Elastic Stack & Data pipeline (1장)
2 likes468 views

– Elastic stack과 Data pipeline의 개념 – 데이터의 종류와 형태 / Document 데이터 모델링 (mapping, data type) – 분산 데이터 저장소 관점에서의 Elasticsearch (index, shard & replica, segment) https://learningspoons.com/course/detail/elastic-stack/





























































































Elastic Stack & Data pipeline (1장)
- 1. Elastic Stack으로 시작하는 데이터 엔지니어링과 데이터 분석 Torres
- 2. Elastic Stack으로 시작하는 데이터 엔지니어링과 분석 Elastic Stack 데이터 엔지니어링 데이터 분석 이 세가지에 대해 알아보자
- 3. 데이터 엔지니어링 데이터 분석 데이터 관련 업무를 할 때, 데이터 엔지니어링과 데이터 분석은 상호보완적 역할을 한다. 필요한 형태로 데이터를 가공·저장 및 기술적인 이슈를 해결 서비스 개선을 위해 데이터를 다각도로 분석, 그 과정에서 필요한 것(데이터, 툴)들을 요구
- 4. Elastic Stack 수집 처리 저장 시각화 전체 데이터 관련 프로세스를 처리할 수 있다. 데이터 엔지니어링 데이터 분석
- 5. Elastic Stack만 사용한다는 것이 아닌 다양한 오픈소스와 솔루션을 함께 사용 분명한 점은, Elastic Stack은 데이터 관련 업무에서 중요한 포지션을 차지 하고 있다는 것
- 6. One pick
- 7. Ø Elastic Stack을 가지고 “우리 서비스에 필요한” 데이터 분석을 해본다. Ø Elastic Stack을 가지고 데이터 파이프라인을 이해하고 구축해본다. 강의 목표
- 8. Who Am I?
- 9. Kakao Mobility Data Engineer • Data Pipeline • AB Test Platform • Machine Learning Platform • Feature Engineering • Kubernetes & Cloud Native Application • Cloud Infrastructure & DevOps Torres.woo https://www.linkedin.com/in/torreswoo/
- 10. https://www.slideshare.net/jonghoWoo1/ab-test-platform-sk-planet Ø Elasticsearch를 사용한 User Event 데이터 저장 & 집계(Aggregation) Ø Metric & Chart 생성을 위한 Aggregation Ø Metric(CR, CTR, Revenue, Impression) & 시계열 데이터, 실시간 처리 Ø Experiment - Audience Targeting(유저타켓팅), Exclusive Group(상호배타실험) AB Test Platform
- 11. User Event Log 수집 Metric(CR, CTR, Revenue, Impression) 생성 & 시각화 https://www.slideshare.net/jonghoWoo1/ab-test-platform-sk-planet Elasticsearch
- 12. https://www.slideshare.net/JeminHuh/realtime-log-monitoring-platformpmon Tech planet 2016_Elastic search를이용한 Log기반 모니터링 & Log 검색 시스템 구축 Log & Monitoring System Ø 대용량 시계열 모니터링 데이터 처리 Ø 수천개의 Web & WAS log 정형화 & Service 데쉬보드 Ø 수천대의 서버 리소스 메트릭 모니터링 (CPU, Memory, Load, Disk, Network) Ø Near Real-Time (NRT) Log viewer
- 13. cnxlog collectd cnxlog collectd cnxlog collectd 서버의 시스템 Metric 정보 수집 -> collectd 서버의 Web & WAS Log 수집 -> cnxlog https://www.slideshare.net/JeminHuh/realtime-log-monitoring-platformpmon Tech planet 2016_Elastic search를이용한 Log기반 모니터링 & Log 검색 시스템 구축 Elasticsearch
- 14. • 그들이 AWS 위에서 Kubernetes 를 운영하는 방법 박훈@ZEPL • AWS 위에 올라간 모든걸 머리부터 발 끝까지 CTRL + C / V 박훈@ZEPL • 그들이 AWS 위에서 데이터 파이프라인을 운영하는법 (2019) 박훈@yanolja • 그들이 클라우드 위에서 데이터를 쉽고 빠르게 다루는 법(2019-7) 박훈@yanolja ZEPL (Apache Zeppelin SaaS), Cloud Notebook System Ø Elasticsearch를 사용한 Notebook Searching System Ø EFK(Elasticsearch, Fluentd, Kibana)를 사용한 Kubernetes Logging System
- 15. Notebook 문서를 메타 데이터와 함께 저장 문서 본문에 Analyzer(분석기)에 따라 색인 Elasticsearch
- 16. 1주차 강의 01. Elastic Stack? 02. Elastic Stack과 Data Pipeline 03. Elastic Stack을 사용하여 데이터 분석 Ø Docker로 개발환경 구축 Ø Docker-compose로 ELK 구축하기 Ø Kibana로 데이터 탐색 및 분석 Ø Elasticsearch 확인하기
- 19. Elasticsearch Ø 이제는 어느 회사나 하나쯤은 가지고 있는 Elasticsearch가 핵심 Ø 2015년, 0.7버전부터 사용. But, 운영이 너무 힘듬. 노드가 죽으면서 DB로서는 부적합? 그러나 2.X. 지금은 7.7 Ø https://github.com/elastic/elasticsearch Open Source, Distributed, Restful Search Engine 검색엔진?
