Efficient Duplicate Detection Over Massive Data Sets
8 likes4,254 views

The document presents 'Dedoop', a solution for efficient duplicate detection using Hadoop, emphasizing the advantages of parallel and cloud environments for entity resolution (ER). It outlines the architecture and workflow for executing comparisons through blocking techniques, while allowing users to customize ER processes via an intuitive web interface. The conclusion highlights the scalability and efficiency of MapReduce frameworks for data cleaning and near-duplicate detection.



![Dedoop: Efficient Deduplication with Hadoop
Dedoop
http://dbs.uni-leipzig.de/dedoop
MapReduce-based entity resolution of large datasets.
Pair-wise similarity computation [O(n2)] executed in parallel.
Automatic transformation:
Workflow definition ⇒ Executable MapReduce workflow.
Avoid unnecessary entity pair comparisons
That result from the utilization of multiple blocking keys.
Pradeeban Kathiravelu (IST-ULisboa) Duplicate Detection 4 / 21](https://image.slidesharecdn.com/dqpradeebanpresentation4-150423052043-conversion-gate02/85/Efficient-Duplicate-Detection-Over-Massive-Data-Sets-4-320.jpg)
















Efficient Duplicate Detection Over Massive Data Sets
- 1. Efficient Duplicate Detection Over Massive Data Sets Pradeeban Kathiravelu INESC-ID Lisboa Instituto Superior T´ecnico, Universidade de Lisboa Lisbon, Portugal Data Quality – Presentation 4. April 21, 2015. Pradeeban Kathiravelu (IST-ULisboa) Duplicate Detection 1 / 21
- 2. Dedoop: Efficient Deduplication with Hadoop Introduction Blocking Grouping of entities that are “somehow similar”. Comparisons restricted to entities from the same block. Entity Resolution (ER, Object matching, deduplication) Costly. Traditional Blocking Approaches not effective. Pradeeban Kathiravelu (IST-ULisboa) Duplicate Detection 2 / 21
- 3. Dedoop: Efficient Deduplication with Hadoop Motivation Advantages of leveraging parallel and cloud environments. Manual tuning of ER parameters is facilitated as ER results can be quickly generated and evaluated. ⇓ Execution times for large data sets ⇒ Speed up common data management processes. Pradeeban Kathiravelu (IST-ULisboa) Duplicate Detection 3 / 21
- 4. Dedoop: Efficient Deduplication with Hadoop Dedoop http://dbs.uni-leipzig.de/dedoop MapReduce-based entity resolution of large datasets. Pair-wise similarity computation [O(n2)] executed in parallel. Automatic transformation: Workflow definition ⇒ Executable MapReduce workflow. Avoid unnecessary entity pair comparisons That result from the utilization of multiple blocking keys. Pradeeban Kathiravelu (IST-ULisboa) Duplicate Detection 4 / 21
- 5. Dedoop: Efficient Deduplication with Hadoop Features Several load balancing strategies In combination with its blocking techniques. To achieve balanced workloads across all employed nodes of the cluster. Pradeeban Kathiravelu (IST-ULisboa) Duplicate Detection 5 / 21
- 6. Dedoop: Efficient Deduplication with Hadoop User Interface Users easily specify advanced ER workflows in a web browser. Choose from a rich toolset of common ER components. Blocking techniques. Similarity functions. Machine learning for automatically building match classifiers. Visualization of the ER results and the workload of all cluster nodes. Pradeeban Kathiravelu (IST-ULisboa) Duplicate Detection 6 / 21
- 7. Dedoop: Efficient Deduplication with Hadoop Solution Architecture Map determines blocking keys for each entity and outputs (blockkey, entity) pairs. Reduce compares entities that belong to the same block. Pradeeban Kathiravelu (IST-ULisboa) Duplicate Detection 7 / 21
- 8. MapDupReducer: Detecting Near Duplicates .. Near Duplicate Detection (NDD) Multi-Processor Systems are more effective. MapReduce Platform. Ease of use. High Efficiency. Pradeeban Kathiravelu (IST-ULisboa) Duplicate Detection 8 / 21
- 9. MapDupReducer: Detecting Near Duplicates .. System Architecture Non-trivial generalization of the PPJoin algorithm into the MapReduce framework. Redesigning the position and prefix filtering. Document signature filtering to further reduce the candidate size. Pradeeban Kathiravelu (IST-ULisboa) Duplicate Detection 9 / 21
