Exploiting GPUs in Spark
24 likes9,419 views

Kazuaki Ishizaki from IBM Tokyo discusses the exploitation of GPUs in Spark to accelerate computation-heavy applications, aiming to enhance performance without requiring users to alter their Spark programs. The presentation outlines the design and implementation of a binary columnar format and a GPU enabler, achieving a performance improvement of 3.15x for logistic regression by effectively utilizing GPU capabilities. Future directions include further integration in Spark 2.0 and beyond, targeting improvements in performance through optimized data handling and execution mechanisms.






















![Current Implementation of GPU Enabler
Execute user-provided GPU kernels from map()/reduce() functions
– GPU memory managements and data copy are automatically handled
Generate GPU native code for simple map()/reduce() methods
– “spark.gpu.codegen=true” in spark-defaults.conf
23 Exploting GPUs in Spark - Kazuaki Ishizaki
rdd1 = sc.parallelize(1 to n, 2).convert(ColumnFormat) // rdd1 uses binary columnar RDD
sum = rdd1.map(i => i * 2)
.reduce((x, y) => (x + y))
// CUDA
__global__ void sample_map(int *inX, int *inY, int *outX, int *outY, long size) {
long ix = threadIdx.x + blockIdx.x * blockDim.x;
if (size <= ix) return;
outX[ix] = inX[ix] * 2;
outY[ix] = inY[ix] – 1;
}
// Spark
mapFunction = new CUDAFunction(“sample_map", // CUDA method name
Array("this.x", "this.y"), // input object has two fields
Array("this.x“, “this.y”), // output object has two fields
this.getClass.getResource("/sample.ptx")) // ptx is generated by CUDA complier
rdd1 = sc.parallelize(…).convert(ColumnFormat) // rdd1 uses binary columnar RDD
rdd2 = rdd1.mapExtFunc(p => Pt(p.x*2, p.y‐1), mapFunction)](https://image.slidesharecdn.com/hscj2016spark-gpuishizaki-160208153842/85/Exploiting-GPUs-in-Spark-23-320.jpg)
![How to Use GPU Exploitation version
Easy to install by one-liner and to run by one-liner
– on x86_64, mac, and ppc64le with CUDA 7.0 or later with any JVM such as IBM
JDK or OpenJDK
Run script for AWS EC2 is available, which support spot instances24 Exploting GPUs in Spark - Kazuaki Ishizaki
$ wget https://s3.amazonaws.com/spark‐gpu‐public/spark‐gpu‐latest‐bin‐hadoop2.4.tgz &&
tar xf spark‐gpu‐latest‐bin‐hadoop2.4.tgz && cd spark‐gpu
$ LD_LIBRARY_PATH=/usr/local/cuda/lib64 MASTER='local[2]' ./bin/run‐example SparkGPULR 8 3200 32 5
…
numSlices=8, N=3200, D=32, ITERATIONS=5
On iteration 1
On iteration 2
On iteration 3
On iteration 4
On iteration 5
Elapsed time: 431 ms
$
Available at http://kiszk.github.io/spark-gpu/
• 3 contributors
• Private communications
with other developers](https://image.slidesharecdn.com/hscj2016spark-gpuishizaki-160208153842/85/Exploiting-GPUs-in-Spark-24-320.jpg)
![Achieved 3.15x Performance Improvement by GPU
Ran naïve implementation of logistic regression
Achieved 3.15x performance improvement of logistic regression over
without GPU on a 16-core IvyBridge box with an NVIDIA K40 GPU card
– We have rooms to improve performance
25 Exploting GPUs in Spark - Kazuaki Ishizaki
Details are available at https://github.com/kiszk/spark-gpu/wiki/Benchmark
Program parameters
N=1,000,000 (# of points), D=400 (# of features), ITERATIONS=5
Slices=128 (without GPU), 16 (with GPU)
MASTER=local[8] (without and with GPU)
Hardware and software
Machine: nx360 M4, 2 sockets 8‐core Intel Xeon E5‐2667 3.3GHz, 256GB memory, one NVIDIA K40m card
OS: RedHat 6.6, CUDA: 7.0](https://image.slidesharecdn.com/hscj2016spark-gpuishizaki-160208153842/85/Exploiting-GPUs-in-Spark-25-320.jpg)









Exploiting GPUs in Spark
- 1. Kazuaki Ishizaki IBM Research – Tokyo ⽇本アイ・ビー・エム(株)東京基礎研究所 Exploiting GPUs in Spark 1
- 2. Who am I? Kazuaki Ishizaki Research staff member at IBM Research – Tokyo – http://ibm.co/kiszk Research interests – compiler optimizations, language runtime, and parallel processing Worked for Java virtual machine and just-in-time compiler over 20 years – From JDK 1.0 to Java SE 8 Twitter: @kiszk Slideshare: http://www.slideshare.net/ishizaki Github: https://github.com/kiszk 2 Exploting GPUs in Spark - Kazuaki Ishizaki