- 20. 검색엔진 Lucene ㅣ 검색엔진의 시작. 더그커팅이 고안한 역색인 구조는 빠른 검색 결과를 제공하는데 최적의 성능. Apache Lucene을 개발. Apach Solr ㅣ 루씬 기반으로 분산 처리가 가능한 Apach Solr 검색엔진 Elasticsearch ㅣ 전통적인 URI검색 방식에서 → Request Body방식의 Query DSL. 특히 Aggregation API는 솔라의 집계 기술은 Facet API보다 훨씬 뛰어남
- 21. Elasticsearch! Not Just Searching Engine!
- 22. Elasticsearch! Not Just Searching Engine! • Distributed, Scalable • HA (High-Availability) • Distributed Document Store Cluster Node Shard Replicaindex 2주차 강의에서
- 23. Elasticsearch! Not Just Searching Engine! 3주차 강의에서
- 24. Distributed, Scalable HA, Fault Tolerance Near Real-Time (NRT) Full Text Searching Engine REST APIs JSON Document NoSQL Multi-tenancy Distributed Operation & Aggregation Cluster Node Shard Replicaindex indexing Refresh Document Segment TokenInverted Index JSON REST aggregation distributed query fetch
- 25. Distributed, Scalable https://www.elastic.co/guide/en/elasticsearch/guide/current/_scale_horizontally.html Node추가 데이터가 분산되어 저장 (reallocating) 2개의 노드, 1개 index (shard: 3 & replica:2)로 Cluster가 구성된 상태 Cluster Node Shard Replicaindex 2주차 강의
- 26. https://www.elastic.co/guide/en/elasticsearch/guide/current/_coping_with_failure.html HA, Fault Tolerance Replica, shard 3개의 노드중 1개의 노드가 장애가 난 경우 P1, P2 데이터가 loss되는거 아닐까?! P1 -> R1(노드2), P2-> R2(노드3) 각각 복사본(replica)가 존재하기 때문에 다시 복구가능 Cluster Node Shard Replicaindex 2주차 강의
- 27. Near Real-Time (NRT) https://www.elastic.co/guide/en/elasticsearch/guide/current/near-real-time.html Document, Data In-memory Buffer Segment System - File System Cache & Disk - Segment별 검색. 문서색인 생성과 검색표시 사이의 지연이 크게줄여듬 - 병목은 Disk. - Disk에 기록되기전 segment에만 작성되면 검색가능(Searchable)하게함 Settings : refresh_interval: “30s” Document Segment indexing Refresh Analysis Inverted Index 2주차 강의
- 28. Full Text Searching Engine https://www.elastic.co/kr/blog/found-elasticsearch-from-the-bottom-up Document, Data is winnter coming Token Stream Inverted Index Index Segment Analysis Document Segment indexing TokenInverted Index 2주차 강의
