Feb 2013 HUG: A Visual Workbench for Big Data Analytics on Hadoop
Download as PPTX, PDF0 likes1,598 views

Pervasive's Datarush is a big data analytics tool that seamlessly integrates with Hadoop, allowing for scalable data processing with a user-friendly drag-and-drop interface. The platform supports team collaboration and offers performance improvements over traditional methods, as demonstrated by TPC-H testing results. Datarush's architecture and components facilitate efficient data integration and analytics throughout the data lifecycle.















Feb 2013 HUG: A Visual Workbench for Big Data Analytics on Hadoop
- 1. A Visual Workbench for Big Data Analytics on Hadoop bigdata.pervasive.com •+1.855.356.DATA
- 2. Visual Workbench for Hadoop • Agenda – Pervasive Software – History of DataRush – Dataflow Concepts – Hadoop Integration – Demo – Performance Testing bigdata.pervasive.com •+1.855.356.DATA 2
- 3. Who is Pervasive? Global Software Company • Tens of thousands of users across the globe • Operations in Americas, EMEA, Asia • ~260 employees Strong Financials • $51 million revenue (trailing 12-month) • 48 consecutive quarters of profitability • $46 million in the bank • NASDAQ:PVSW since 1997 Leader in Data Innovation • 25% of top-line revenue re-invested in R&D • Software to manage, integrate and analyze data, in the cloud or on-premises, throughout the entire data lifecycle bigdata.pervasive.com •+1.855.356.DATA 3
- 4. History of DataRush • Initially developed as next-gen data engine for integration • Requirements – High data throughput – Scalable (data, multicore) – Based on dataflow concepts – Component based architecture – Easy to extend – Easily fits in visual development environment • Embedded in Pervasive products (DataProfiler) • Extended with SDK for more general use bigdata.pervasive.com •+1.855.356.DATA 4
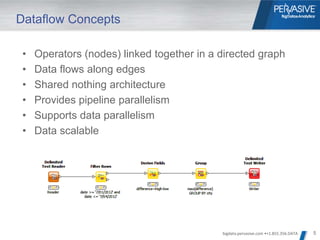
- 5. Dataflow Concepts • Operators (nodes) linked together in a directed graph • Data flows along edges • Shared nothing architecture • Provides pipeline parallelism • Supports data parallelism • Data scalable bigdata.pervasive.com •+1.855.356.DATA 5
- 6. Compilation to Execution Plan Compiled to a set of physical graphs Phase 1 Phase 2 Reader FilterRows DeriveFields Group(partial) Repartition Group(final) Writer Reader FilterRows DeriveFields Group(partial) Repartition Group(final) Writer Reader FilterRows DeriveFields Group(partial) Repartition Group(final) Writer Reader FilterRows DeriveFields Group(partial) Repartition Group(final) Writer bigdata.pervasive.com •+1.855.356.DATA
- 7. Operator Library bigdata.pervasive.com •+1.855.356.DATA
- 8. KNIME • KNIME – Open source analytics workflow tool for the desktop – Web site: www.knime.org – Supports team collaboration and resource sharing: • KNIME Teamspace • KNIME Server • KNIME Report • Integrated with DataRush – DataRush dataflow executor integrated as a plug-in extension – Includes DataRush operators – Product: RushAnalytics for KNIME bigdata.pervasive.com •+1.855.356.DATA 8
- 9. DataRush + KNIME bigdata.pervasive.com •+1.855.356.DATA 9
- 10. Integration with Hadoop • Data Level – HDFS access • File system abstraction – works with all I/O operators • Distributed execution – uses splits much like MR – HBase • Temporal key-value data store based on column families • Fast loading using HFile integration • Fast temporal queries • Execution – Distributed execution uses distribute DataRush engines (not MapReduce) – Integrating with YARN for resource sharing bigdata.pervasive.com •+1.855.356.DATA 10
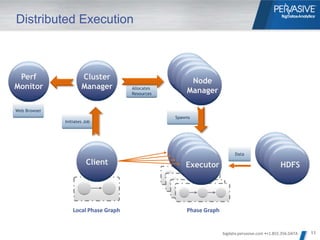
- 11. Distributed Execution Perf Cluster Node Monitor Manager Allocates Resources Manager Web Browser Spawns Initiates Job Data Client Executor HDFS Local Phase Graph Phase Graph bigdata.pervasive.com •+1.855.356.DATA 11
- 12. Distributed I/O ReadSplit • Allows downstream operators to be parallelized ReadSplit • Parallelization concepts are the AssignSplits same whether the graph is run locally or ReadSplit distributed ReadSplit bigdata.pervasive.com •+1.855.356.DATA 12
- 14. Performance Test TPC-H : 1 Terabyte Test : Run times • DataRush versus PIG 892 – Used TPC-H data Q21 3528 – Generated 1TB data 543 set in HDFS Q18 1742 – Ran several “queries” coded in DataRush and 626 Q10 1027 PIG – Run times in seconds Q9 1198 2356 DataRush (smaller is better) PIG 273 Q6 363 660 Q3 Cluster Configuration: 1414 • 5 worker nodes • 2 X Intel E5-2650 (8 core) 401 Q1 2036 • 64GB RAM • 24 X 1TB SATA 7200 rpm 0 500 1000 1500 2000 2500 3000 3500 4000 Run time in seconds bigdata.pervasive.com •+1.855.356.DATA 14
- 15. DataRush/RushAnalytics Solutions • Opera Solutions – Data science solutions provider – Embedding DataRush in engineered solutions • Healthcare – Claims cleansing & processing • Retail – Market basket analysis – Product category resolution (MDM) • Telecom – CDR processing & analysis “Pervasive DataRush’s efficiency and ability to automatically scale, whether on a single server or a Hadoop cluster, supports our vision for consistent, reusable, scalable Big Data analytics.” – Armando Escalante, Chief Operating Officer, Opera Solutions bigdata.pervasive.com •+1.855.356.DATA 15
- 16. Summary • Easy development of Hadoop workloads – Using drag-and-drop desktop GUI – Team oriented - Supports collaboration with others – No code to write - MapReduce included • Scalable Execution – Executes within Hadoop cluster – Scales from desktop to server to cluster with no workflow changes – Scales as cluster does – Handles small to very large data sizes – TPC-H performance testing shows improved performance over comparable PIG scripts bigdata.pervasive.com •+1.855.356.DATA 16
- 17. Questions? • My contact info: [email protected] @jimfalgout • Website bigdata.pervasive.com bigdata.pervasive.com •+1.855.356.DATA 17