Docker Cluster Management with ECS
4 likes848 views

The document discusses Docker cluster management using Amazon ECS, covering key aspects such as instance bootstrapping, rolling updates, and detection of broken instances. It includes lessons learned from operational challenges, like using immutable servers and cautious scaling, and outlines future work on instance management and workload profiling. The focus is on ensuring zero-downtime updates and efficient resource management within production clusters serving multiple applications.



























































![CloudFormation Auto-‐Scaling
Group
Update
Policy
UpdatePolicy: {
AutoScalingRollingUpdate: {
MinInstancesInService: current_desired_capacity,
MaxBatchSize: '1',
PauseTime: 'PT30M',
WaitOnResourceSignals: 'true',
SuspendProcesses: ['AlarmNotification',
'HealthCheck',
'ReplaceUnhealthy',
'AZRebalance']
}
}](https://image.slidesharecdn.com/dockerclustermanagementv1-160710110649/85/Docker-Cluster-Management-with-ECS-62-320.jpg)









Docker Cluster Management with ECS
- 1. Docker Cluster Management with ECS Matt Callanan [email protected] linkedin.com/in/matthewcallanan @mcallana © 2016 Expedia Group Australia and New Zealand. All rights reserved.
- 2. Table of Contents • How Do We Bootstrap Instances? • Rolling Update with AutoScaling Group • How Do We Update Cluster Instances? • How Do We Detect & Remediate Broken Instances? • How Do We AnalyseCluster-‐Wide Issues? • How Do We Auto-‐Scale? • Lessons Learned • Future Work
- 3. Production Clusters – Serving 200 applications 7 14 instances: 56 apps (+ 19 canaries) 17 instances: 78 apps (+ 25 canaries) 35 instances: 107 apps (+ 23 canaries) 5 instances: 7 apps (+ 4 canaries) Charts produced with c3vis: github.com/ExpediaDotCom/c3vis
- 4. How Do We Bootstrap Instances?
- 5. How Do We Bootstrap Instances? • Based on Amazon’s ECS Optimized AMI • e.g. “amzn-‐ami-‐2016.03.b-‐amazon-‐ecs-‐optimized” • CloudFormation userdata runs at launch time to set up: • Networking • Security • Log forwarding • Cron job: Push EC2 statistics and custom metrics • Run ‘cadvisor’ and ‘docker-‐cleanup’ as ECS Tasks on each instance (using ‘start-‐task’)
- 6. Rolling Update with AutoScaling Group
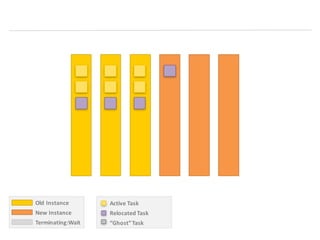
- 7. Old Instance New Instance Terminating:Wait Active Task Relocated Task “Ghost” Task
- 8. Old Instance New Instance Terminating:Wait Active Task Relocated Task “Ghost” Task
- 9. Old Instance New Instance Terminating:Wait Active Task Relocated Task “Ghost” Task
- 10. Old Instance New Instance Terminating:Wait Active Task Relocated Task “Ghost” Task
- 11. Old Instance New Instance Terminating:Wait Active Task Relocated Task “Ghost” Task
- 12. Old Instance New Instance Terminating:Wait Active Task Relocated Task “Ghost” Task
- 13. Old Instance New Instance Terminating:Wait Active Task Relocated Task “Ghost” Task
- 14. Old Instance New Instance Terminating:Wait Active Task Relocated Task “Ghost” Task
- 15. Old Instance New Instance Terminating:Wait Active Task Relocated Task “Ghost” Task
- 16. Old Instance New Instance Terminating:Wait Active Task Relocated Task “Ghost” Task
- 17. Old Instance New Instance Terminating:Wait Active Task Relocated Task “Ghost” Task
- 18. Old Instance New Instance Terminating:Wait Active Task Relocated Task “Ghost” Task
- 19. Old Instance New Instance Terminating:Wait Active Task Relocated Task “Ghost” Task
- 20. Old Instance New Instance Terminating:Wait Active Task Relocated Task “Ghost” Task
- 21. Old Instance New Instance Terminating:Wait Active Task Relocated Task “Ghost” Task
- 22. Old Instance New Instance Terminating:Wait Active Task Relocated Task “Ghost” Task
- 23. Old Instance New Instance Terminating:Wait Active Task Relocated Task “Ghost” Task
- 24. Old Instance New Instance Terminating:Wait Active Task Relocated Task “Ghost” Task
- 25. Old Instance New Instance Terminating:Wait Active Task Relocated Task “Ghost” Task
- 26. Old Instance New Instance Terminating:Wait Active Task Relocated Task “Ghost” Task
- 27. Old Instance New Instance Terminating:Wait Active Task Relocated Task “Ghost” Task
- 28. How Do We Update Cluster Instances?
