

















![• Accuracy of the deepfake detector on the adversarially-generated images, when the
adversarial attacks target the top-1, top-2 and top-3 scoring segments of the input
images by the explanation method
• Ranges in [0, 1], where the upper boundary denotes a 100% detection accuracy
• Anticipate larger decrease in accuracy for explanation methods that spot the most influential
regions of the input image, more effectively
• Sufficiency of explanation methods to spot the most influential image regions for the
deepfake detector, by calculating the difference in the detector’s output before and
after applying adversarial attacks to the top-1, top-2 and top-3 scoring segments
• Ranges in [0,1], where low/high sufficiency scores indicate that the top-k scoring segments
by the explanation method have low/high impact to the deepfake detector’s decision
• Anticipate higher sufficiency scores for explanation methods that spot the most influential
regions of the input image, more effectively
Comparative Study Setup: Evaluation measures](https://image.slidesharecdn.com/2024-deepfakexaiv1-240620142327-085c6709/85/Explainable-Deepfake-Image-Video-Detection-19-320.jpg)
















Explainable Deepfake Image/Video Detection
- 1. Title of presentation Subtitle Name of presenter Date Towards Quantitative Evaluation of Explainable AI Methods for Deepfake Detection K. Tsigos, E. Apostolidis, S. Baxevanakis, S. Papadopoulos, V. Mezaris Information Technologies Institute, CERTH, Thermi - Thessaloniki, Greece MAD’24 Workshop @ ACM ICMR 2024
- 2. Deepfakes: definition and current status Definition: • Deepfakes are AI manipulated media in which, a person's face or body is digitally swapped to alter their identity or reenacted according to a driver video Image source: https://malcomvetter.medium. com/deep-deep-fakes-d4507c735f44 Current status: • Ongoing improvement of Generative AI technologies enables to create deepfakes that are increasingly difficult to detect • Over the last years deepfakes have been used as a means for spreading disinformation • Increasing need for effective solutions for deepfake detection
- 3. How to detect them? Image source: https://bdtechtalks.com/2023/05/12/detect- deepfakes-ai-generated-media Through human inspection • An investigator carefully checks for inconsistencies or artifacts in the image or video, such as unnatural facial movements and lighting, or mismatched audio Using trained deepfake detectors • An investigator analyses the image or video using a trained deepfake detector and takes into account the output of the analysis for making a decision
- 4. How to detect them? “Detect if the image or video frame is a deepfake or not” Image source: Charitidis et al., (2020) P. Charitidis, G. Kordopatis-Zilos, S., Papadopoulos and I. Kompatsiaris, I. (2020). Investigating the impact of pre-processing and prediction aggregation on the deepfake detection task. Truth and Trust Online Conference (TTO) 2020
- 5. A deepfake image that has been misclassified as “real” and the visual explanation indicating which part (within the yellow line) influenced the most this decision Why explainable deepfake detection? • The decision mechanism behind trained deepfake detectors is neither visible to the user nor straightforward to understand • Enhancing deepfake detectors with explanation mechanisms about their outputs would significantly improve the users' trust in them Visual explanations could • Allow obtaining insights about the applied image/video manipulation for creating the detected deepfake • Provide clues about the trustworthiness of the detector’s decision
- 6. Works on explainable deepfake detection Work Approach Malolan et al., 2020 Use of LIME and LRP to explain an XceptionNet deepfake detector; quantitative evaluation on a few samples focusing on their robustness against affine transformations or Gaussian blurring of the input Xu et al., 2022 Production of heatmap visualizations and UMAP topology explanations using the learned features of a linear deepfake detector; qualitative evaluation on some examples and examining the manifolds Silva et al., 2022 Use of Grad-CAM to explain an ensemble of CNNs and an attention-based model for deepfake detection; qualitative evaluation using a few examples Jayakumar et al., 2022 Use of Anchors and LIME to explain an EfficientNet deepfake detector; qualitative evaluation with human participants and extraction of metrics for quantitative evaluation Aghasanli et al., 2023 Use of support vectors/prototypes of an SVM and xDNN classifier to explain a ViT deepfake detector; qualitative evaluation using a few examples Haq et al., 2023 Production of textual explanations for a neurosymbolic method that detects emotional inconsistencies in manipulated faces using a deepfake detector; evaluation discussed theoretically Gowrisankar et al., 2024 Quantitative evaluation framework for explainable deepfake detection, based on adversarial attacks on fake images by leveraging the produced explanations of their non-manipulated counterparts