- 10. MapDupReducer: Detecting Near Duplicates .. Evaluation Data sets. MEDLINE documents. Finding plagiarized documents. 18.5 million records. BING. Web pages with an aggregated size of 2TB. Hotspot. High update frequency. Altering the arguments. Different number of map() and reduce() params. Pradeeban Kathiravelu (IST-ULisboa) Duplicate Detection 10 / 21
- 11. Efficient Similarity Joins for Near Duplicate Detection Similarity Definitions Pradeeban Kathiravelu (IST-ULisboa) Duplicate Detection 11 / 21
- 12. Efficient Similarity Joins for Near Duplicate Detection Efficient Similarity Join Algorithms Efficient similarity join algorithms by exploiting the ordering of tokens in the records. Positional filtering and suffix filtering are complementary to the existing prefix filtering technique. Commonly used strategy depends on the size of the document. Text documents: Edit distance and Jaccard similarity. Edit distance: Minimum number of edits required to transform one string to another. An insertion, deletion, or substitution of a single character. Web documents: Jaccard or overlap similarity on small or fix sized sketches. Near duplicate object detection problem is a generalization of the well-known nearest neighbor problem. Pradeeban Kathiravelu (IST-ULisboa) Duplicate Detection 12 / 21
- 13. Efficient Parallel Set-Similarity Joins Using MapReduce Introduction Efficiently perform set-similarity joins in parallel using the popular MapReduce framework. A 3-stage approach for end-to-end set-similarity joins. Efficiently partition the data across nodes. Balance the workload. The need for replication ⇓. Pradeeban Kathiravelu (IST-ULisboa) Duplicate Detection 13 / 21
- 14. Efficient Parallel Set-Similarity Joins Using MapReduce MapReduce Pradeeban Kathiravelu (IST-ULisboa) Duplicate Detection 14 / 21
- 15. Efficient Parallel Set-Similarity Joins Using MapReduce Parallel Set-Similarity Joins Stages 1 Token Ordering: Computes data statistics in order to generate good signatures. The techniques in later stages utilize these statistics. 2 RID-Pair Generation: Extracts the record IDs (“RID”) and the join-attribute value from each record. Distributes the RID and the join-attribute value pairs. The pairs sharing a signature go to at least one common reducer. Reducers compute the similarity of the join-attribute values and output RID pairs of similar records. 3 Record Join: Generates actual pairs of joined records. It uses the list of RID pairs from the second stage and the original data to build the pairs of similar records. Pradeeban Kathiravelu (IST-ULisboa) Duplicate Detection 15 / 21
- 16. Efficient Parallel Set-Similarity Joins Using MapReduce Token Ordering Pradeeban Kathiravelu (IST-ULisboa) Duplicate Detection 16 / 21
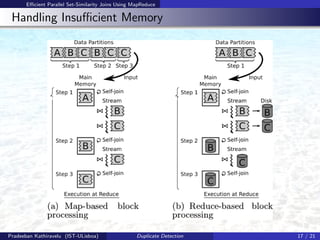
- 17. Efficient Parallel Set-Similarity Joins Using MapReduce Handling Insufficient Memory Pradeeban Kathiravelu (IST-ULisboa) Duplicate Detection 17 / 21
- 18. Efficient Parallel Set-Similarity Joins Using MapReduce Speedup Pradeeban Kathiravelu (IST-ULisboa) Duplicate Detection 18 / 21
- 19. Efficient Parallel Set-Similarity Joins Using MapReduce Scalability Pradeeban Kathiravelu (IST-ULisboa) Duplicate Detection 19 / 21
- 20. Conclusion Conclusion MapReduce frameworks offer an effective platform for near duplicate detection. Distributed execution frameworks can be leveraged for a scalable data cleaning. Efficient partitioning for data that cannot fit in the main memory. Software-Defined Networking and later advances in networking can lead to better data solutions. Pradeeban Kathiravelu (IST-ULisboa) Duplicate Detection 20 / 21
- 21. Conclusion References Kolb, L., Thor, A., & Rahm, E. (2012). Dedoop: efficient deduplication with Hadoop. Proceedings of the VLDB Endowment, 5(12), 1878-1881. Vernica, R., Carey, M. J., & Li, C. (2010, June). Efficient parallel set-similarity joins using MapReduce. In Proceedings of the 2010 ACM SIGMOD International Conference on Management of data (pp. 495-506). ACM. Wang, C., Wang, J., Lin, X., Wang, W., Wang, H., Li, H., ... & Li, R. (2010, June). MapDupReducer: detecting near duplicates over massive datasets. In Proceedings of the 2010 ACM SIGMOD International Conference on Management of data (pp. 1119-1122). ACM. Xiao, C., Wang, W., Lin, X., Yu, J. X., & Wang, G. (2011). Efficient similarity joins for near-duplicate detection. ACM Transactions on Database Systems (TODS), 36(3), 15. Thank you! Pradeeban Kathiravelu (IST-ULisboa) Duplicate Detection 21 / 21