Fast Access to Your Data - Avro, JSON, ORC, and Parquet
Download as PPTX, PDF•5 likes•1,085 views

The document discusses benchmarking for Spark SQL using various file formats including Avro, JSON, ORC, and Parquet, highlighting their strengths and weaknesses through real data sets. It emphasizes the importance of performance measures such as read speeds and compression efficiency among these formats while providing recommendations for data handling and configuration. The findings include performance comparisons, particularly noting that JSON performs poorly in read speed, while ORC and Parquet exhibit advantages in specific scenarios.









































Fast Access to Your Data - Avro, JSON, ORC, and Parquet
- 1. Fast Spark Access To Your Data - Avro, JSON, ORC, and Parquet Owen O’Malley [email protected] @owen_omalley September 2018
- 2. 2 © Hortonworks Inc. 2011 – 2018. All Rights Reserved Who Am I? Worked on Hadoop since Jan 2006 MapReduce, Security, Hive, and ORC Worked on different file formats –Sequence File, RCFile, ORC File, T-File, and Avro requirements
- 3. 3 © Hortonworks Inc. 2011 – 2018. All Rights Reserved Goal Benchmark for Spark SQL –Use Spark’s FileFormat API Seeking to discover unknowns –How do the different formats perform? –What could they do better? Use real & diverse data sets –Over-reliance on artificial datasets leads to weakness Open & reviewed benchmarks
- 4. 4 © Hortonworks Inc. 2011 – 2018. All Rights Reserved Benchmarking is Hard Is this a good benchmark? long start = System.nanoTime(); testMethod(new A()); long middle = System.nanoTime(); testMethod(new B()); long end = System.nanoTime();
- 5. 5 © Hortonworks Inc. 2011 – 2018. All Rights Reserved JMH to the Rescue Interfaces to JVM Launches fork as requested Runs warmup iterations Runs multiple iterations Provides parameter sweeps Provides blackholes
- 6. 6 © Hortonworks Inc. 2011 – 2016. All Rights Reserved The File Formats
- 7. 7 © Hortonworks Inc. 2011 – 2018. All Rights Reserved Avro Cross-language file format for Hadoop Schema evolution was primary goal Schema segregated from data –Unlike Protobuf and Thrift Row major format
- 8. 8 © Hortonworks Inc. 2011 – 2018. All Rights Reserved JSON Serialization format for HTTP & Javascript Text-format with MANY parsers Schema completely integrated with data Row major format Compression applied on top
- 9. 9 © Hortonworks Inc. 2011 – 2018. All Rights Reserved ORC Originally part of Hive to replace RCFile –Now top-level project Schema segregated into footer Column major format with stripes Rich type model, stored top-down Integrated compression, indexes, & stats
- 10. 10 © Hortonworks Inc. 2011 – 2018. All Rights Reserved Parquet Design based on Google’s Dremel paper Schema segregated into footer Column major format with stripes Simpler type-model with logical types All data pushed to leaves of the tree
- 11. 11 © Hortonworks Inc. 2011 – 2016. All Rights Reserved Data Sets
- 12. 12 © Hortonworks Inc. 2011 – 2018. All Rights Reserved NYC Taxi Data Every taxi cab ride in NYC from 2009 –Publically available –http://tinyurl.com/nyc-taxi-analysis 18 columns with no null values –Doubles, integers, decimals, & strings 2 months of data – 22.7 million rows
- 13. 13 © Hortonworks Inc. 2011 – 2018. All Rights Reserved Sales Generated data –Real schema from a production Hive deployment –Random data based on the data statistics 55 columns with lots of nulls –A little structure –Timestamps, strings, longs, booleans, list, & struct 25 million rows
