











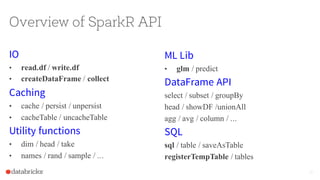
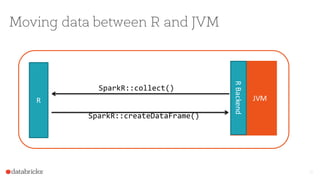










The document discusses the integration of Apache Spark with R through the sparkr package, which facilitates the use of R's data manipulation capabilities alongside Spark's distributed computing. It highlights Spark's features such as real-time streaming, machine learning, and scalability, while addressing R's limitations in handling large datasets. The document also provides an overview of the sparkr architecture and outlines a roadmap for future features and use cases in exploratory data analysis.























































