- 7. Starting point: The work of Gowrisankar et al., (2024) • Apply adversarial attacks (using NES) in regions of a fake image that correspond to the identified salient visual concepts after explaining the (correct) classification of its real counterpart Proposed evaluation framework B. Gowrisankar and V. L.L. Thing. 2024. An adversarial attack approach for eXplainable AI evaluation on deepfake detection models. Computers & Security 139 (2024), 103684. https://doi.org/10.1016/j.cose.2023.103684 • Evaluate the performance of an explanation method based on the observed drop in the accuracy of the deepfake detector Image source: Gowrisankar et al., (2024)
- 8. Observed limitations: • Takes the unusual step of using the produced explanation after correctly classifying a real (non-manipulated) image, in order to assess the capacity of an explanation method to explain the detection of a fake (manipulated) image Proposed evaluation framework B. Gowrisankar and V. L.L. Thing. 2024. An adversarial attack approach for eXplainable AI evaluation on deepfake detection models. Computers & Security 139 (2024), 103684. https://doi.org/10.1016/j.cose.2023.103684 Image source: Gowrisankar et al., (2024) • Requires access to pairs of real-fake images, thus being non-applicable on datasets that contain only fake examples, e.g., the WildDeepfake dataset (Zi, 2020)
- 9. Observed limitations: • Takes the unusual step of using the produced explanation after correctly classifying a real (non-manipulated) image, in order to assess the capacity of an explanation method to explain the detection of a fake (manipulated) image Proposed evaluation framework B. Gowrisankar and V. L.L. Thing. 2024. An adversarial attack approach for eXplainable AI evaluation on deepfake detection models. Computers & Security 139 (2024), 103684. https://doi.org/10.1016/j.cose.2023.103684 Image source: Gowrisankar et al., (2024) • Requires access to pairs of real-fake images, thus being non-applicable on datasets that contain only fake examples, e.g., the WildDeepfake dataset (Zi, 2020)
- 10. Proposed evaluation framework Our solution: • Takes into account the produced visual explanation for the deepfake detector's decision after correctly classifying a fake/manipulated image • Does not require access to the original counterpart; simpler and more widely-applicable • Assesses the performance of explanations using two measures and taking into account the 3 most influential regions of the input image Main intuition: • Providing an explanation after detecting a fake image is more meaningful for the user, as it can give clues about regions of the image that were found to be manipulated • Explanations after classifying an image as “real” would demarcate specific image regions as non-manipulated, and not the entire image (see figure)
- 11. Proposed evaluation framework Given a fake image and the visual explanation for the detector's decision, our framework assesses the performance of the explanation method by examining the extent to which the regions in the explanation can be used to flip the deepfake detector's decision
- 12. Proposed evaluation framework Steps of the processing pipeline 1. Produce the visual explanation (heatmap) of the input image
- 13. Proposed evaluation framework Steps of the processing pipeline 2. Segment the input image into super-pixel segments using the SLIC algorithm
- 14. Proposed evaluation framework Steps of the processing pipeline 3. Overlay the created visual explanation to the segmented image
- 15. Proposed evaluation framework Steps of the processing pipeline 4. Quantify the contribution of each segment by averaging the scores of the explanation for the pixels of the segment, and select the top-k scoring ones
- 16. Proposed evaluation framework Steps of the processing pipeline 5. Iteratively apply NES to add noise to the corresponding regions of the input image; stop if the deepfake detector classifies the adversarial image as “real” or a maximum number of iterations is reached
- 17. • Built upon the 2nd version of Efficient-Net, which • Has a widespread adoption and state-of-the art performance in deepfake detection tasks • Outperforms alternative CNN architectures (XceptionNet and MesoNet) on various deepfake datasets, while requiring fewer parameters • Won Meta’s DFDC challenge for an ensemble of five EfficientNet-B7 models • Trained for multiclass classification on the FaceForensics++ dataset Comparative Study Setup: Deepfake detection model Model ff_attribution Task multiclass Architecture efficientnetv2_b0 Type CNN No. Params 7.1M No. Datasets 1 Input (B, 3, 224, 224) Output (B, 5) Metric Value MulticlassAccuracy 0.9626 MulticlassAUROC 0.9970 MulticlassF1Score 0.9627 MulticlassAveragePrecision 0.9881 Performance (FF++ test set) Model characteristics
- 18. • Grad-CAM++: back-propagation-based method that generates visual explanations by leveraging the information flow (gradients) during the back-propagation process • RISE: perturbation-based method that produces binary masks and uses the model predictions of the generated perturbed images as mask weights in order to aggregate them together and form the explanation • SHAP: attribution-based method that leverages the Shapley values from game theory; it constructs an additive feature attribution model that attributes an effect to each input feature and sums the effects as a local approximation of the output • LIME: perturbation-based method that locally approximates a model’s behavior; it fits the model scores of the perturbed images to the binary perturbation masks using a simpler linear model and leverages its coefficients/weights to create the explanation • SOBOL: attribution-based method that employs the concept of Sobol’ indices, to identify the contribution of input variables on the variance of the model’s output Comparative Study Setup: Explanation Methods
