocol, Quorum consensus](https://image.slidesharecdn.com/distributeddb-250306033156-cd7d4220/85/Distributed-database-detailed-version-by-jh-51-320.jpg)