- 3. Agenda Motivation & Goal Introduction of GPUs Design & New Components – Binary columnar – GPU enabler Current Implementation Performance Experiment – Achieved 3.15x performance of a naïve logistic regression by using a GPU Future Direction in Spark 2.0 and beyond – with Dataset (introduced in Spark 1.6) Conclusion 3 Exploting GPUs in Spark - Kazuaki Ishizaki
- 4. Want to Accelerate Computation-heavy Application Motivation – Want to shorten execution time of a long-running Spark application Computation-heavy Shuffle-heavy I/O-heavy Goal – Accelerate a Spark computation-heavy application According to Reynold’s talk (p. 21), CPU will become bottleneck on Spark 4 Exploting GPUs in Spark - Kazuaki Ishizaki
- 5. Accelerate a Spark Application by GPUs Approach – Accelerate a Spark application by using GPUs effectively and transparently Exploit high performance of GPUs Do not ask users to change their Spark programs New components – Binary columnar – GPU enabler 5 Exploting GPUs in Spark - Kazuaki Ishizaki
- 6. Motivation & Goal Introduction of GPUs Design & New Components Current Implementation Performance Experiment Future Direction in Spark 2.0 and beyond Conclusion
- 7. GPU Programming Model Five steps 1. Allocate GPU device memory 2. Copy data on CPU main memory to GPU device memory 3. Launch a GPU kernel to be executed in parallel on cores 4. Copy back data on GPU device memory to CPU main memory 5. Free GPU device memory Usually, a programmer has to write these steps in CUDA or OpenCL 7 Exploting GPUs in Spark - Kazuaki Ishizaki device memory (up to 12GB) main memory (up to 1TB/socket) CPU GPU Data copy over PCIe dozen cores/socket thousands cores
- 8. How We Can Run Program Faster on GPU Assign a lot of parallel computations into cores Make memory accesses coalesced – An example – Column-oriented layout achieves better performance This paper reports about 3x performance improvement of GPU kernel execution of kmeans over row-oriented layout 8 Exploting GPUs in Spark - Kazuaki Ishizaki 1 52 61 5 3 7 Assumption: 4 consecutive data elements can be coalesced by GPU hardware 2 v.s. 4 memory accesses to GPU device memory Row-oriented layoutColumn-oriented layout Pt(x: Int, y: Int) Load four Pt.x Load four Pt.y 2 6 4 843 87 coresx1 x2 x3 x4 cores Load Pt.x Load Pt.y Load Pt.x Load Pt.y 1 2 31 2 4 y1 y2 y3 y4 x1 x2 x3 x4 y1 y2 y3 y4
- 9. Motivation & Goal Introduction of GPUs Design & New Components Current Implementation Performance Experiment Future Direction in Spark 2.0 and beyond Conclusion
- 10. Design of GPU Exploitation Efficient – Reduce data copy overhead between CPU and GPU – Make memory accesses efficient on GPU Transparent – Map parallelism in a program into GPU native code User’s Spark Program (scala) 10 case class Pt(x: Int, y: Int) rdd1 = sc.parallelize(Array( Pt(1, 4), Pt(2, 5), Pt(3, 6), Pt(4, 7), Pt(5, 8), Pt(6, 9)), 3) rdd2 = rdd1.map(p => Pt(p.x*2, p.y‐1)) cnt = rdd2.reduce( (p1, p2) => p1.x + p2.x) Translate to GPU native code Nativecode 1 GPU 4 2 5 3 6 4 7 5 8 6 9 1 4 2 5 3 6 4 7 5 8 6 9 2 3 4 4 6 5 8 6 10 7 12 8 2 3 4 4 6 5 8 6 10 7 12 8 *2= -1= rdd 1 Data transfer x y Exploting GPUs in Spark - Kazuaki Ishizaki GPU enabler binary columnar Off-heap x y GPU can exploit parallelism both among blocks in RDD and within a block of RDD rdd 2 block GPU kernel CPU
- 11. What Binary Columnar does? Keep data as binary representation (not Java object representation) Keep data as column-oriented layout Keep data on off-heap or GPU device memory 11 Exploting GPUs in Spark - Kazuaki Ishizaki 2 51 4 Off-heap case class Pt(x: Int, y: Int) Array(Pt(1, 4), Pt(2, 5)) Example 2 51 4 Off-heap Columnar (column-oriented) Row-oriented