- 19. • Accuracy of the deepfake detector on the adversarially-generated images, when the adversarial attacks target the top-1, top-2 and top-3 scoring segments of the input images by the explanation method • Ranges in [0, 1], where the upper boundary denotes a 100% detection accuracy • Anticipate larger decrease in accuracy for explanation methods that spot the most influential regions of the input image, more effectively • Sufficiency of explanation methods to spot the most influential image regions for the deepfake detector, by calculating the difference in the detector’s output before and after applying adversarial attacks to the top-1, top-2 and top-3 scoring segments • Ranges in [0,1], where low/high sufficiency scores indicate that the top-k scoring segments by the explanation method have low/high impact to the deepfake detector’s decision • Anticipate higher sufficiency scores for explanation methods that spot the most influential regions of the input image, more effectively Comparative Study Setup: Evaluation measures
- 20. • Contains 1000 original videos and 4000 fake videos • 4 fake video classes: FaceSwap (FS), DeepFakes (DF), Face2Face (F2F), NeuralTextures (NT) • 720 videos for training, 140 for validation and 140 for testing, respectively Used 127 videos from each different class of the test set and sampled 10 frames per video, creating four sets of 1270 images Experiments: Dataset FaceForensics++ (https://github.com/ondyari/FaceForensics) Image Source: https://github.com/ondyari/FaceForensics
- 21. Explanation Methods: • Grad-CAM++: average of all convolutional 2D layers • RISE: number of masks = 4000, default values for all the other parameters • SHAP: number of evaluations = 2000, blurring mask with kernel size = 128 • LIME: number of perturbations = 2000, SLIC segmentation algorithm with target number of segments = 50 • SOBOL: grid size equal = 8, number of design = 32, default values for all the other parameters NES Algorithm: number of maximum iterations = 50, learning rate = 1/255, maximum distortion = 16/255, search variance = 0.001 and number of samples = 40 Experiments: Implementation details
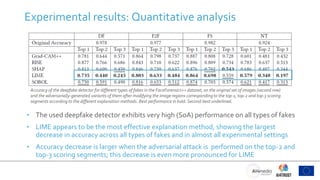
- 22. Experimental results: Quantitative analysis Accuracy of the deepfake detector for different types of fakes in the FaceForensics++ dataset, on the original set of images (second row) and the adversarially-generated variants of them after modifying the image regions correspondingto the top-1, top-2 and top-3 scoring segments according to the different explanation methods. Best performance in bold. Second-best underlined. • The used deepfake detector exhibits very high (SoA) performance on all types of fakes • LIME appears to be the most effective explanation method, showing the largest decrease in accuracy across all types of fakes and in almost all experimental settings • Accuracy decrease is larger when the adversarial attack is performed on the top-2 and top-3 scoring segments; this decrease is even more pronounced for LIME
- 23. Experimental results: Quantitative analysis Accuracy of the deepfake detector for different types of fakes in the FaceForensics++ dataset, on the original set of images (second row) and the adversarially-generated variants of them after modifying the image regions correspondingto the top-1, top-2 and top-3 scoring segments according to the different explanation methods. Best performance in bold. Second-best underlined. • The used deepfake detector exhibits very high (SoA) performance on all types of fakes • LIME appears to be the most effective explanation method, showing the largest decrease in accuracy across all types of fakes and in almost all experimental settings • Accuracy decrease is larger when the adversarial attack is performed on the top-2 and top-3 scoring segments; this decrease is even more pronounced for LIME
- 24. Experimental results: Quantitative analysis • The used deepfake detector exhibits very high (SoA) performance on all types of fakes • LIME appears to be the most effective explanation method, showing the largest decrease in accuracy across all types of fakes and in almost all experimental settings • Accuracy decrease is larger when the adversarial attack is performed on the top-2 and top-3 scoring segments; this decrease is even more pronounced for LIME Accuracy of the deepfake detector for different types of fakes in the FaceForensics++ dataset, on the original set of images (second row) and the adversarially-generated variants of them after modifying the image regions correspondingto the top-1, top-2 and top-3 scoring segments according to the different explanation methods. Best performance in bold. Second-best underlined.
