Exploring KSQL Patterns
Download as PPTX, PDF2 likes1,461 views

Tim Berglund, a senior director at Confluent, discusses ksql, the streaming SQL engine for Apache Kafka, focusing on its features like stream and table creation, usage patterns for streaming ETL, anomaly detection, and real-time monitoring. The session covers practical examples, including how to create and inspect streams and tables, as well as deployment patterns for ksql. Resources for further exploration are provided, including links to GitHub and the Confluent community.




























Exploring KSQL Patterns
- 1. 1
- 2. 2 Tim is a teacher, author and technology leader with Confluent. He is not only an expert on KSQL but he can also frequently be found speaking at conferences in the United States and all over the world. He is the co-presenter of various O’Reilly training videos on topics ranging from Git to Distributed Systems, and he is the author of Gradle Beyond the Basics. Tim Berglund Senior Director of Developer Experience, Confluent
- 3. 3 Housekeeping Items ● This session will last about an hour. ● It will be recorded. ● You can submit your questions by entering them into the GoToWebinar panel. ● The last 10 minutes will consist of Q&A. ● The slides and recording will be available after the talk.
- 8. KSQL Concepts • Streams are first-class citizens • Tables are first-class citizens • Some queries are persistent • All queries run until terminated
- 9. CREATE STREAM clickstream WITH ( value_format = ‘JSON’, kafka_topic=‘my_clickstream_topic’ ); Creating a Stream • Let’s say we have a topic called my_clickstream_topic • The topic contains JSON data • KSQL now knows about that topic
- 10. Exploring that Stream SELECT status, bytes FROM clickstream WHERE user_agent = ‘Mozilla/5.0 (compatible; MSIE 6.0)’; • Now that the stream exists, we can examine its contents • Simple, declarative filtering • A non-persistent query
- 11. CREATE TABLE users WITH ( key = ‘user_id', kafka_topic=‘clickstream_users’, value_format=‘JSON’ ); Creating a Table • We have a topic called my_clickstream_topic • The topic contains JSON data • The topic contains changelog data
- 12. Inspecting that Table SELECT userid, username FROM users WHERE level = ‘Platinum’; • Now that the table exists, we can examine its contents • Simple, declarative filtering • A non-persistent query
- 13. Joining a Stream to a Table • Now that we have clickstream and users, we can join them • This allows us to do filtering of clicks on a user attribute CREATE STREAM vip_actions AS SELECT userid, page, action FROM clickstream c LEFT JOIN users u ON c.userid = u.user_id WHERE u.level = 'Platinum';
- 14. Usage Patterns
- 15. KSQL for Streaming ETL • Kafka is popular for data pipelines. • KSQL enables easy transformations of data within the pipe. • Transforming data while moving from Kafka to another system. CREATE STREAM vip_actions AS SELECT userid, page, action FROM clickstream c LEFT JOIN users u ON c.userid = u.user_id WHERE u.level = 'Platinum';
- 16. KSQL for Anomaly Detection CREATE TABLE possible_fraud AS SELECT card_number, count(*) FROM authorization_attempts WINDOW TUMBLING (SIZE 5 SECONDS) GROUP BY card_number HAVING count(*) > 3; Identifying patterns or anomalies in real-time data, surfaced in milliseconds
- 17. KSQL for Real-Time Monitoring• Log data monitoring, tracking and alerting • Sensor / IoT data CREATE TABLE error_counts AS SELECT error_code, count(*) FROM monitoring_stream WINDOW TUMBLING (SIZE 1 MINUTE) WHERE type = 'ERROR' GROUP BY error_code;
- 18. KSQL for Data Transformation CREATE STREAM views_by_userid WITH (PARTITIONS=6, VALUE_FORMAT=‘JSON’, TIMESTAMP=‘view_time’) AS SELECT * FROM clickstream PARTITION BY user_id; Make simple derivations of existing topics from the command line
- 19. Demo
- 21. Kafka Cluster JVM KSQL ServerKSQL CLI KSQL in Local Mode
- 22. • Starts a CLI and a server in the same JVM • Ideal for developing on your laptop bin/ksql-cli local • Or with customized settings bin/ksql-cli local --properties-file ksql.properties KSQL in Local Mode
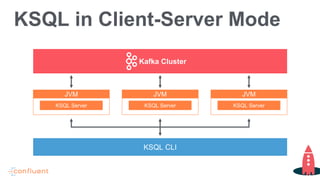
- 23. KSQL in Client-Server Mode JVM KSQL Server KSQL CLI JVM KSQL Server JVM KSQL Server Kafka Cluster
- 24. • Start any number of server nodes bin/ksql-server-start • Start one or more CLIs and point them to a server bin/ksql-cli remote https://myksqlserver:8090 • All servers share the processing load Technically, instances of the same Kafka Streams Applications Scale up/down without restart KSQL in Client-Server Mode
- 25. KSQL in Application Mode Kafka Cluster JVM KSQL Server JVM KSQL Server JVM KSQL Server
- 26. • Start any number of server nodes Pass a file of KSQL statement to execute bin/ksql-node query-file=foo/bar.sql • Ideal for streaming ETL application deployment Version-control your queries and transformations as code • All running engines share the processing load Technically, instances of the same Kafka Streams Applications Scale up/down without restart KSQL in Application Mode
- 27. Resources and Next Steps https://github.com/confluentinc/ksql http://confluent.io/ksql https://slackpass.io/confluentcommunity #ksql
- 28. 29
- 29. 30 Thank you for attending Exploring KSQL Patterns.
