













Forward-Forward Algorithm
- 1. What is wrong with backpropagation The Forward-Forward Algorithm: Some Preliminary Investigations Neurips 2022
- 2. What is wrong with backpropagation > Biological Perspective - Error derivative propagation을 하거나, neural activity들을 저장하는 기제를 cortex에서 찾아볼 수 없음 => 학습이 “later time step”에서 이루어지는 것이 아니라, real-time의 비동기로 이루어지는 것인 명백 > Computational Perspective - backpropagation은 “모든 forward pass”의 derivative를 계산할 수 있어야 함 (ex. rnn 업데이트 시 모든 sequence를 recurring하기 전에는 업데이트할 수 없음) => 이러한 문제는 reinforcement learning을 할 때 random weight에서 시작하는 모델의 high variance 문제를 발생시킴
- 3. forward-forward algorithm - Blotzmann machine과 유사한 greedy multi-layer learning procedure Forward-Forward algorithm 구성 요소 1. Goodness function for one layer: Weight를 업데이트할 때 사용할 objective function 2. Forward (Positive), Forward (Negative): Network procedure
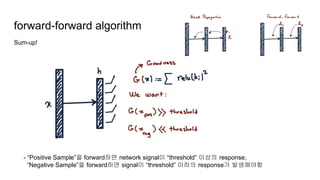
- 4. forward-forward algorithm Goodness function constant threshold feature logistic function
- 5. forward-forward algorithm Forward (positive) - Forward (negative) 1 layer Expected Output : Positive Input => Output > threshold : Negative Input => Output < threshold Input
- 6. forward-forward algorithm Sum-up! - “Positive Sample”을 forward하면 network signal이 “threshold” 이상의 response, “Negative Sample”을 forward하면 signal이 “threshold” 이하의 response가 발생해야함
- 7. Negative data for Forward-Forward Unsupervised Task 1. Create “Random” Binary Mask 2. 다른 클래스의 샘플을 추출해 Mask를 씌운 뒤에 sum => Negative Data가 국소적인 “characterize shape”을 포함하는 것이 핵심
- 8. Negative data for Forward-Forward Unsupervised Task => 자세한 디테일은 없지만, Positive Data는 MNIST를 사용하고 Negative Data는 hybrid를 사용해 4 layer (for each 2000 feature) 네트워크를 학습 하고 2,3,4 layer의 feature를 Linear Classifier 학습에 사용하면 1.37% error rate in MNIST를 보였음 - (기존의 backprop FC 네트워크가 1.4%, dropout/label smoothing 등을 사용하면 1.1%) - (First layer의 feature를 linear classifier에 포함하면 성능 하락) => 네트워크를 convolution kernel로 변경하고 Linear Classifier 학습 시 1.16% error rate in MNIST *추후 following 논문들은 negative data를 “잘 만드는 방법”들이 나올 듯 Forward Positive Forward Negative Linear Classifier Sample/ Hybrid
- 9. Negative data for Forward-Forward Supervised Task Unsupervised에서 한 것처럼 복잡한 sample을 만들지 않고, 단순하게 label을 다른 것으로 변경함 + Label 정보를 “Input”에 넣어서 Forward를 함! => 네트워크가 Label과 Image 영역의 Correlation을 학습할 것임
- 10. Negative data for Forward-Forward Supervised Task - Supervised Task의 Forward Forward는 익숙치 않음 for i in range(num_class): input = i Class Vector를 활성화 + sample network의 모든 레이어들의 output을 모두 accumulate => accumulated한 값이 가장 “큰” class가 예측된 class Forward Positive Forward Negative Class Vector + Sample => Class가 10개라면, 10번 Inference 해야함! ~ 1.36% error rate in FC with FF ~ 0.64% error rate in CNN with FF
- 11. Exp in CIFAR 10 *Network: 3 layer with 3072 ReLU each - Compute goodness for every label: 각 클래스마다 Input vector를 바꿔가며 inference (supervised task) - one-pass softmax: (unsupervised task) => min/max ssq는 goodness function을 minimize, maximize로 학습 == network output을 “threshold” 근처로 붙일 것이냐, 혹은 넓힐 것이냐 => BP가 “overfitting”에는 탁월함을 보임
- 12. Pros & Cons - Pros ~ Backprop을 위해서는 Full derivatives를 관리하는 시스템이 필요하지만, forward-forward는 비교적 적은 비용의 최대 컴퓨팅 리소스가 요구됨 ~ Trillion의 파라미터를 업데이트 하는데에 엄청난 watts가 필요한데, forward-forward는 “mortal computation”으로의 방향성을 제시하고 있음 (* hardware efficiency를 의미하는 듯) - Cons ~ 아직 backpropagation보다 학습이 느리고, generalize 성능이 뛰어나 보이지는 않음 (backprop 대체는 멀었다) ~ Big Model의 Big Data는 backpropagation이 좋을 듯 (그러나 적은 데이터에서는 효율적일 수 있지 않을까…?)
- 13. Future Works - Negative Forward와 Positive Forward와의 관계 - Negative forward 없이 Positive Forward만 한다면? - Goodness function에 대한 탐색이 추가로 필요함 - ReLU 외의 activation function을 사용해볼만하지 않을까? (t-distribution 등) - Forward-Forward를 위한 하드웨어 - …