- 12. Current RDD as Java objects on Java heap 12 Exploting GPUs in Spark - Kazuaki Ishizaki case class Pt(x: Int, y: Int) rdd = sc.parallelize(Array(Pt(1, 4), Pt(2, 5))) Object header for Java virtual machine 1 4 2 5 Java heap Current RDD Row-oriented layout Java object representation On Java heap Pt Pt
- 13. Binary Columnar RDD on off-heap 13 Exploting GPUs in Spark - Kazuaki Ishizaki case class Pt(x: Int, y: Int) rdd = sc.parallelize(Array(Pt(1, 4), Pt(2, 5))) Object header for Java virtual machine 1 4 2 5 Java heap Off-heap 2 51 4 Current RDD Row-oriented layout Java object representation On Java heap Binary columnar RDD Column-oriented layout Binary representation On off-heap
- 14. 2.1. Long Path from Current RDD to GPU Three steps to send data from RDD to GPU 1. Java objects to column-oriented binary representation on Java heap From a Java object to binary representation From a row-oriented format to columnar 2. Binary representation on Java heap to binary columnar on off-heap Garbage collection may move objects on Java heap during GPU related operations 3. Off-heap to GPU device memory 14 Exploting GPUs in Spark - Kazuaki Ishizaki case class Pt(x: Int, y: Int) rdd = sc.parallelize(Array(Pt(1, 4),Pt(2, 5))) rdd.map(…).reduce(…) // execute on GPU 1 4 2 5 2 51 4 2 51 4 2 51 4 Off-heap GPU device memoryJava heap Java heap This thread in dev ML also discusses overhead of copying data between RDD and GPU 3. Pt Pt ByteBuffer ByteBuffer
- 15. Short Path from Binary Columnar RDD to GPU RDD with binary columnar can be simply copied to GPU device memory 15 Exploting GPUs in Spark - Kazuaki Ishizaki case class Pt(x: Int, y: Int) rdd = sc.parallelize(Array(Pt(1, 4),Pt(2, 5))) rdd.map(…).reduce(…) // execute on GPU Off-heap GPU device memory Eliminated 2 51 4 2 51 4 1 4 2 5 2 51 4 2 51 4 Off-heap GPU device memoryJava heap 2 51 4 Java heap
- 16. Can Execute map() in Parallel Using Binary Columnar Adjacent elements in binary columnar RDD can be accessed in parallel The same type of operations ( * or -) can be executed in parallel for data to be loaded in parallel 16 Exploting GPUs in Spark - Kazuaki Ishizaki case class Pt(x: Int, y: Int) rdd = sc.parallelize(Array(Pt(1, 4), Pt(2, 5))) rdd1= rdd1.map(p => Pt(p.x*2, p.y‐1)) 1 4 2 5 Java heap Off-heap 2 51 4 Current RDD Binary columnar RDD Memory access order 1 2 3 4 1 1 2 2
- 17. Advantages of Binary Columnar Can exploit high performance of GPUs Can reduce overhead of data copy between CPU and GPU Consume less memory footprint Can directly compute data, which are stored in columnar, from Apache Parquet Can exploit SIMD instructions on CPU 17 Exploting GPUs in Spark - Kazuaki Ishizaki
- 18. What GPU Enabler Does? Copy data in binary columnar RDD between CPU main memory and GPU device memory Launch GPU kernels Cache GPU native code for kernels Generate GPU native code from transformations and actions in a program – We already productized the IBM Java just-in-time compiler that generate GPU native code from a lambda expression in Java 8 18 Exploting GPUs in Spark - Kazuaki Ishizaki
- 19. Motivation & Goal Introduction of GPUs Design & New Components Current Implementation Performance Experiment Future Direction in Spark 2.0 and beyond Conclusion
- 20. Software Stack in Current Spark 2.0-SNAPSHOT RDD keeps data on Java heap 20 Exploting GPUs in Spark - Kazuaki Ishizaki RDD API Java heap RDD data User’s Spark program
- 21. Off-heap Software Stack of GPU Exploitation Current RDD and binary columnar RDD co-exist 21 Exploting GPUs in Spark - Kazuaki Ishizaki RDD API Java heap RDD data User’s Spark program Columnar GPU enabler GPU device memory Columnar
- 22. Current Implementation of Binary Columnar Work with RDD Convert from current RDD to binary columnar RDD and vice versa – Our current implementation eliminates conversion overhead between CPU and GPU in a task 22 Exploting GPUs in Spark - Kazuaki Ishizaki
