























PPT4: Frameworks & Libraries of Machine Learning & Deep Learning
- 1. Frameworks & Libraries of Machine Learning & Deep Learning
- 2. Table of Contents 1.ML Frameworks & Libraries 2.Jupyter Framework 3.Jupyter Application and Use Cases 4.Scikit Learn 5.Real World Applications of Scikit Learn 6.Modules of Scikit-Learn 7.Some of the algorithms used in Modules 8.Numpy 9.Pandas 10.Scipy Introduction 11.Scipy Task Specific Sub-Modules 12.Jupyter Libraries (Visualization) 13.Jupyter Libraries (NLP) 14.Zeppelin Framework 15.PySpark Framework 16.DL Frameworks & Libraries 17.TensorFlow 18.Keras 19.PyTorch 20.MXNet & Gluon 21.Chainer & CNTK 22.ONNX
- 3. Machine Learning Frameworks & Libraries Frameworks Jupyter PySpark Zeppelin Natutal Language Processing NLTK Gensim spaCy General Libraries Numpy Scikit learn Scipy Pandas Mllib Visualization Seaborn Bokeh Plotly Matplotlib
- 4. Jupyter Framework Jupyter User Interface Jupyter Notebook Jupyter Console Jupyter QtConsole Jupyter Console- It is a terminal with kernels using Jupyter protocol. It can be installed with: pip install jupyter -console If you want to conda Conda install -c conda-forge jupyter-console Jupyter Qt Console- The Qt console is a lightweight application that largely Looks like a terminal, but provides enhancements possible in GUI such as multiline editing, graphical calltips and much more. It can use any Jupyter kernal. Jupyter Notebook – Jupyter Notebook is a development environment for writing and executing Python code. The notebook is often used for analysis with description and also for executable documents to perform data analysis.
- 5. Jupyter Applications and Use Cases Application Jupyter for Data Science What causes cancer? Is Ice-cream good for you? Jupyter through large datasets exploration prediction & inference could give you the answer. Jupyter kernals used in Data Science Python, R, Julia, Bash Use Cases Notebook innovation of Netflix PayPal Notebook DevOps Intelligence with Jupyter Hub Bloomberg B Quant Platform
- 6. Scikit Learn Scikit Learn built for machine learning library is a Python module. Built on Numpy, Scipy and Matplotlib it contains various algorithms in Classification, Clustering, Regression, Model Selection, Dimensionality Reduction and Preprocessing. Dependencies Python (>= 3.5) Numpy (>= 1.11.0) Scipy (>= 0.17.0) Joblib (>= 0.11) How to use If Numpy & Scipy Installed then use pip install -U scikit-learn Else conda install scikit learn
- 7. Real world Applications of Scikit Learn Visualizaing the stock market structure Recognizing handwritten digits Hierarchial clustering on image of coins Face Completion with multi-output estimators Comparing anamoly detection algorithms for outlier detection Isotonic Regression Compact Estimator Representation
- 8. Modules of Scikit Learn(Part1) Biclustering Clustering Covariance Estimation Cross Decomposition Decomposition Ensemble Methods Feature Selection Gaussian Process of Machine Learning Missing Value Imputation Generalized Linear Models sklear.cluster.bicluster sklearn.cluster sklearn.covariance sklearn.cross_decomposition sklearn.decomposition sklearn.ensemble sklearn.feature_selection sklearn.gaussian_process sklearn.impute sklearn.linear_model
- 9. Manifold Learning Inspection Gaussian Mixture Models Model Selection Multioutput Methods Nearest Neighbors Neural Networks Pre-processing Semi Supervised Classification Super Vector Machines Decision Trees sklearn.manifold sklearn.inspection sklearn.mixture sklearn.model_selection sklearn.multioutput sklearn.neighbors sklearn.neural_network sklearn.preprocessing sklearn.semi_supervised sklearn.svm sklearn.tree
- 10. Some of the algorithms used in Modules Spectral Co-Clustering algorithm- Rearranging the original dataset after shuffling rows and columns to make bi-clusters contiguous. Spectral Biclustering algorithm- Rows and columns of shuffled matrix are rearranged to show the biclusters formed by the algorithm. Feature Agglomeration- Similar features from different images merged together to form a new image. Affinity Propagation - Clustering by passing messages between datapoints. Sparse Inverse Covariance Estimation Shrinkage Covariance Estimation
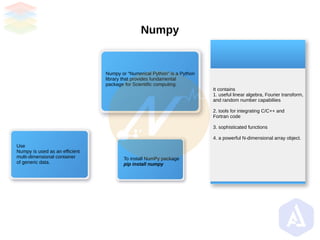
- 11. Numpy It contains 1. useful linear algebra, Fourier transform, and random number capabiliies 2. tools for integrating C/C++ and Fortran code 3. sophisticated functions 4. a powerful N-dimensional array object. To install NumPy package pip install numpy Use Numpy is used as an efficient multi-dimensional container of generic data. Numpy or “Numerical Python” is a Python library that provides fundamental package for Scientific computing.