- 25. Experimental results: Quantitative analysis Accuracy of the deepfake detector for different types of fakes in the FaceForensics++ dataset, on the original set of images (second row) and the adversarially-generated variants of them after modifying the image regions correspondingto the top-1, top-2 and top-3 scoring segments according to the different explanation methods. Best performance in bold. Second-best underlined. • SOBOL seems to be the most competitive in most cases • SHAP shows good performance in the case of DF and FS samples when spotting the top- 2 or top-3 regions of the image • Comparisons across the types of fakes: explanation methods can explain more effectively the detection of DF and NT; the explanation of F2F and FS is a more challenging
- 26. Experimental results: Quantitative analysis • SOBOL seems to be the most competitive in most cases • SHAP shows good performance in the case of DF and FS samples when spotting the top- 2 or top-3 regions of the image • Comparisons across the types of fakes: explanation methods can explain more effectively the detection of DF and NT; the explanation of F2F and FS is a more challenging Accuracy of the deepfake detector for different types of fakes in the FaceForensics++ dataset, on the original set of images (second row) and the adversarially-generated variants of them after modifying the image regions correspondingto the top-1, top-2 and top-3 scoring segments according to the different explanation methods. Best performance in bold. Second-best underlined.
- 27. Experimental results: Quantitative analysis • LIME performs consistently good for all types of fakes and numbers of segments; more effective when taking into account the top-3 scoring segments • SOBOL and SHAP are the second and third best-performing methods • The most challenging cases in terms of visual explanation, still remain the ones related with fakes of the F2F and FS classes Sufficiency of explanation methods for different types of fakes in the FaceForensics++ dataset, after performing adversarial attacks at the top-1, top-2 and top-3 scoring segments of the input image, by each explanation method. Best performance in bold. Second- best underlined.
- 28. Experimental results: Quantitative analysis • LIME performs consistently good for all types of fakes and numbers of segments; more effective when taking into account the top-3 scoring segments • SOBOL and SHAP are the second and third best-performing methods • The most challenging cases in terms of visual explanation, still remain the ones related with fakes of the F2F and FS classes Sufficiency of explanation methods for different types of fakes in the FaceForensics++ dataset, after performing adversarial attacks at the top-1, top-2 and top-3 scoring segments of the input image, by each explanation method. Best performance in bold. Second- best underlined.
- 29. Experimental results: Quantitative analysis • LIME performs consistently good for all types of fakes and numbers of segments; more effective when taking into account the top-3 scoring segments • SOBOL and SHAP are the second and third best-performing methods • The most challenging cases in terms of visual explanation, still remain the ones related with fakes of the F2F and FS classes Sufficiency of explanation methods for different types of fakes in the FaceForensics++ dataset, after performing adversarial attacks at the top-1, top-2 and top-3 scoring segments of the input image, by each explanation method. Best performance in bold. Second- best underlined.
- 30. Experimental results: Quantitative analysis • LIME performs consistently good for all types of fakes and numbers of segments; more effective when taking into account the top-3 scoring segments • SOBOL and SHAP are the second and third best-performing methods • The most challenging cases in terms of visual explanation, still remain the ones related with fakes of the F2F and FS classes Sufficiency of explanation methods for different types of fakes in the FaceForensics++ dataset, after performing adversarial attacks at the top-1, top-2 and top-3 scoring segments of the input image, by each explanation method. Best performance in bold. Second- best underlined.
