From distributed caches to in-memory data grids
Download as PPTX, PDF78 likes25,175 views

This document summarizes a presentation about distributed caching technologies from key-value stores to in-memory data grids. It discusses the memory hierarchy and how software caches can improve performance by reducing data access latency and offloading storage. Different caching patterns like cache-aside, read-through, write-through and write-behind are explained. Popular caching products including Memcached, Redis, Cassandra and data grids are overviewed. Advanced concepts covered include data distribution, replication, consistency protocols and use cases.
































From distributed caches to in-memory data grids
- 1. From distributed caches to in-memory data grids TechTalk by Max A. Alexejev [email protected]
- 2. Memory Hierarchy R <1ns L1 ~4 cycles, ~1ns Cost L2 ~10 cycles, ~3ns L3 ~42 cycles, ~15ns DRAM >65ns Flash / SSD / USB Storage term HDD Tapes, Remote systems, etc 2 Max A. Alexejev
- 3. Software caches Improve response times by reducing data access latency Offload persistent storages Only work for IO-bound applications! 3 Max A. Alexejev
- 4. Caches and data location Consistency protocol Shared Local Remote Distributed Hierarchical Distribution algorithm 4 Max A. Alexejev
- 5. Ok, so how do we grow beyond one node? Data replication 5 Max A. Alexejev
- 6. Pro’s and Con’s of replication Pro • Best read performance (for local replicated caches) • Fault tolerant cache (both local and remote) • Can be smart: replicate only part of CRUD cycle Con • Poor writes performance • Additional network load • Can scale only vertically: limited by single machine size • In case of master-master replication, requires complex consistency protocol 6 Max A. Alexejev
- 7. Ok, so how do we grow beyond one node? Data distribution 7 Max A. Alexejev
- 8. Pro’s and Con’s of data distribution Pro • Can scale horizontally beyond single machine size • Reads and writes performance scales horizontally Con • No fault tolerance for cached data • Increased latency of reads (due to network round-trip and serialization expenses) 8 Max A. Alexejev
- 9. What do high-load applications need from cache? Linear Distributed Low horizontal latency cache scalability 9 Max A. Alexejev
- 10. Cache access patterns: Client Cache Aside For reading data: For writing data 1. Application asks 1. Application writes for some data for a some new data or given key updates existing. Cache 2. Check the cache 2. Write it to the 3. If data is in the cache cache return it to 3. Write it to the DB. the user 4. If data is not in the Overall: cache fetch it from the DB, put it in • Increases reads the cache, return it performance to the user. • Offloads DB reads DB • Introduces race conditions for writes 10 Max A. Alexejev
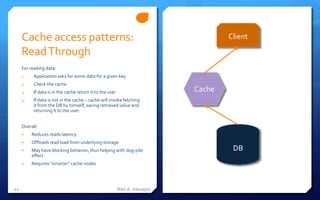
- 11. Cache access patterns: Client Read Through For reading data: 1. Application asks for some data for a given key 2. Check the cache 3. If data is in the cache return it to the user Cache 4. If data is not in the cache – cache will invoke fetching it from the DB by himself, saving retrieved value and returning it to the user. Overall: • Reduces reads latency • Offloads read load from underlying storage • May have blocking behavior, thus helping with dog-pile DB effect • Requires “smarter” cache nodes 11 Max A. Alexejev
- 12. Cache access patterns: Client Write Through For writing data 1. Application writes some new data or updates existing. Cache 2. Write it to the cache 3. Cache will then synchronously write it to the DB. Overall: • Slightly increases writes latency DB • Provides natural invalidation • Removes race conditions on writes 12 Max A. Alexejev
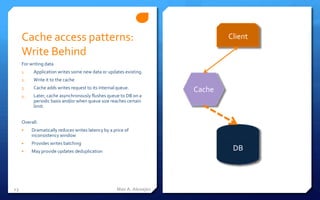
- 13. Cache access patterns: Client Write Behind For writing data 1. Application writes some new data or updates existing. 2. Write it to the cache Cache adds writes request to its internal queue. 3. Cache 4. Later, cache asynchronously flushes queue to DB on a periodic basis and/or when queue size reaches certain limit. Overall: • Dramatically reduces writes latency by a price of inconsistency window • Provides writes batching • May provide updates deduplication DB 13 Max A. Alexejev
- 14. A variety of products on the market… Memcached Hazelcast Cassandra GigaSpaces Redis Terracotta Oracle Coherence Infinispan MongoDB Riak EhCache … 14 Max A. Alexejev
- 15. KV caches NoSQL Data Grids Oracle Memcached Redis Coherence Ehcache Cassandra GemFire Lets sort em out! … MongoDB GigaSpaces Some products are really hard to sort – like Terracotta in both DSO … GridGain and Express modes. Hazelcast Infinispan 15 Max A. Alexejev
- 16. Why don’t we have any distributed in-memory RDBMS? Master – MultiSlaves configuration • Is, if fact, an example of replication • Helps with reads distribution, but does not help with writes • Does not scale beyond single master Horizontal partitioning (sharding) • Helps with reads and writes for datasets with good data affinity • Does not work nicely with joins semantics (i.e., there are no distributed joins) 16 Max A. Alexejev
