


















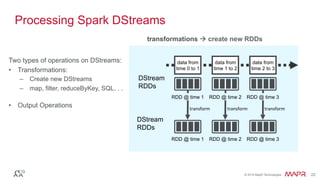
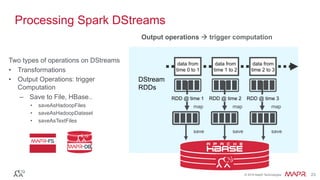







batch
time 0 to 1
batch
time 1 to 2
batch
time 2 to 3
dStream
Stored in memory
as an RDD](https://image.slidesharecdn.com/sparkstreaminganddatapipelinesfreecodefriday-160429180015/85/Fast-Scalable-Streaming-Applications-with-Spark-Streaming-the-Kafka-API-and-the-HBase-API-33-320.jpg)




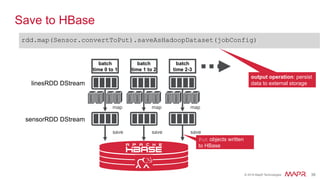

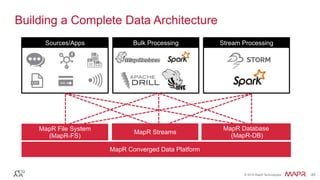



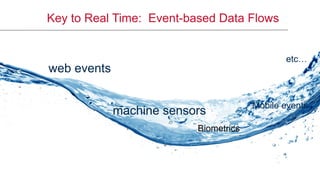
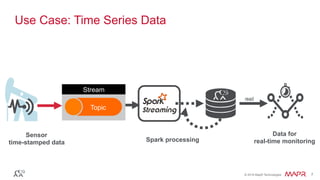
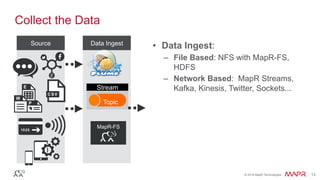
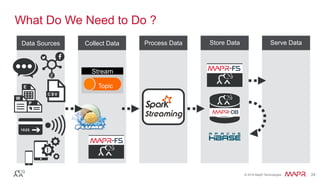
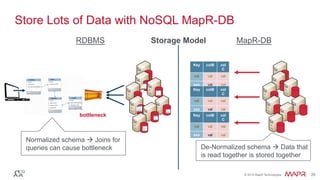
The document discusses the importance of stream processing in real-time data analysis, emphasizing how timely processing can optimize responses to events, such as temperature changes. It outlines the architecture for processing data using Spark Streaming and MapR technologies, detailing the collection, processing, and storage of event-based data. Additionally, it provides code examples and use cases for real-time monitoring of time-stamped sensor data.
































































































