Flink Forward Berlin 2018: Steven Wu - "Failure is not fatal: what is your recovery story?"
6 likes1,025 views

The document discusses failure in streaming job processing using Apache Flink and presents strategies for recovery, particularly focusing on hive backfill and flink rewind. It outlines the pros and cons of each approach, including considerations for stateful versus stateless jobs, data retention, and potential caveats. The document emphasizes the importance of planning and coordination to effectively handle failures and maximize the resilience of streaming applications.












































































































Flink Forward Berlin 2018: Steven Wu - "Failure is not fatal: what is your recovery story?"
- 1. Failure is not fatal: what is your recovery story? Steven Wu @stevenzwu
- 2. Failures are part of life!
- 3. A streaming job can fail Flink Streaming Job Sink Micro Service Source Data Enrichment
- 4. The application can have a bug Flink Streaming Job Sink Micro Service Source Data Enrichment
- 5. The dependency service may return bad data Flink Streaming Job Sink Micro Service Source Data Enrichment
- 6. The sink can fail Flink Streaming Job Sink Micro Service Source Data Enrichment
- 7. How can we recover? Source: https://pixabay.com/en/man-working-what-to-do-311326/
- 9. We are building a stream processing platform on top of Apache Flink
- 10. That integrates with Netflix ecosystem Titus And others ….
- 12. Demo: how to bootstrap new project
- 14. This is the generated skeleton code createSource("example-kafka-source") .addSink(getSink("null-sink")) .name(“null-sink”);
- 15. User can add business logic createSource("example-kafka-source") .keyBy(<key selector>) .window(TumblingProcessingTimeWindows.of(Time.seconds(5))) .reduce(<window function>); .addSink(getSink(“hive-sink")) .name(“hive-sink”);
- 16. Demo: how to deploy job
- 18. User can override source configuration Override Kafka cluster VIP kafka-test:2181 kafka-prod:2181
- 19. User can override any job config
- 20. User can configure resources
- 22. Streaming data also go to Hive in addition to Kafka Hive Kafka
- 23. Live job continues to run Live Job SinkKafka TimeNow ->outage period
- 24. User can start a parallel backfill job reading from Hive Live Job Sink Backfill Job Kafka TimeNow ->outage period
- 25. We implemented a Hive source with DataStream API public class HiveSource<OUT> extends RichParallelSourceFunction<OUT> implements CheckpointedFunction, ResultTypeQueryable<OUT> { // ... }
- 26. We provide dynamic source that allows user to switch from Kafka to Hive
- 27. (1) (2) (3) We provide dynamic source that allows user to switch from Kafka to Hive
- 28. (1) (2) (3) We provide dynamic source that allows user to switch from Kafka to Hive
- 29. (1) (2) (3) We provide dynamic source that allows user to switch from Kafka to Hive
- 30. (1) (2) (3) We provide dynamic source that allows user to switch from Kafka to Hive
- 31. Create a Hive backfill job under the same application as live job
- 32. User needs to override selected source
- 33. User needs to override selected source
- 35. It is NOT a lambda architecture ● Single streaming code base ● Just switch source from Kafka to Hive
- 36. ● Warm-up issue ● Ordering issue Hive backfill is likely not good for stateful jobs
- 37. ● Warm-up issue ● Ordering issue Hive backfill is likely not good for stateful jobs
- 38. For stateful jobs, each input record is evaluated against application state accumulated over time Image adapted from Stephen Ewen
- 39. Backfill job started with an empty state SinkBackfill Job Timeoutage period
- 40. Why don’t we add a warm-up period to build up the proper state Backfill Job Timeoutage periodWarm-up period Sink
- 41. Need to avoid output during warm-up period SinkBackfill Job Timeoutage periodWarm-up period Emit outputNo output
- 42. Hive backfill is likely not good for stateful jobs ● Warm-up issue ● Ordering issue
- 43. Kafka messages are ordered within a partition Source: kafka.apache.org
- 44. MapReduce data processing is driven by this concept of input splits Hive Table file-1 file-2 S3 files (physical) file-X ... 1 2 3 ... Y Input Splits (logical) Reducer Reducer ... Mapper Mapper Mapper ...