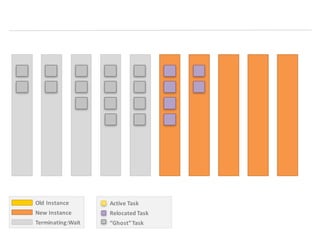
- 29. Zero-‐Downtime Instance Replacement • Uses a Lambda to avoid outages in production during a cluster instance rolling update • Lambda is triggered by AutoScaling EC2_INSTANCE_TERMINATE SNS events • Lambda deregisters the instance from the ECS cluster • Lambda also sends a heartbeat to the ASG to keep the instance in Terminating:Wait state for 30mins • This is generally enough to allow ECS to reschedule any tasks that are part of a service to another instance • Downsides: • Tasks can get rescheduled to another old instance in the ASG that is about to be replaced -‐ so tasks can get bumped from instance to instance until all instances are replaced • 30mins is a long time for old containers to still be registered in the services' ELBs. Any deploys during that time can cause confusion around why old and new versions of service are running behind ELB • ECS agent pulls Docker containers serially so can take a while to launch a bunch of new tasks
- 30. Old Instance New Instance Terminating:Wait Active Task Relocated Task “Ghost” Task
- 31. Old Instance New Instance Terminating:Wait Active Task Relocated Task “Ghost” Task
- 32. Old Instance New Instance Terminating:Wait Active Task Relocated Task “Ghost” Task
- 33. Old Instance New Instance Terminating:Wait Active Task Relocated Task “Ghost” Task
- 34. Old Instance New Instance Terminating:Wait Active Task Relocated Task “Ghost” Task
- 35. Old Instance New Instance Terminating:Wait Active Task Relocated Task “Ghost” Task
- 36. Old Instance New Instance Terminating:Wait Active Task Relocated Task “Ghost” Task
- 37. Old Instance New Instance Terminating:Wait Active Task Relocated Task “Ghost” Task
- 38. Old Instance New Instance Terminating:Wait Active Task Relocated Task “Ghost” Task
- 39. Old Instance New Instance Terminating:Wait Active Task Relocated Task “Ghost” Task
- 40. Old Instance New Instance Terminating:Wait Active Task Relocated Task “Ghost” Task
- 41. Old Instance New Instance Terminating:Wait Active Task Relocated Task “Ghost” Task
- 42. Old Instance New Instance Terminating:Wait Active Task Relocated Task “Ghost” Task
- 43. Old Instance New Instance Terminating:Wait Active Task Relocated Task “Ghost” Task
- 44. Old Instance New Instance Terminating:Wait Active Task Relocated Task “Ghost” Task
- 45. Old Instance New Instance Terminating:Wait Active Task Relocated Task “Ghost” Task
- 46. Old Instance New Instance Terminating:Wait Active Task Relocated Task “Ghost” Task
- 47. Old Instance New Instance Terminating:Wait Active Task Relocated Task “Ghost” Task
- 48. Old Instance New Instance Terminating:Wait Active Task Relocated Task “Ghost” Task
- 49. Old Instance New Instance Terminating:Wait Active Task Relocated Task “Ghost” Task
- 50. Old Instance New Instance Terminating:Wait Active Task Relocated Task “Ghost” Task
- 51. How Do We Detect & Remediate Broken Instances?
- 52. How Do We Detect & Remediate Broken Instances? • Custom Cloudwatch metrics • How long does “docker images” take? Alarm if longer than 4 seconds for 5mins • How long does “docker ps” take? Alarm if longer than 4 seconds for 5mins • Is the ecs agent running? Alarm if not for 5mins • Manual remediation based on email alert • Run “evict_instance” script • Terminates instance via ASG – allows Lambda to deregister and pause termination • aws autoscaling terminate-‐instance-‐in-‐auto-‐scaling-‐group -‐-‐region $REGION -‐ -‐instance-‐id $INSTANCE_ID -‐-‐no-‐should-‐decrement-‐desired-‐capacity
- 53. How Do We Analyse Cluster-‐Wide Issues?