- 23. Current Implementation of GPU Enabler Execute user-provided GPU kernels from map()/reduce() functions – GPU memory managements and data copy are automatically handled Generate GPU native code for simple map()/reduce() methods – “spark.gpu.codegen=true” in spark-defaults.conf 23 Exploting GPUs in Spark - Kazuaki Ishizaki rdd1 = sc.parallelize(1 to n, 2).convert(ColumnFormat) // rdd1 uses binary columnar RDD sum = rdd1.map(i => i * 2) .reduce((x, y) => (x + y)) // CUDA __global__ void sample_map(int *inX, int *inY, int *outX, int *outY, long size) { long ix = threadIdx.x + blockIdx.x * blockDim.x; if (size <= ix) return; outX[ix] = inX[ix] * 2; outY[ix] = inY[ix] – 1; } // Spark mapFunction = new CUDAFunction(“sample_map", // CUDA method name Array("this.x", "this.y"), // input object has two fields Array("this.x“, “this.y”), // output object has two fields this.getClass.getResource("/sample.ptx")) // ptx is generated by CUDA complier rdd1 = sc.parallelize(…).convert(ColumnFormat) // rdd1 uses binary columnar RDD rdd2 = rdd1.mapExtFunc(p => Pt(p.x*2, p.y‐1), mapFunction)
- 24. How to Use GPU Exploitation version Easy to install by one-liner and to run by one-liner – on x86_64, mac, and ppc64le with CUDA 7.0 or later with any JVM such as IBM JDK or OpenJDK Run script for AWS EC2 is available, which support spot instances24 Exploting GPUs in Spark - Kazuaki Ishizaki $ wget https://s3.amazonaws.com/spark‐gpu‐public/spark‐gpu‐latest‐bin‐hadoop2.4.tgz && tar xf spark‐gpu‐latest‐bin‐hadoop2.4.tgz && cd spark‐gpu $ LD_LIBRARY_PATH=/usr/local/cuda/lib64 MASTER='local[2]' ./bin/run‐example SparkGPULR 8 3200 32 5 … numSlices=8, N=3200, D=32, ITERATIONS=5 On iteration 1 On iteration 2 On iteration 3 On iteration 4 On iteration 5 Elapsed time: 431 ms $ Available at http://kiszk.github.io/spark-gpu/ • 3 contributors • Private communications with other developers
- 25. Achieved 3.15x Performance Improvement by GPU Ran naïve implementation of logistic regression Achieved 3.15x performance improvement of logistic regression over without GPU on a 16-core IvyBridge box with an NVIDIA K40 GPU card – We have rooms to improve performance 25 Exploting GPUs in Spark - Kazuaki Ishizaki Details are available at https://github.com/kiszk/spark-gpu/wiki/Benchmark Program parameters N=1,000,000 (# of points), D=400 (# of features), ITERATIONS=5 Slices=128 (without GPU), 16 (with GPU) MASTER=local[8] (without and with GPU) Hardware and software Machine: nx360 M4, 2 sockets 8‐core Intel Xeon E5‐2667 3.3GHz, 256GB memory, one NVIDIA K40m card OS: RedHat 6.6, CUDA: 7.0
- 26. Motivation & Goal Introduction of GPUs Design & New Components Current Implementation Performance Experiment Future Direction in Spark 2.0 and beyond Conclusion
- 27. Comparisons among DataFrame, Dataset, and RDD DataFrame (with relational operations) and Dataset (with lambda functions) use Catalyst and row-oriented data representation on off-heap 27 Exploting GPUs in Spark - Kazuaki Ishizaki ds = d.toDS() ds.filter(p => p.x>1) .count() 1 4 2 5 Java heap rdd = sc.parallelize(d) rdd.filter(p => p.x>1) .count() df = d.toDF(…) df.filter(”x>1”) .count() case class Pt(x: Int, y: Int) d = Array(Pt(1, 4), Pt(2, 5)) Frontend API 2 51 4 Off-heap Data DataFrame (v1.3-) Dataset (v1.6-) RDD (v0.5-) Catalyst Backend computation Generated Java bytecode Java bytecode in Spark program and runtime Row-oriented Row-oriented
- 28. Design Concepts of Dataset and GPU Exploitation Keep data as binary representation Keep data on off-heap Take advantages of Catalyst optimizer 28 Exploting GPUs in Spark - Kazuaki Ishizaki 2 51 4 Off-heap case class Pt(x: Int, y: Int) sc.parallelize(Array(Pt(1, 4),Pt(2, 5))) Comparison of data representations 2 51 4 Off-heap case class Pt(x: Int, y: Int) ds = (Pt(1, 4),Pt(2, 5)).toDS() How can we apply binary columnar and GPU enabler to Dataset? Dataset Binary columnar RDD Binary columnar also does GPU enabler could use Row-oriented Columnar