- 12. Important Data Types One Dimensional Array Multi-Dimensional Array Boolean Integer Float Complex Mathematical Functions Add, Subtract, Multiple, Divide, Power, Mod Rounding,Ceil,Floor Statistical Trigonometric Algebra
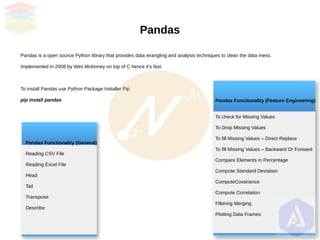
- 13. Pandas Pandas is a open source Python library that provides data wrangling and analysis techniques to clean the data mess. Implemented in 2008 by Wes Mckinney on top of C hence it’s fast. To install Pandas use Python Package Installer Pip pip install pandas Pandas Functionality (General) Reading CSV File Reading Excel File Head Tail Transpose Describe Pandas Functionality (Feature Engineering) To check for Missing Values To Drop Missing Values To fill Missing Values – Direct Replace To fill Missing Values – Backward Or Forward Compare Elements in Percentage Compute Standard Deviation ComputeCovariance Compute Correlation Filtering Merging Plotting Data Frames
- 14. Scipy is a high-level Scientific Computing that contains various toolboxes. It contains different submodules corresponding to different applications such as interpolation, integration, optimization, image processing, statistics, special functions, etc. Different Applications File input/output Special Functions Linear Algebra Operations Interpolation Optimization and fit Statistics and random numbers Numerical Integration Fast Fourier Transforms Signal processing Image Manipulation scipy.io Scipy.special scipy.linalg scipy.interpolate scipy.optimize scipy.stats scipy.integrate scipy.fftpack scipy.signal scipy.ndimage Scipy
- 15. Scipy Task Specific Sub-Modules scipy.cluster Vector quantization / Kmeans scipy.constants Physical and mathematical constants scipy.fftpack Fourier transform scipy.integrate Integration routines scipy.interpolate Interpolation scipy.io Data input and output scipy.linalg Linear algebra routines scipy.ndimage N-dimensional image package scipy.odr Orthogonal distance regression scipy.optimize Optimization scipy.signal Signal processing scipy.sparse Sparse matrices scipy.spatial Spatial data structures and algorithms scipy.special Any special mathematical functions scipy.stats Statistics
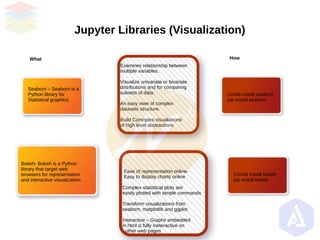
- 16. Jupyter Libraries (Visualization) What Why How Seaborn – Seaborn is a Python library for Statistical graphics. Bokeh- Bokeh is a Python library that target web browsers for representation and interactive visualization. conda install seaborn pip install seaborn Conda install bokeh pip install bokeh Ease of representation online- Easy to display charts online Complex statistical plots are easily plotted with simple commands Transform visualizations from seaborn, matplotlib and ggplot Interactive – Graphs embedded in html is fully ineteractive on other web pages Examines relationship between multiple variables. Visualize univariate or bivariate distributions and for comparing subsets of data. An easy viwe of complex datasets structure. Build Comnples visualiations of high level abstractions
- 17. pip install plotly conda install -c plotly plotly=4.1.0 python -m pip install -U pip python -m pip install -U matplotlib Plotly-The plotly is an interactive a Python library that covers 40 unique chart types ranging from statistical, financial, geograohic, scientifiic and 3-D usecases. Matplotlib- Matplotlib is a Python 2D plotting library which produces quality figures in variety of hardcopy formats and interactive environments across different platforms. Basic Charts- Scatter Plots, Line Plot, Bar Charts, PirCharts Statistical and Seaborn-style Charts Error Bars, Box Plots, Histograms, Distplots Scientific Charts- Contour Plots, Heatmaps, Wind Rose Charts Financial Charts -Time Series, Candlestick Charts, Waterfall Charts Lines, bars and markers such as Stacked Bar Graph, Broken Barh, plotting categorical Variables etc. Plots in images contours and fields Subplots, axes and figures Statistics- Boxplot, Violin plots, Pie and Polar Charts
- 18. Jupyter Libraries (NLP) What Why Convert text to lower case word tokenize sent tokenize stop words removal lemma stemming Get word frequency NER(Named Entity Recognition) How Memory Independence- can process large, web scale corpora Efficient implemetations for Latent sementic Analysis, Latent Dirichlet Allocation or Random Projection Similarity queries for documents in their semeantic representation NLTK- NLTK is a python library for natural language processing that works with human language data along with text processing libraries for classification, tokenization, stemming, tagging, parsing. Gensim- Gensim is a Python library for topic modelling, document indexing and similarity retrieval. The target audience are natural language processing (NLP) and information retrieval (IR). pip install nltk pip install gensim
- 19. pip install spacy spaCy – A package for “Industrial strength NLP in Python”. It does not weigh the user down with decisions over what esoteric algorithms to use for common tasks and it’s fast. Has many convenience methods for cleaning and normalising text. Word-to-vector transformations Dependency Parsing Part-of-speech tagging
- 20. Zeppelin Framework Apache Zeppelin is a web-based notebook that enables data-driven interactive analytics and collaborative documents with Scala, SQL and much more. Apache Zeppelin is build on the JVM while Jupyter is built on Python. With Zeppelin there are possibilities to mix languages across cells. Zeppelin supports Scala, Python, SparksSQL,Hive, Markdown and Shell and we can make our own language interpreter. It is data exploration and visualization intended for big data and large scale projects.