- 14. 14 © Hortonworks Inc. 2011 – 2018. All Rights Reserved Github Logs All actions on Github public repositories –Publically available –https://www.githubarchive.org/ 704 columns with a lot of structure & nulls –Pretty much the kitchen sink 1/2 month of data – 10.5 million rows
- 15. 15 © Hortonworks Inc. 2011 – 2018. All Rights Reserved Finding the Github Schema The data is all in JSON. No schema for the data is published. We wrote a JSON schema discoverer. –Scans the document and figures out the types Available in ORC tool jar. Schema is huge (12k)
- 16. 16 © Hortonworks Inc. 2011 – 2016. All Rights Reserved Software
- 17. 17 © Hortonworks Inc. 2011 – 2018. All Rights Reserved Software Versions All of these projects are evolving rapidly –Spark 2.3.1 –Avro 1.8.2 –ORC 1.5.1 –Parquet 1.8.2 –Spark-Avro 4.0.0 Dependency hell 👿
- 18. 18 © Hortonworks Inc. 2011 – 2018. All Rights Reserved Configuration Spark Configuration –spark.sql.orc.filterPushdown = true –spark.sql.orc.impl = native Hadoop Configuration –session.sparkContext().hadoopConfiguration() –avro.mapred.ignore.inputs.without.extension = false
- 19. 19 © Hortonworks Inc. 2011 – 2018. All Rights Reserved Spark-Avro Benchmark uses Spark SQL’s FileFormat –JSON, ORC, and Parquet all in Spark –Avro is provided by Databricks via spark-avro It maps the Spark to Avro types differently –Timestamp as long vs int96 –Decimal as string vs bytes
- 20. 20 © Hortonworks Inc. 2011 – 2016. All Rights Reserved Storage costs
- 21. 21 © Hortonworks Inc. 2011 – 2018. All Rights Reserved Compression Data size matters! –Hadoop stores all your data, but requires hardware –Is one factor in read speed (HDFS ~15mb/sec) ORC and Parquet use RLE & Dictionaries All the formats have general compression –ZLIB (GZip) – tight compression, slower –Snappy – some compression, faster
- 22. 22 © Hortonworks Inc. 2011 – 2018. All Rights Reserved
- 23. 23 © Hortonworks Inc. 2011 – 2018. All Rights Reserved Taxi Size Analysis Don’t use JSON Use either Snappy or Zlib compression Avro’s small compression window hurts Parquet Zlib is smaller than ORC
- 24. 24 © Hortonworks Inc. 2011 – 2018. All Rights Reserved
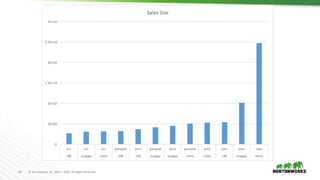
- 25. 25 © Hortonworks Inc. 2011 – 2018. All Rights Reserved Sales Size Analysis ORC did better than expected –String columns have small cardinality –Lots of timestamp columns –No doubles
- 26. 26 © Hortonworks Inc. 2011 – 2018. All Rights Reserved
- 27. 27 © Hortonworks Inc. 2011 – 2018. All Rights Reserved Github Size Analysis Surprising win for JSON and Avro –Worst when uncompressed –Best with zlib Many partially shared strings –ORC and Parquet don’t compress across columns Need to investigate Zstd with dictionary
- 28. 28 © Hortonworks Inc. 2011 – 2016. All Rights Reserved Use Cases
- 29. 29 © Hortonworks Inc. 2011 – 2018. All Rights Reserved Full Table Scans Read all columns & rows All formats except JSON are splittable –Different workers do different parts of file Taxi schema supports ColumnarBatch –All primitive types
- 30. 30 © Hortonworks Inc. 2011 – 2018. All Rights Reserved 0 50 100 150 200 250 300 350 orc parquet json orc parquet json orc parquet taxi taxi taxi taxi taxi taxi taxi taxi none none none zlib zlib zlib snappy snappy Taxi Times
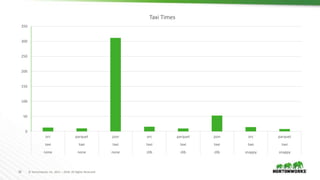
- 31. 31 © Hortonworks Inc. 2011 – 2018. All Rights Reserved Taxi Read Performance Analysis JSON is very slow to read –Large storage size for this data set –Needs to do a LOT of string parsing Parquet is faster –ORC is going through an extra layer –VectorizedRowBatch -> OrcStruct -> ColumnarBatch