- 54. How Do We Analyse Cluster-‐Wide Issues? • Centralised Logging • Forward instance logs to Splunk: • /var/log/cfn-‐* • /var/log/ecs* • Query with timechart
- 55. How Do We Auto-‐Scale?
- 56. How Do We Auto-‐Scale? • Scale Up: • CPU Reservation across entire cluster > 70% for 5mins or • Memory Reservation across entire cluster > 60% for 5mins • Scale Down • CPU Reservation < 20% for 5mins or • Memory Reservation < 40% for 5mins
- 57. Lessons Learned
- 58. Lesson #1 Use Immutable Servers with CloudFormation
- 59. Lesson #1: Use Immutable Servers with CloudFormation • cfn-‐update is dangerous if you don’t know what you’re doing • Problem: • Rolled out change that configures an extra docker EBS volume on new instances • cfn-‐update ran simultaneously on all old instances • Simultaneously restarted docker and deleted /var/lib/docker on all old instances – 5mins prod outage • Solution: • Removed cfn-‐update from userdata • Rename launch configuration every time to force CFN’s ASG Rolling Update even for minor config changes • Changed our mentality by renaming our “update” command to “replace_instances”
- 60. Lesson #2 Suspend ASG Processes During CFN Rolling Update
- 61. Lesson #1: Suspend ASG Processes During CFN Rolling Update • CFN and ASG are independent services • Problem: • Changed ASG from 1 to 2 subnets as part of CFN update • ASG instantly tries to launch n/2 instances in new subnet • Meanwhile CFN is waiting for 1 signal at a time – times out – rolls back • Solution: • Suspend processes with CFN Update Policy: • 'AlarmNotification’ • 'HealthCheck’ • 'ReplaceUnhealthy’ • 'AZRebalance’
- 62. CloudFormation Auto-‐Scaling Group Update Policy UpdatePolicy: { AutoScalingRollingUpdate: { MinInstancesInService: current_desired_capacity, MaxBatchSize: '1', PauseTime: 'PT30M', WaitOnResourceSignals: 'true', SuspendProcesses: ['AlarmNotification', 'HealthCheck', 'ReplaceUnhealthy', 'AZRebalance'] } }
- 63. Lesson #3 Don’t Use CloudFormation for Rolling Updates
- 64. Lesson #3: Don’t Use CloudFormationfor Rolling Updates • CFN interaction with ASG is too unreliable • Problem: • CFN timed out after not receiving a signal from instance created by ASG • AWS support explained there was an issue with the Auto Scaling service for 3hrs that caused CloudFormation to experience increased latency when creating, updating and deleting stacks in us-‐ east-‐1 • Solution: • Replace CFN rolling update with programmatic logic • Include health checks • Include deregistration logic
- 65. Lesson #4 Scale Down Carefully
- 66. Lesson #4: Scale Down Carefully • Problem: 1. ASG scales up due to high Memory Reservation 2. 5mins later ASG scales down due to low CPU Reservation 3. Repeat from #1 • Solution: • Fix scaling dimensions • Scale up when either CPU or Memory Reservation is high • Scale Down only on when both are low • Tightly control cpu / mem reservations per service • Match equal ratios of instance type resources
- 67. Future Work
- 68. Future Work: “Bulk Instance Replacement” • Bulk Instance Replacement • 1 canary instance • Increment DesiredCapacity / MaxSize • Add 1 instance to ASG and Cluster • Monitor / Test • Replace N-‐1 instances • Suspend Processes • Add n-‐1 instances to ASG • Deregister / Terminate old n-‐1 instances
- 69. Future Work: “Workload Profiles” • Predictable resource reservation • Workload Profiles • Opinionated resource sizings based on equal CPU / Memory ratio of instance type resources • App owners cannot specify cpu / mem – can only choose from preset profiles • Downsides: • Ties cluster to instance type family • Example: • For “m4” family… Profile CPU (Cores) Memory (GiB) Tiny 0.25 1 Small 0.5 2 Medium 1 4 Large 2 8 X.Large 4 16
- 70. Future Work: Treat Clusters as Cattle • Automate all manual aspects of cluster updates • Building confidence in our automated checks • Are there enough IP addresses in target subnets? • Is there enough EBS volume space for N instances? • Are there enough instances of desired instance type available? • Packer for building AMIs • Jenkins Pipeline for rolling out with confidence
- 71. Q & AThanks! Any Questions? Matt Callanan [email protected] linkedin.com/in/matthewcallanan @mcallana