- 29. REST APIs Document JSON REST • Elasticsearch는 HTTP 프로토콜로 접근이 가능한 REST API를 지원. • 자원별로 고유 URL로 접근이 가능 • HTTP 메서드 PUT, POST, GET, DELETE 를 이용해서 자원을 처리 https://www.elastic.co/guide/en/elasticsearch/reference/current/rest-apis.html Document 생성 Document 조회 Document 수정 Document 삭제 Document API 2주차 강의
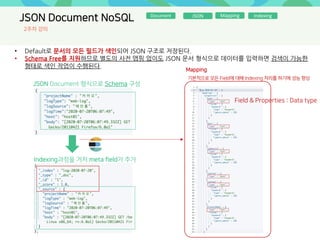
- 30. JSON Document NoSQL Document JSON indexingMapping • Default로 문서의 모든 필드가 색인되어 JSON 구조로 저장된다. • Schema Free를 지원하므로 별도의 사전 맵핑 없이도 JSON 문서 형식으로 데이터를 입력하면 검색이 가능한 형태로 색인 작업이 수행된다. JSON Document 형식으로 Schema 구성 Indexing과정을 거처 meta field가 추가 Mapping Field & Properties : Data type 기본적으로 모든 Field에 대해 Indexing 처리를 하기에 성능 향상 2주차 강의
- 31. Multi-tenancy Index https://www.elastic.co/kr/blog/found-multi-tenancy • 하나의 소프트웨어를 여러 사용자가 함께 사용하는 것 • Elasticsearch의 데이터들은 인덱스(Index) 라는 논리적인 집합 단위로 구성 • 서로 다른 저장소에 분산되어 저장 • 서로 다른 인덱스들을 별도의 커넥션 없이 하나의 질의로 묶어서 검색하고, 검색 결과들을 하나의 출력으로 도출. 2주차 강의
- 32. Distributed Operation & Aggregation https://www.elastic.co/guide/en/elasticsearch/guide/current/distrib-read.html • 분산환경에서는 이론상 데이터가 무한대로 늘어날 수 있기 때문에 많은 고민이 필요. -> 데이터양 / 정확도 / 실시간성 • 집계결과는 master 노드가 여러노드에 데이터를 집계해 질의에 답변 • cache : 질의의 결과를 임시버퍼(cache)에 둔다. 이후 같은 질의에 대해 다시 계산하지 않고, 버퍼에서 가져온다. aggregation distributed query fetch 3주차 강의
- 33. 여기서 잠깐
- 34. 여기서 잠깐 검색엔진? 네이버인가?... 분산 시스템인가?.. 난 분산 시스템 안쓰는데;; Aggregation은 뭐야.. 무서워.. JSON으로 저장되는게 좋은건가? 왜? NoSQL이고.. 스키마도 있다고?! (혼란)
- 35. 분산 저장소 분산 처리엔진분산 검색엔진 HDFS MongoDB Spark MapReduce Flink Solr Elasticsearch is ..
- 36. 이 세가지 관점을 섞어서 사용하면
- 37. Booking.com http://booking.com/ search Filtering & Aggregation Aggregation 날짜별 최저가 Sorting Contents & Product
- 39. Hoteltonight (AirBnB) https://www.hoteltonight.com/
- 40. Elasticsearch 그 이상 Elastic Stack
- 41. 정말 엄청난 회사.. 오픈소스중에서 가장 성공한 모델이 아닐까? https://www.elastic.co/kr/blog/doubling-down-on-open Elastic
- 42. • Logstash / Kibana를 흡수 • 수집단에서 Fluentd등 다른 대안이 있었는데. Beats를 개발 Logstash / Kibana / Beats 서로 다른 소스 사이에 데이터를 변환 & 전송 Input -> filter -> output 데이터 시각화 (+ 탐색, DevTool, Monitoring) 데이터 검색, 처리, 저장 데이터 수집
- 43. Elastic Stack의 완성 데이터 수집, 전송, 처리 , 저장, 시각화 모든 단계를 서포트하는 컴포넌트.
- 45. 이제는 Solution 부분 / Deployment 부분도 확장
- 46. 02. Elastic Stack & Data Pipeline
- 47. What is Data Pipeline ?