- 45. f0 f1 f2 f3 s0 s1 s2 s3 s4 s5 s6 s7 files splits Job Manager Split calculation Job manager does split calculation
- 46. Job manager broadcasts input splits to all task managers f0 f1 f2 f3 s0 s1 s2 s3 s4 s5 s6 s7 files splits Job Manager Task Manager Task Manager Task Manager s0 … s7 Split calculation
- 47. Task managers run the same split assignment algorithm f0 f1 f2 f3 s0 s1 s2 s3 s4 s5 s6 s7 files splits Job Manager Task Manager Task Manager Task Manager s0 … s7 s0 s1 s2 s3 s4 s5 s6 s7 Split calculation Split Assignment
- 48. There is no guarantee of order for data files f0 (hour=0) f1 f2 (hour=23) f3 (hour=12) s0 s1 s2 s3 s4 s5 s6 s7 files splits Task Manager s0 (hour=0) ... s3 (hour=23) s6 (hour=12) s9 (hour=3) ...
- 49. Does ordering matter? ● Usually not for stateless jobs ● Probably important for stateful jobs
- 50. Late events can be dropped Source: flink.apache.org ● When watermark is past the end timestamp of the window ● Allowed lateness can give some extra time buffer
- 52. Checkpoint snapshots and uploads state to DFS Source: http://flink.apache.org/ checkpoint store ● HDFS ● S3
- 53. Checkpoint achieves fault tolerance Time Checkpoint x-1 Checkpoint x Now
- 54. Time Checkpoint x-1 Checkpoint x Checkpoint achieves fault tolerance
- 55. Enable external checkpoint CheckpointConfig config = env.getCheckpointConfig(); config.enableExternalizedCheckpoints( ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
- 56. Time Checkpoint y Checkpoint x outage period Checkpoint x+1 Now Rewind job to a checkpoint before outage period
- 57. Rewind job to a checkpoint before outage period Time Checkpoint y Checkpoint x outage period Checkpoint x+1
- 58. There are no warmup and ordering issues with Flink rewind ● Application state is correct after rewind ● Flink job is still reading the same Kafka source
- 59. Choose the external checkpoint option
- 61. Kafka retention matters Time outage period NowKafka retention As far as we can go back
- 62. Can we have 10 days of Kafka retention?
- 63. Anatomy of data stream Adapted from “An elastic batch-and stream-processing stack with Pravega and Apache Flink” by Stephan Ewen and Flavio Junqueira PresentRecent Past Distant Past
- 64. Anatomy of data stream PresentRecent Past Distant Past
- 65. Can’t keep 10 days of data in local disk ● d2.8xl : 10 Gbps of network, 48 TB of disk ● Assuming 2 Gbps ingestion rate per instance, 10 days of data requires 216 TB of disk
- 66. EBS is more expensive than S3
- 67. EBS is more expensive than S3 Cost (per month) EBS: throughput optimized HDD $0.045 per GB
- 68. EBS is more expensive than S3 Cost (per month) EBS: throughput optimized HDD $0.045 per GB S3 standard $0.021 per GB
- 69. Cost (per month) EBS: throughput optimized HDD $0.045 per GB S3 standard $0.021 per GB S3 Standard- Infrequent Access $0.013 per GB EBS is more expensive than S3
- 70. What if Kafka offloads historical data to S3 infrequent access tier PresentRecent Past Distant Past Infrequent Access
- 71. Here are the benefits of tiered storage ● Only deal with Kafka source ● Support 10-day retention cost efficiently
- 72. There are systems implemented tiered storage
- 74. Hive backfill Flink rewind Warm-up issue Yes No Ordering issue Yes No
- 75. Hive backfill Flink rewind Warm-up issue Yes No Ordering issue Yes No Applicability Stateless Stateless and stateful
- 76. Hive backfill Flink rewind Warm-up issue Yes No Ordering issue Yes No Applicability Stateless Stateless and stateful Data retention Weeks or months Hours or days
- 77. Pros for Hive backfill ● Long-term storage ● No delay for processing latest events ● Can achieve fast recovery
- 78. Stateless Hive Backfill Stateful Flink Rewind Here is our recommendation to users
- 80. Caveat 1: Don’t overwhelm external services Flink Streaming Job Sink Micro Service Source 10x load 10x load ● Size cluster properly ● Rate limit operator