- 31. Experimental results: Quantitative analysis Comparison of the obtained deepfake detection accuracy scores using our evaluation framework and the framework of Gowrisankar et al. (2024) Comparison of the obtained sufficiency scores using our evaluation framework and the framework of Gowrisankar et al. (2024) • Different frameworks lead to different outcomes about the performance and the ranking of the considered explanation methods • LIME is the best-performing method according to our framework, while the framework of Gowrisankar et al. (2024) points to SOBOL as the most effective method • The observed difference is explained by the fact that the two frameworks base their evaluations on different conditions
- 32. Experimental results: Quantitative analysis Comparison of the obtained deepfake detection accuracy scores using our evaluation framework and the framework of Gowrisankar et al. (2024) Comparison of the obtained sufficiency scores using our evaluation framework and the framework of Gowrisankar et al. (2024) • Different frameworks lead to different outcomes about the performance and the ranking of the considered explanation methods • LIME is the best-performing method according to our framework, while the framework of Gowrisankar et al. (2024) points to SOBOL as the most effective method • The observed difference is explained by the fact that the two frameworks base their evaluations on different conditions
- 33. Experimental results: Qualitative analysis LIME successfully identifies specific regions modified in each manipulation type, such as eyes and mouth in DF, nose and cheeks in F2F, left eye and cheek in FS, and mouth and chin in the NT sample Grad-CAM++ correctly focuses on regions like eyes in DF and FS, and chin in NT, but fails to clearly indicate regions in the F2F sample and misses manipulations around the mouth in the DF sample RISE produces explanations that often highlight irrelevant regions in F2F and FS, or non-manipulated in the NT sample, while also failing to spot the manipulated ones in the DF sample SHAP and SOBOL perform comparably to LIME, providing explanations that indicate altered regions in most cases
- 34. Concluding remarks • Presented a new evaluation framework for explainable deepfake detection • Measures the capacity of explanations to spot the most influential regions of the input image via adversarial image generation and evaluation that aims to flip the detector’s decision • Applied this framework on a SoA model for deepfake detection and five SoA explanation methods from the literature • Quantitative evaluations indicated the competitive performance of LIME across various types of deepfakes and different experimental settings • Qualitative analysis demonstrated the competency of LIME to provide meaningful explanations for the used deepfake detector
- 35. References • B. Malolan, A. Parekh, F. Kazi. 2020. Explainable Deep-Fake Detection Using Visual Interpretability Methods. Proc. 2020 3rd Int. Conf. on Information and Computer Technologies (ICICT). 289–293. • Y. Xu, K. Raja, M. Pedersen. 2022. Supervised Contrastive Learning for Generalizable and Explainable DeepFakes Detection. Proc. 2022 IEEE/CVF Winter Conf. on Applications of Computer Vision Workshops (WACVW). 379–389. • S. H. Silva, M. Bethany, A. M. Votto, I. H. Scarff, N. Beebe, P. Najafirad. 2022. Deepfake forensics analysis: An explainable hierarchical ensemble of weakly supervised models. Forensic Science International: Synergy 4 (2022), 100217. • K. Jayakumar, N. Skandhakumar. 2022. A Visually Interpretable Forensic Deepfake Detection Tool Using Anchors. In 2022 7th Int. Conf. on Information Technology Research (ICITR). 1–6. • A. Aghasanli, D. Kangin, P. Angelov. 2023. Interpretable-through-prototypes deepfake detection for diffusion models. In 2023 IEEE/CVF Int. Conf. on Computer Vision Workshops (ICCVW). Los Alamitos, CA, USA, 467–474. • I. U. Haq, K. M. Malik, K. Muhammad. 2023. Multimodal Neurosymbolic Approach for Explainable Deepfake Detection. ACM Trans. Multimedia Comput. Commun. Appl. • B. Gowrisankar, V.L.L. Thing. 2024. An adversarial attack approach for eXplainable AI evaluation on deepfake detection models. Computers & Security 139 (2024), 103684. • B. Zi, M. Chang, J. Chen, X. Ma, Y.-G. Jiang. 2020. WildDeepfake: A Challenging Real-World Dataset for Deepfake Detection. Proc. of the 28th ACM Int. Conf. on Multimedia (Seattle, WA, USA) (MM ’20), 2382–2390. • A. Rossler, D. Cozzolino, L. Verdoliva, C. Riess, J. Thies, M. Niessner. 2019. FaceForensics++: Learning to Detect Manipulated Facial Images. Proc. 2019 IEEE/CVF Int. Conf. on Computer Vision (ICCV). Los Alamitos, CA, USA, 1–11.
- 36. Thanks for watching! Evlampios Apostolidis, [email protected] Code and documentation publicly available at: https://github.com/IDT-ITI/XAI-Deepfakes This work was supported by the EU Horizon Europe and Horizon 2020 programmes under grant agreements 101070190 AI4TRUST and 951911 AI4Media