- 48. Data Pipeline? Raw Data Service Impact
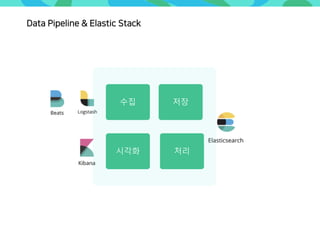
- 49. Data Pipeline! Raw Data Service Impact수집 저장 처리시각화
- 50. Data Pipeline & Elastic Stack 수집 저장 처리시각화
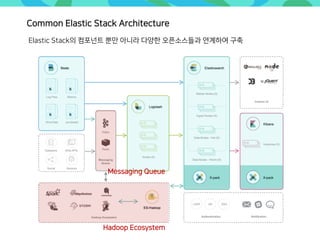
- 52. Common Elastic Stack Architecture Elastic Stack의 컴포넌트 뿐만 아니라 다양한 오픈소스들과 연계하여 구축 Messaging Queue Hadoop Ecosystem
- 53. Data Pipeline Use Case - Uber https://eng.uber.com/elk/Engineering Uber Predictions in Real Time with ELK • 위치, 날짜, 시간 및 기타 설정 변수에 따라 trip 밀도 및 일치 속도와 같은 일부 패턴을 예측 -> K-NN사용 • 1. 지리적 위치, 시간 등의 기능 에서 파생 된 자체 정의 유사성 기능을 기반으로 k 후보 선택 • 2. 유사도 함수 및 출력으로 각 응답 변수에 대한 가중 평균을 기반으로 선택한 각 후보에 대한 가중치를 계산 • 한 번에 수천 건의 쿼리(QPS)와 수억 건의 레코드를 처리 할 수 있는 강력한 저장소 및 검색 엔진이 필요 • 또한 k 개의 후보자 필터링을 지원하기 위해 지리 공간 쿼리 지원 • Kafka 주제를 수집하여 거의 실시간으로 데이터를 로드 여행 데이터, 여행 시간, 거리 및 비용과 같은 메트릭
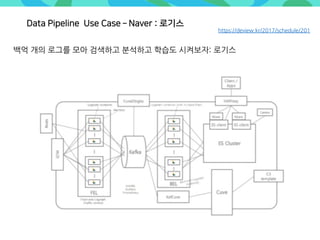
- 54. https://deview.kr/2017/schedule/201 백억 개의 로그를 모아 검색하고 분석하고 학습도 시켜보자: 로기스 Data Pipeline Use Case Naver : 로기스
- 55. 03. Elastic Stack & 데이터 분석
- 56. What is Data Analysis ? • 서비스를 위한 의사결정을 위한 가설 및 KPI를 수립 • 그 가설을 데이터로 검증 + 데이터에서 insight를 찾기 • 추가적인 분석을 위해 필요한 데이터를 요청 할 수 있다. 데이터 분야의 직군 소개
- 57. What is 지표(metric) ? • 오늘 새로운 가입자가 42명. • 오늘 의류 카테고리에서 판매금액이 350만원 증가 • 가입 전환율이 지난달 대비 4% 증가 • 지난주 이벤트 푸쉬에 참여하기 링크 CTR이 3.7% • 5월달 인당 평균 결제액은 7500원 Get User Drive Usage Make Money 서비스를 운영하면서 생성되는 다양한 Log를 의미있는 형태로 가공
- 58. 사람과 관련된 지표 돈과 관련된 지표 회원수 (User) • 상태별회원수 • 누적 회원수 • DAU, WAU, MAU (Active User) • MCU (Maximum Current User) • PU (Paying User) 가입전환율 재방문자 비율 방문간격 (Visit Frequency) 잔존율 (Retension Rate) 결제유저 비율(Paying User Rate) 매출 (Revenue) 결제횟수 (Transactions) ARPU (Average Revenue Per User) ARPPU (Average Revenue Per Paying User) ARPDAU (Average Revenue Per Daily Active User) ASP (Average Selling Price) 평균 구매 간격 (Purchase Frequency) CPC (Cost Per Click) : 클릭당비용 CPM (Cost Per Mille) : 1000개 노출당 비용 CPA (Cost Per Action & Acquisition) CAC (Customer Acquisition Cost) LTV (Lifetime Value) = CLV (Customer Lifetime Value) LTR (Lifetime Revenue) ROAS (Return on Ads Spending)
- 59. •데이터는 차트가 아니라 돈이 되어야 한다. •서비스 기획자를 위한 데이터분석 시작하기 •로그 데이터로 유저 이해하기 데이터 분석 관련 참고 자료
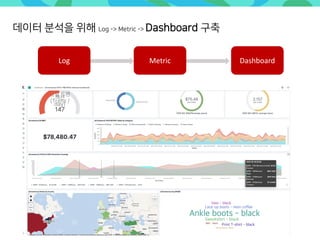
- 60. Log Metric Dashboard 데이터 분석을 위해 Log -> Metric -> Dashboard 구축
- 61. Q & A
- 62. 실습. Docker로 ELK 시스템을 구축하고 데이터 분석을 해보자
- 63. Docker
- 64. • 리눅스 컨테이너 기술(LXC)을 이용해서 어플리케이션 패키징, 배포를 지원하는 경량의 가상화 오픈소스 프로젝트. • Docker는 가볍다. • VM(20G~)에 비해 이미지파일크기가 작아서 빠르게 이미지를 만들고 실행가능. 수백MB정도 • Immutable Infrastructure : OS커널과 Service운영환경을 분리하자. • 관리가 편함 / 확장이 쉬움 / 경량화 됨. • 이런 Immutable Infrastructure의 구현체가 Docker Docker