- 21. PySpark Framework Pyspark is great for performing exploratory data analysis at scale, building machine learning pipelines and to create ETLs for data platform. pip install pyspark Libraries Py4J – Popular library which is integrated within Pyspark and allows to dynamically interface JVM objects. PySparkSQL- It is a PySpark library to apply SQL-like analysis on huge structured and semi-structured data. Mllib - Mllib library uses the data parallelism technique to store and work with data. It supports many machine-learning algorithms for Classification, regression, clustering, collaborative filtering, dimensionality reduction, and underlying optimization.
- 22. Deep Learning Frameworks & Libraries Libraries TenserFlow PyTorch Keras MXNet Caffe2 Gluon Chainer ONNX CNTK Frameworks Jupyter PySpark Zappelin
- 23. TensorFlow Tensorflow- TensorFlow is computational framework for building machine learning models. We can do large and complex computations easily which is of high level and its computation time is very optimized. Implementations of deep learning Speech Recognition, Computer Vision, Robotics, Ir, NLP ETC. Tensor – Tensor is an N-dimensional array of data. Four main tensors that we can create: tf,Variable, tf.constant, tf.placeholder and tf.SparseTenser TensorFlow Toolkit Hierarchy
- 24. Keras Keras is a machine learning framework specially useful when you have a lot of data and wants to go for AI: deep learning. It is useful for high-level API Massive models of deep learning are easy to go in Keras with single-line functions. Keras does not block access to lower level frameworks. Keras model Serialization/Deserialization APIs, callbacks, and data streaming using Python are very mature. Keras is on higher level not comparable to Tenserflow which is on lower level. On Keras level the lower level primitives are used to implement Neural network abstraction like Layers and models.
- 25. PyTorch The PyTorch is a Software tool that operates with Dynamically updated graph. In PyTorch standard debuggers can be used such as pdb or PyCharm. The process of training a neural network model in PyTorch is simple and clear and supports data parallelism and also supports pre-trained models
- 26. MXNet & Gluon MXNet – It is highly scalable deep learning tool that can be used on many devices. It supports a large number of languages ( C++, Python, R, Julia, JavaScript, Scala, Go and even Perl). The framework is effectively parallel on multiple GPUs and machines. Fast Problem solving ability. Gluon- It s a great deep learning framework that can be used to create simple as well as sophisticated models. Specificity- Flexible interface and simplifies prototyping, building and training deep learning models without sacrificing speed to learn. Based on MXNet and offers simple API that simplifies creating deep learning model. Brings together training algorithm and neural network model thus providing flexibility in development process without sacrifying performance.
- 27. Chainer & CNTK Chainer- Chainer is first framework to use a dynamic architecture model. It is written in Python on top of the Numpy and CuPy libraries. Chainer is faster than other Python oriented frameworks, with TenserFlow the slowest inclusing MXNet and CNTK. Better GPU data center performance than TenserFlow. OOP like programming style. CNTK is a Microsoft Cognitive Toolkit for describing, training and executing computational networks. It is an implementation of computational networks that supports both CPU and GPU CNTK inputs, outputs and parameters are organised as tensers. CNTK is also one of the first deep-learning toolkits to support the Open Neural Network Exchange. It can be included as library in Python,C#, or C++ programs.
- 28. ONNX Built from the collaboration of Microsoft and Facebook as a search for open format presentation of deep learning models. It enables models to be trained in one framework inference on the other when transferred. Supported in Caffe2, Microsoft Cognitive Toolkit, and PyTorch.