- 29. GPU kernel launcher Column Encoder Binary Encoder In-memory storage Components in GPU Exploitation Binary columnar – Columnar In-memory storage keeps data in binary representation on off-heap or GPU memory BinaryEncoder converts a data representation between a Java object and binary format ColumnEncoder puts a set of data elements as column-oriented layout – Memory Manager Manage off-heap and GPU memory Columnar cache manages persistency of in-memory storage GPU enabler – GPU kernel launcher Launch kernels with data copy Caching GPU binary for kernels – GPU code generator Generate GPU code from Spark program 29 Exploting GPUs in Spark - Kazuaki Ishizaki Columnar cache GPU code generator Pre-compiled libraries for GPU Memory Manager Columnar GPU memory Off-heap memory
- 30. Software Stack in Spark 2.0 and Beyond Dataset will become a primary data structure for computation Dataset keeps data in UnsafeRow on off-heap 30 Exploting GPUs in Spark - Kazuaki Ishizaki DataFrame Dataset Tungsten Catalyst Off-heap UnsafeRow User’s Spark program Logical optimizer CPU code generator
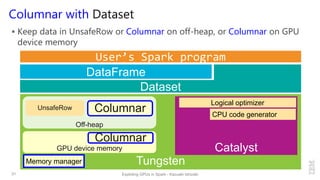
- 31. Columnar with Dataset Keep data in UnsafeRow or Columnar on off-heap, or Columnar on GPU device memory 31 Exploting GPUs in Spark - Kazuaki Ishizaki User’s Spark program DataFrame Dataset Tungsten Catalyst Off-heap UnsafeRow GPU device memory Columnar Logical optimizer Memory manager CPU code generator Columnar
- 32. Two Approaches for Binary Columnar with Dataset Binary Columnar as a first-class citizen – Better end-to-end performance in a job without conversion – Need more code changes to the existing source code Binary Columnar as a cache in a task – Produce overhead of representation conversions between two tasks at shuffle – Need less code changes to the existing source code 32 Exploting GPUs in Spark - Kazuaki Ishizaki ds1 = d.toDS() ds2 = ds1.map(…) ds11 = ds3.groupby(…) ds3 = ds2.map(…) ds12 = ds11.map(…) As a first-class citizen task1 task2 As a cache shuffle
- 33. GPU Support in Tungsten According to Reynold’s talk (p. 25), Tungsten backend has a plan to enable GPU exploitation Exploiting GPUs in Spark - Kazuaki Ishizaki33
- 34. GPU Enabler in Catalyst Place GPU kernel launcher and GPU code generator into Catalyst 34 Exploting GPUs in Spark - Kazuaki Ishizaki User’s Spark program DataFrame Dataset Tungsten Catalyst Off-heap UnsafeRow GPU device memory Columnar Logical optimizer Memory manager CPU code generator GPU code generatorGPU kernel launcher Columnar
- 35. Future Direction Do refactoring to make current implementation decomposable – Some components exist in one Scala file Make pull requests for each component – to support columnar Dataset – to exploit GPUs 35 Exploting GPUs in Spark - Kazuaki Ishizaki Memory Manager Columnar Binary encoder Column encoder In-memory storage Memory manager Cache manager As a cache in task As a first- class citizen Multiple backend support CPU code generator for Columnar CPU code generator for Columnar GPU kernel launcher Column Encoder Binary Encoder In-memory storageColumnar cache GPU code generator GPU memory Off-heap memory Roadmap for pull requests Off-heap Catalyst
- 36. Takeaway Accelerate a Spark application by using GPUs effectively and transparently Devised two New components – Binary columnar to alleviate overhead for GPU exploitation – GPU enabler to manage GPU kernel execution from a Spark program Call pre-compiled libraries for GPU Generate GPU native code at runtime Available at http://kiszk.github.io/spark-gpu/ 36 Component Initial design (Spark 1.3-1.5) Current status (Spark 2.0-Snapshot) Future (Spark 2.x) Binary columnar with RDD with RDD with Dataset GPU enabler launch GPU kernels generate GPU native code launch GPU kernels generate GPU native code in Catalyst Exploting GPUs in Spark - Kazuaki Ishizaki Appreciate any your feedback and contributions