- 81. Flink Streaming Job Sink A/B Service Source Time Caveat 2: Your dependency may not participate in rewind
- 82. Flink Streaming Job Sink A/B Service Source Time Process live msg X Caveat 2: Your dependency may not participate in rewind
- 83. Flink Streaming Job Sink A/B Service Source Time Process live msg X Alice? Caveat 2: Your dependency may not participate in rewind
- 84. Flink Streaming Job Sink A/B Service Source Time Process live msg X Alice? Cell A Caveat 2: Your dependency may not participate in rewind
- 85. Flink Streaming Job Sink A/B Service Source Time Allocation change Process live msg X Caveat 2: Your dependency may not participate in rewind
- 86. Flink Streaming Job Sink A/B Service Source Time outage period Allocation change Process live msg X Caveat 2: Your dependency may not participate in rewind
- 87. Flink Streaming Job Sink A/B Service Source Time outage period RewindAllocation change Process live msg X Caveat 2: Your dependency may not participate in rewind
- 88. Flink Streaming Job Sink A/B Service Source Time outage period RewindAllocation change Process live msg X Reprocess old msg X Caveat 2: Your dependency may not participate in rewind
- 89. Flink Streaming Job Sink A/B Service Source Time outage period RewindAllocation change Process live msg X Reprocess old msg X Alice? Caveat 2: Your dependency may not participate in rewind
- 90. Flink Streaming Job Sink A/B Service Source Time outage period RewindAllocation change Process live msg X Reprocess old msg X Alice? Cell B Caveat 2: Your dependency may not participate in rewind
- 91. Solution 1: Support lookup with historical view Flink Streaming Job Sink A/B Service Source Time outage period Process live msg X Reprocess old msg X Alice at 1pm? Cell A 1pm 4pm RewindAllocation change
- 92. Solution 2: Convert table lookup to a streaming source Flink Streaming Job Sink A/B Service Source Table lookup
- 93. Flink Streaming Job Sink A/B Source Source State A/B data becomes part of app state Solution 2: Convert table lookup to a streaming source
- 94. ● Idempotent sink ○ ElasticSearch, Cassandra Caveat #3: watch out for the impact to downstream consumers
- 95. ● Idempotent sink ○ ElasticSearch, Cassandra ● Resettable sink ○ Drop Hive partition with bad data Caveat #3: watch out for the impact to downstream consumers
- 96. Here is a more complicated case with Kafka sink Topic1 Job1 Topic2 Job2 Topic3
- 97. At 4pm, job1 rewinded to checkpoint taken at 1pm Topic1 Job1 Topic2 Job2 Topic3 Time outage period 1pm 4pm
- 98. What should job2 do? Topic1 Job1 Topic2 Job2 Topic3 Time outage period ??? Time outage period 1pm 4pm 1pm 4pm 5pm
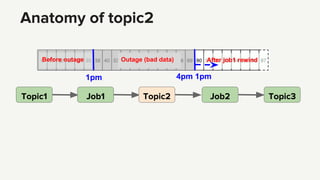
- 99. Anatomy of topic2 Topic1 Job1 Topic2 Job2 Topic3 Outage (bad data) 1pm 4pm Before outage After job1 rewind 1pm
- 100. Rewind job2 to 1pm Topic1 Job1 Topic2 Job2 Topic3 Time outage period bad data ● Correct app state ● Still reprocess bad data 1pm 1pm
- 101. Rewind job2 to 4pm Topic1 Job1 Topic2 Job2 Topic3 Time outage period bad data ● Still bad app state ● Skip bad data 1pm 4pm
- 102. Stop job1 and job2 first Topic1 Job1 Topic2 Job2 Topic3 4pm bad data 1pm
- 103. Wipe out all messages from topic2 Topic1 Job1 Topic2 Job2 Topic3 All bad data are gone!
- 104. Rewind job2 to 1pm checkpoint Topic1 Job1 Topic2 Job2 Topic3 Time outage period 1pm ● Correct app state ●
- 105. Rewind job1 to 1pm checkpoint Topic1 Job1 Topic2 Job2 Topic3 Time outage period● Correct app state ● Skip bad data 1pm 1pm
- 106. It is difficult to execute ● Very involved process ● Need coordination btw job1 and job2
- 107. Caveats recap ● Don’t overwhelm external services ● Your dependency may not participate in rewind ● Watch out for the impact to downstream consumers
- 108. Steven Wu @stevenzwu What defines us is how well we rise after falling