- 32. 32 © Hortonworks Inc. 2011 – 2018. All Rights Reserved 0 50 100 150 200 250 300 350 400 orc parquet json orc parquet orc parquet sales sales sales sales sales sales sales none none none zlib zlib snappy snappy Sales Times
- 33. 33 © Hortonworks Inc. 2011 – 2018. All Rights Reserved Sales Read Performance Analysis Read performance is dominated by format –Compression matters less for this data set –Straight ordering: ORC, Parquet, & JSON Uses Row instead of ColumnarBatch
- 34. 34 © Hortonworks Inc. 2011 – 2018. All Rights Reserved 0 100 200 300 400 500 600 700 800 900 1000 orc parquet json orc parquet orc parquet github github github github github github github none none none zlib zlib snappy snappy Github Times
- 35. 35 © Hortonworks Inc. 2011 – 2018. All Rights Reserved Github Read Performance Analysis JSON did really well A lot of columns needs more space –We need bigger stripes (add min rows in ORC-190) –Rows/stripe - ORC: 18.6k, Parquet: 88.1k Parquet struggles –Twitter recommends against Parquet for this case
- 36. 36 © Hortonworks Inc. 2011 – 2018. All Rights Reserved Column Projection Often just need a few columns –Only ORC & Parquet are columnar –Only read, decompress, & deserialize some columns Spark FileFormat passes in desired schema –Drop columns that aren’t needed –JSON and Avro read first and then drop columns
- 37. 37 © Hortonworks Inc. 2011 – 2018. All Rights Reserved 0 2 4 6 8 10 12 14 16 18 20 none snappy zlib none snappy zlib none snappy zlib none snappy zlib none snappy zlib none snappy zlib orc orc orc parquet parquet parquet orc orc orc parquet parquet parquet orc orc orc parquet parquet parquet github github github github github github sales sales sales sales sales sales taxi taxi taxi taxi taxi taxi Column Projection % Sizes
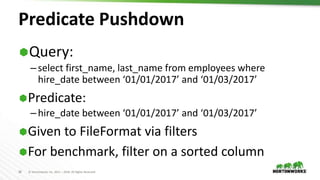
- 38. 38 © Hortonworks Inc. 2011 – 2018. All Rights Reserved Predicate Pushdown Query: –select first_name, last_name from employees where hire_date between ‘01/01/2017’ and ‘01/03/2017’ Predicate: –hire_date between ‘01/01/2017’ and ‘01/03/2017’ Given to FileFormat via filters For benchmark, filter on a sorted column
- 39. 39 © Hortonworks Inc. 2011 – 2018. All Rights Reserved Predicate Pushdown ORC & Parquet indexes with min & max –Sorted data is critical! ORC has optional bloom filters Reader filters out sections of file –Entire file –Stripe –Row group (only ORC, default 10k rows) Engine needs to apply row level filter
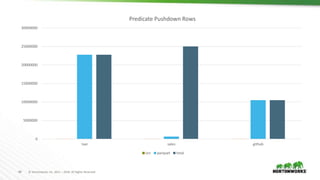
- 40. 40 © Hortonworks Inc. 2011 – 2018. All Rights Reserved 0 5000000 10000000 15000000 20000000 25000000 30000000 taxi sales github Predicate Pushdown Rows orc parquet total
- 41. 41 © Hortonworks Inc. 2011 – 2018. All Rights Reserved Predicate Pushdown Parquet doesn’t pushdown timestamp filters –Taxi and Github filters were on timestamps. Spark defaults ORC predicate pushdown off. Small ORC stripes for Github lead to sub-10k row read. Because predicate pushdown is an optimization, it isn’t clear when it isn’t used.
- 42. 42 © Hortonworks Inc. 2011 – 2018. All Rights Reserved Metadata Access ORC & Parquet store metadata –Stored in file footer –File schema –Number of records –Min, max, count of each column Provides O(1) Access
- 43. 43 © Hortonworks Inc. 2011 – 2016. All Rights Reserved Conclusions
- 44. 44 © Hortonworks Inc. 2011 – 2018. All Rights Reserved Recommendations Disclaimer – Everything changes! –Both these benchmarks and the formats will change. Evaluate needs –Column projection and predicate pushdown are only in ORC & Parquet –Determine how to sort data –Are bloom filters useful?
- 45. 45 © Hortonworks Inc. 2011 – 2016. All Rights Reserved Thank you! Twitter: @owen_omalley Email: [email protected]