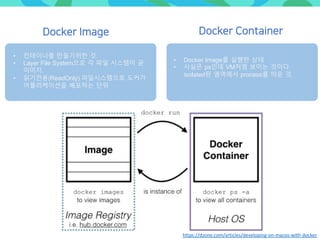
- 65. Docker Image • 컨테이너를 만들기위한 것. • Layer File System으로 각 파일 시스템이 곧 이미지. • 읽기전용(ReadOnly) 파일시스템으로 도커가 어플리케이션을 배포하는 단위 • Docker Image를 실행한 상태 • 사실은 ps인데 VM처럼 보이는 것이다. isolated된 영역에서 process를 띄운 것. Docker Container https://dzone.com/articles/developing-on-macos-with-docker
- 66. Dockerfile 도커이미지를 만들기 위해 설치할 SW, 필요한 설정을 정의하는 파일 https://github.com/elastic/elasticsearch/blob/master/distribution/docker/src/docker/Dockerfile $> docker search hello-world #이미지검색 $> docker pull hello-world #이미지다운 $> docker run hello-world #실행 $> docker rmi hello-world #이미지삭제 $> docker images #로컬에 있는 이미지 정보 $> docker info #도커정보 $> docker ps #컨테이너 프로세스정보 $> docker inspect hello-world $> docker logs hello-world
- 67. Docker Compose
- 68. Elasticsearch Kibana http://localhost:9200 http://localhost:5601 $> docker-compose –f docker-compose.simple.yml up
- 71. 실습. Kibana • Load Data • Discovery • Visualization & Dashboard • DevTool • Management
- 72. Kibana
- 73. Kibana Home Discovery Visualize Dashboard Dev Tool Monitoring Management Sample data Upload File Create Index Pattern Home
- 74. Kibana Load Data
- 75. Kibana Upload data From File (csv) 100MB 이하 데이터만가능
- 76. https://www.kaggle.com/olistbr/brazilian-ecommerce?select=olist_order_items_dataset.csv 01. 캐글에서 샘플데이터 확인 olist_order_items_dataset.csv - order_id - order_item_id - product_id - Seller_id - Shipping_limit_date - Price - Freight_value
- 77. 02. Kibana Upload data From File Summary Data - Time field & format Field별 stats정보
- 78. 03. Import data index pattern Shard 개수설정 Mapping 수정
- 80. 05. View index in Discovery ㅊ Time Range
- 81. 06. Index Management 15MB(원본) -> 31MB (Elasticsearch)
- 82. Kibana Add Sample Data
- 83. Kibana Add Sample Data https://www.elastic.co/guide/en/kibana/current/tutorial-sample-data.html - eCommerce orders - Flight data - Web logs
- 85. Discovery ㅊ 필드정보 Time RangeSearching (KQL) Filter Index Name Kibana Discovery
- 86. Kibana Discovery : Add Filter
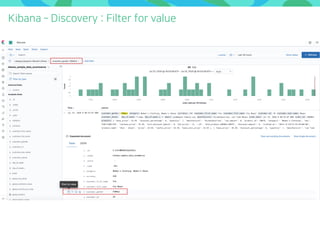
- 87. Kibana Discovery : Filter for value
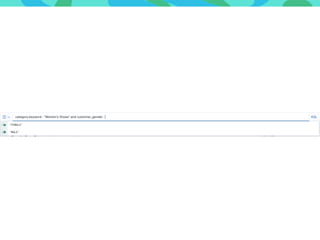
- 88. Kibana Discovery : KQL https://www.elastic.co/guide/en/kibana/7.6/kuery-query.html
- 90. Kibana Visualization & Dashboard
- 91. Kibana Visualization & Dashboard 총 매출액에 대해서 알아보자
- 93. Metric 매출에 대한 field를 선택 Min, max, sum, avg..중 sum이 총합계
- 94. Bar chart 일별로 총매출액의 변화를 확인 Metric Aggregation - sum Bucket Aggregation Date Historgram
- 95. Kibana Devtool
- 96. Kibana Devtool Dev Tool
- 101. Q & A