[DL輪読会]Depth Prediction Without the Sensors: Leveraging Structure for Unsupervised Learning from Monocular Videos (AAAI 2019)
Download as PPTX, PDF7 likes5,458 views

2019/03/01 Deep Learning JP: http://deeplearning.jp/seminar-2/
![1
DEEP LEARNING JP
[DL Papers]
http://deeplearning.jp/
Depth Prediction Without the Sensors: Leveraging Structure for
Unsupervised Learning from MonocularVideos (AAAI 2019)
Norihisa Kobayashi](https://image.slidesharecdn.com/struct2depth0301-190304050917/85/DL-Depth-Prediction-Without-the-Sensors-Leveraging-Structure-for-Unsupervised-Learning-from-Monocular-Videos-AAAI-2019-1-320.jpg)




![2. 先行研究
6
Unsupervised Learning of Depth and Ego-Motion from Video[Zhou, et al.(2017)]
• 深度とエゴモーション推定のための教師なし学習フレームワークを提案
• エンドツーエンドで、訓練のために単眼ビデオシーケンスのみを必要とする](https://image.slidesharecdn.com/struct2depth0301-190304050917/85/DL-Depth-Prediction-Without-the-Sensors-Leveraging-Structure-for-Unsupervised-Learning-from-Monocular-Videos-AAAI-2019-6-320.jpg)

![3. 提案手法
9
j 番目の画像
の推定
warping operator φ
i→jにおける
エゴモーション推定値
j番目の
深度推定値
𝐿 𝑟𝑒𝑐 = min( 𝐼1→2− 𝐼2 )φ 𝐼𝑖, 𝐷𝑗, 𝐸𝑖→𝑗 → 𝐼𝑖→𝑗
問題設定
i 番目の入力 j番目の推定値と、実際のj番目の入力の差が誤差
• 前後のフレームから中央のフレームへの再構成損失を計算
𝐿 𝑟𝑒𝑐 = min( 𝐼1→2− 𝐼2 , 𝐼3→2− 𝐼2 )
𝐿 = 𝛼1
𝑖=0
3
𝐿 𝑟𝑒𝑐
(𝑖)
+ 𝛼2 𝐿 𝑠𝑠𝑖𝑚
(𝑖)
+ 𝛼3
1
2𝑖
𝐿 𝑠𝑖𝑚
(𝑖)
損失関数
[Zhou et al. 2017; Godard, Aodha, and Brostow 2018]
画質の損失 深さの損失
• 全体の損失は、再構成損失に加えて、画質の損失、深さの損失を計算 Zhou et al. 2017;
Godard, Aodha, and Brostow 2017;
Wang et al. 2018](https://image.slidesharecdn.com/struct2depth0301-190304050917/85/DL-Depth-Prediction-Without-the-Sensors-Leveraging-Structure-for-Unsupervised-Learning-from-Monocular-Videos-AAAI-2019-9-320.jpg)


![4. 実験結果
12
定性的評価
• KITTIデータセット、Cityscapesデータセット、及びFetch Indoor Navigationデータセットで実験
• 既存手法(中央の行)と比較して、本論文の手法(下段)の方がより精度の高い深度予測が可能
KITTIデータセット Cityscapesデータセット
既存手法
[Zhou, et al.(2017)]
本論文の手法](https://image.slidesharecdn.com/struct2depth0301-190304050917/85/DL-Depth-Prediction-Without-the-Sensors-Leveraging-Structure-for-Unsupervised-Learning-from-Monocular-Videos-AAAI-2019-12-320.jpg)