Editor's Notes
- #5: Really, stream processing is still a pretty new discipline. We are only on the second generation of OSS tooling (depending on how you look at things), and most people who are building streaming systems are building their first. As a result, most stream processing requires a bunch of custom code, often deployed to specialized infrastructure, coded against specialized APIs. And hey, sometimes that’s what you gotta do, but having a declarative language and getting infrastructure problems out of your way is a good thing. KSQL aims to do both things.
- #6: Another way to put that, is that KSQL is a SQL engine for Kafka. It’s not a subset of ANSI SQL—it can’t be, since streaming systems deal with unbounded data sets and relational databases are fundamentally about bounded data sets, and that difference matters—but man, how great would it be to have a SQL-like language to describe stream processing computation you want done to the data you have stored in Kafka topics? (If you don’t know Kafka already, it’s a messaging system, and topics are just queues of messages. Basic stuff here, and don’t let it confuse you if you’re new to all of this.)
- #7: Where does it fit into my system? What is the language syntax like?
- #8: architecture diagram stuff goes into Kafka, KSQL processes it, it goes out KSQL takes the place of more complex options that have preceded it, like the Streams API or the Producer and Consumer API.
- #9: KSQL is familiar, but is also different in important ways. What is a stream? An unbounded sequence of facts. What is a table? A collection of evolving facts. We’ll see examples. Queries tend to run until you stop them. This is counterintuitive, but remember we’re dealing with streaming data here. There’s never a “last” record. Persistent queries are really stream processing programs that run in KSQL.
- #10: Ok, so we want to make ourselves a stream out of a topic we have in Kafka, how to start ? This is a lightweight abstraction on top of the topic. Note that the stream has metadata, but the metadata is extracted automatically from the topic.
- #11: It’s not an ad-hoc query language as such, but since you can define stream processing jobs with it, it’s certainly possible to use it to arbitrary filtering and projection on existing topics. You have to create streams first, fo course, but we’ve gone over that now.
- #12: Creating a table. Note that this is fundamentally tabular data: the key is the user_id, so each message in the topic is an update to that user’s record. We don’t need to specify the metadata, because it gets sucked in from the topic.
- #13: It’s not an ad-hoc query language as such, but since you can define stream processing jobs with it, it’s certainly possible to use it to arbitrary filtering and projection on existing topics. You have to create streams first, fo course, but we’ve gone over that now.
- #16: On the third bullet: often people build streaming pipelines with Kafka dumping data into C* or Elastic. Well, you’re probably going to need to do some work on the data along the way. No need to have a Spark Streaming job running now!
- #19: KSQL also turns out to be super-useful for housekeeping and administrative actions that would otherwise require a stream-transforming program of some sort to be written and tested, or changes in the underlying source data ssytems to produce to a topic in a different format in the first place. In this example we’re simply: taking all the records from the ‘clickstream’ topic and copying them into a new ‘views_by_userid’ topic, which we’ve asked to be written out in json format (notice that the inout stream could be in any other format KSQL can read), and explicitly asked for there to be 6 partitions of this output topic, for the record timestamps to be populated from the value of the ‘view_time’ field in the input topic And finally, the records should be distributed across the 6 partitions based on their ‘user_id’ All the options we’re specifying here have sensible defaults and can be omitted if you don’t want or need to override them
- #20: 4
- #22: When we’re looking to select tools for solving a particular tech problem in front of us we are always making trade-offs. In kafka-land, one interesting set of trade-offs to consider is this, fairly typical, spectrum: ranging from very flexible and low-level on the left side, using the original kafka client producer and consumer APIs – think of this as being at the level of ‘get-message’, ‘put message’ and you of course have to take care of many details of orchestrating these reads and writes yourself; up through something like the kafka streams api, shown in the center here, where we can hide a lot of lower-level implementation concerns and focus on using functions which operate on a stream of records as a whole – perhaps filtering or transforming every record that passes by in a more functional-programming style. The real shift when using this is in mindset, to a place where you think of passing functions to be run against everything in a stream rather than strictly iterating over the stream yourself. KSQL shifts it up another gear to a place where we can declaratively transform one or more streams into another stream, using syntax and ideas that may be more familiar. Notice how, as we go from left to right on this spectrum, each thing builds upon the preceding one – both conceptually and also literally in terms of implementation – each of these APIs is built around the preceding one
- #27: Leave resource mgmt. to dedicated systems such as k8s All running Engines share the processing load Technically, instances of the same Kafka Streams Applications Scale up/down without restart
- #29: This is open source, and you should get involved. You can check out the code on GitHub or play with the many examples there. Also, you are hereby solemnly adjured to join the Slack community and ask questions there!