![Appendix
補足
18
• Unsupervised Learning of Depth and Ego-Motion from Video[Zhou, et al.(2017)] を引用
• ターゲットビュー内の各点𝑝𝑡について、まず予測深度とカメラの姿勢に基づいてソースビューに投影し、バイリニア補間を
使用して位置𝑝𝑡におけるワープ画像 𝐼𝑠の値を取得する](https://image.slidesharecdn.com/struct2depth0301-190304050917/85/DL-Depth-Prediction-Without-the-Sensors-Leveraging-Structure-for-Unsupervised-Learning-from-Monocular-Videos-AAAI-2019-18-320.jpg)
[DL輪読会]Depth Prediction Without the Sensors: Leveraging Structure for Unsupervised Learning from Monocular Videos (AAAI 2019)
- 1. 1 DEEP LEARNING JP [DL Papers] http://deeplearning.jp/ Depth Prediction Without the Sensors: Leveraging Structure for Unsupervised Learning from MonocularVideos (AAAI 2019) Norihisa Kobayashi
- 2. 書誌情報 2 Depth Prediction Without the Sensors: Leveraging Structure for Unsupervised Learning from Monocular Videos (AAAI 2019)(https://arxiv.org/abs/1811.06152) タイトル: 著者: Vincent Casser, Soeren Pirk, Reza Mahjourian, Anelia Angelova • センサーを利用せずに、単眼のビデオカメラの入力からシーンの深度を予測する • カメラのエゴモーション(カメラ自身の速度や動き)を教師なし学習で推定する • オブジェクトの動きを含むシーンにおける深度予測及び、エゴモーション推定でSOTA • 屋外での訓練モデルを屋内ナビゲーションのためにドメイン転送も可能 概要: GitHub: https://github.com/tensorflow/models/tree/master/research/struct2depth その他: https://sites.google.com/view/struct2depth Google 特設ページ :
- 3. アジェンダ 3 1. 概要 2. 先行研究 3. 提案手法 4. 実験結果 5. まとめ
- 4. 1. 概要 • 入力画像からシーンの深度を予測することは、屋内でも屋外でも、ロボットナビゲーションにおいて重要 • シーンの深度予測における教師あり学習は、高価な深度センサを必要としていた。 4 背景 センサーを利用せずに単眼のビデオカメラでシーン深度推定を精度高く行いたい
- 5. 1. 概要 5 struct2depth • RGB画像入力からシーンの深度(奥行)とエゴモーション(カメラ自身の速度や動き)を教師なし学習 で捉える • 深度センサーは使用されず、単眼のビデオからのみ行われる • 個々のオブジェクトの動きが3Dで推定され、シーン内のすべてのオブジェクトの方向と速度が得られる
- 6. 2. 先行研究 6 Unsupervised Learning of Depth and Ego-Motion from Video[Zhou, et al.(2017)] • 深度とエゴモーション推定のための教師なし学習フレームワークを提案 • エンドツーエンドで、訓練のために単眼ビデオシーケンスのみを必要とする
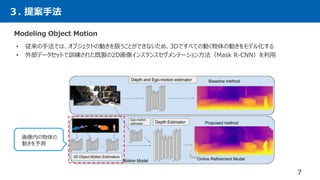
- 7. 3. 提案手法 7 Modeling Object Motion • 従来の手法では、オブジェクトの動きを扱うことができないため、3Dですべての動く物体の動きをモデル化する • 外部データセットで訓練された既製の2D画像インスタンスセグメンテーション方法(Mask R-CNN)を利用 画像内の物体の 動きを予測
- 8. 3. 提案手法 8 問題設定 𝐼1, 𝐼2, 𝐼3 ∈ 𝑅 𝐻×𝑊×3 𝐸1→2 = ψE( 𝐼1, 𝐼2 ) 入力: 深度関数 𝜃: 𝑅 𝐻×𝑊×3 → 𝑅 𝐻×𝑊 エゴモーションネットワーク ψ 𝐸: 𝑅2×𝐻×𝑊×3 → 𝑅6 = ψE( 𝑡 𝑥, 𝑡 𝑦 , 𝑡 𝑧 , 𝑟𝑥 , 𝑟𝑦 , 𝑟𝑧 ) 深度 𝐷 = 𝜃(𝐼𝑖) 𝐼1 𝐼2 𝐼3 入力 𝐼1→ 𝐼2における エゴモーション
- 9. 3. 提案手法 9 j 番目の画像 の推定 warping operator φ i→jにおける エゴモーション推定値 j番目の 深度推定値 𝐿 𝑟𝑒𝑐 = min( 𝐼1→2− 𝐼2 )φ 𝐼𝑖, 𝐷𝑗, 𝐸𝑖→𝑗 → 𝐼𝑖→𝑗 問題設定 i 番目の入力 j番目の推定値と、実際のj番目の入力の差が誤差 • 前後のフレームから中央のフレームへの再構成損失を計算 𝐿 𝑟𝑒𝑐 = min( 𝐼1→2− 𝐼2 , 𝐼3→2− 𝐼2 ) 𝐿 = 𝛼1 𝑖=0 3 𝐿 𝑟𝑒𝑐 (𝑖) + 𝛼2 𝐿 𝑠𝑠𝑖𝑚 (𝑖) + 𝛼3 1 2𝑖 𝐿 𝑠𝑖𝑚 (𝑖) 損失関数 [Zhou et al. 2017; Godard, Aodha, and Brostow 2018] 画質の損失 深さの損失 • 全体の損失は、再構成損失に加えて、画質の損失、深さの損失を計算 Zhou et al. 2017; Godard, Aodha, and Brostow 2017; Wang et al. 2018
- 10. 3. 提案手法 10 運動モデル • 本研究のアプローチは、3Dでオブジェクトをモデル化するだけでなく、それらの動きも学習する 𝑉 = 𝑂0 𝑆1 ʘ𝑂0 𝑆2 ʘ 𝑂0 𝑆3 𝐸1→2, 𝐸2→3 = ψE( 𝐼1 ʘ 𝑉, 𝐼2 ʘ 𝑉, 𝐼3 ʘ 𝑉 ) 𝑂0 𝑆バイナリマスク ※エゴモーションネットワークは、3つのRGBフレームから 同時に2つの変換を取得するように実施する インスタンス セグメンテーションマスク S𝑖,1, 𝑆𝑖,2, 𝑆𝑖,3 ∈ 𝑅 𝐻×𝑊 エゴモーションを計算するために、バイナリマスクを用いて物体の動きを画像から隠す
- 11. 3. 提案手法 11 運動モデル 𝑀1→2 (𝑖) , 𝑀2→3 (𝑖) = ψ 𝑀( 𝐼1→2 ʘ 𝑂𝑖( 𝑆1→2), 𝐼2 ʘ 𝑂𝑖 𝑆2 , 𝐼3→2 ʘ 𝑂𝑖( 𝑆3→2)) 𝐼1→2 (𝐹) = 𝐼1→2 ʘ 𝑉 + 𝑖=1 𝑁 𝐼1→2 (𝑖) ʘ 𝑂𝑖 𝑆2 画像内のすべてのオブジェクトの動き推定値を計算する。 𝑖 番目のオブジェクトの動き推定値 𝑀(𝑖) は次のように計算される。 最終出力はエゴモーションと、動的オブジェクトの動きとの足し合わせ オブジェクトの動き推定値 エゴモーション
- 12. 4. 実験結果 12 定性的評価 • KITTIデータセット、Cityscapesデータセット、及びFetch Indoor Navigationデータセットで実験 • 既存手法(中央の行)と比較して、本論文の手法(下段)の方がより精度の高い深度予測が可能 KITTIデータセット Cityscapesデータセット 既存手法 [Zhou, et al.(2017)] 本論文の手法
- 13. 4. 実験結果 13 運動モデルの評価 • 右図はCityscapesデータセットでの深度推定の例 • 従来の手法ではカメラ自体と一緒に動くオブジェクトの 推定精度が低い • 下表は、KITTIデータセットによる深度推定の精度 • 運動モデルと、推論プロセス中に予測を洗練するオン ライン適応方法の双方を採用することでSOTA
- 14. 4. 実験結果 14 KITTI オドメトリテストシーケンスにおけるオドメトリの定量的評価 • KITTIオドメトリデータセットによって実行されたオドメトリ(自己位置推定)の結果の比較 • テストされた合計走行シーケンス長は、それぞれ1,702メートルと918メートル
- 15. 4. 実験結果 15 屋内ナビゲーションデータセットのテスト • 屋外のCityscapesデータセットでトレーニングされて、屋内ナビゲーションデータでのみテストを実施 • 教師なしのオンラインで適応することができ、既存手法よりも正確な深度推定が可能
- 16. 5. まとめ 16 結論 • センサーを利用せずに、単眼のビデオカメラの入力からシーンの深度を予測する • カメラのエゴモーション(カメラ自身の速度や動き)を教師なし学習で推定する • オブジェクトの動きを含むシーンにおける深度予測及び、エゴモーション推定でSOTA • 屋外での訓練モデルを屋内ナビゲーションのためにドメイン転送も可能
- 17. Appendix 参考文献 17 • Wang, Z.; Bovik, A. C.; Sheikh, H. R.; and Simoncelli, E. P. 2004. Image quality assessment: from error visibility to structural similarity. Transactions on Image Processing. • Wang, C.; Buenaposada, J. M.; Zhu, R.; and Lucey, S. 2018. Learning depth from monocular videos using direct methods. CVPR. • Zhan, H.; Garg, R.; Weerasekera, C.; Li, K.; Agarwal, H.; and Reid, I. 2018. Unsupervised learning of monocular depth estimation and visual odometry with deep feature reconstruction. CVPR. • Zhou, T.; Brown, M.; Snavely, N.; and Lowe, D. 2017. Unsupervised learning of depth and ego-motion from video. CVPR.
- 18. Appendix 補足 18 • Unsupervised Learning of Depth and Ego-Motion from Video[Zhou, et al.(2017)] を引用 • ターゲットビュー内の各点𝑝𝑡について、まず予測深度とカメラの姿勢に基づいてソースビューに投影し、バイリニア補間を 使用して位置𝑝𝑡におけるワープ画像 𝐼𝑠の値を取得する