- 17. Key-Value caches • Memcached and EHCache are good examples to look at • Keys and values are arbitrary binary (serializable) entities • Basic operations are put(K,V), get(K), replace(K,V), remove(K) • May provide group operations like getAll(…) and putAll(…) • Some operations provide atomicity guarantees (CAS, inc/dec) 17 Max A. Alexejev
- 18. Memcached • Developed for LiveJournal in 2003 • Has client libraries in PHP, Java, Ruby, Python and many others • Nodes are independent and don’t communicate with each other 18 Max A. Alexejev
- 19. EHCache • Initially named “Easy Hibernate Cache” • Java-centric, mature product with open- source and commercial editions • Open-source version provides only replication capabilities, distributed caching requires commercial license for both EHCache and Terracotta TSA 19 Max A. Alexejev
- 20. NoSQL Systems A whole bunch of different products with both persistent and non-persistent storage options. Lets call them caches and storages, accordingly. Built to provide good horizontal scalability Try to fill the feature gap between pure KV and full-blown RDBMS 20 Max A. Alexejev
- 21. Written in C, supported by VMWare Client libraries for C, C#, Java, Scala, PHP, Erlang, etc Single-threaded async impl Has configurable persistence Case study: Redis Works with K-V pairs, where K is a string and V may be either number, hset users:goku powerlevel 9000 string or Object (JSON) hget users:goku powerlevel Provides 5 interfaces for: strings, hashes, sorted lists, sets, sorted sets Supports transactions 21 Max A. Alexejev
- 22. Use cases: Redis Good for fixed lists, tagging, ratings, counters, analytics and queues (pub-sub messaging) Has Master – MultiSlave replication support. Master node is currently a SPOF. Distributed Redis was named “Redis Cluster” and is currently under development 22 Max A. Alexejev
- 23. • Written in Java, developed in Facebook. • Inspired by Amazon Dynamo replication mechanics, but uses column-based data model. Case study: Cassandra • Good for logs processing, index storage, voting, jobs storage etc. • Bad for transactional processing. • Want to know more? Ask Alexey! 23 Max A. Alexejev
- 24. In-Memory Data Grids New generation of caching products, trying to combine benefits of replicated and distributed schemes. 24 Max A. Alexejev
- 25. IMDG: Evolution Data Grids Computational • Reliable storage and Grids live data balancing • Reliable jobs among grid nodes execution, scheduling and load balancing Modern IMDG 25 Max A. Alexejev
- 26. IMDG: Caching concepts • Implements KV cache interface • Live data redistribution when nodes are going up or down – no data loss, no • Provides indexed search by values clients termination • Provides reliable distributed locks • Supports RT, WT, WB caching patterns interface and hierarchical caches (near caching) • Caching scheme – partitioned or • Supports atomic computations on grid distributed, may be specified per cache nodes or cache service • Provides events subscription for entries (change notifications) • Configurable fault tolerance for distributed schemes (HA) • Equal data (and read/write load) 26 Max A. Alexejev distribution among grid nodes
- 27. IMDG: Under the hood • All data is split in a number of sections, called partitions. • Partition, rather then entry, is an atomic unit of data migration when grid rebalances. Number of partitions is fixed for cluster lifetime. • Indexes are distributed among grid nodes. • Clients may or may not be part of the grid cluster. 27 Max A. Alexejev
- 28. IMDG Under the hood: Requests routing For get() and put() requests: 1. Cluster member, that makes a request, calculates key hash code. 2. Partition number is calculated using this hash code. 3. Node is identified by partition number. 4. Request is then routed to identified node, executed, and results are sent back to the client member who initiated request. For filter queries: 1. Cluster member initiating requests sends it to all storage enabled nodes in the cluster. 2. Query is executed on every node using distributed indexes and partial results are sent to the requesting member. 3. Requesting member merges partial results locally. 4. Final result set is returned from filter method. 28 Max A. Alexejev
- 29. IMDG: Advanced use-cases Messaging Map-Reduce calculations Cluster-wide singleton And more… 29 Max A. Alexejev
- 30. GC tuning for large grid nodes An easy way to go: rolling restarts or storage-enabled cluster nodes. Can not be used in any project. A complex way to go: fine-tune CMS collector to ensure that it will always keep up cleaning garbage concurrently under normal production workload. An expensive way to go: use OffHeap storages provided by some vendors (Oracle, Terracotta) and use direct memory buffers available to JVM. 30 Max A. Alexejev
- 31. IMDG: Market players Oracle Coherence: commercial, free for evaluation use. GigaSpaces: commercial. GridGain: commercial. Hazelcast: open-source. Infinispan: open-source. 31 Max A. Alexejev
- 32. Terracotta A company behind EHCache, Quartz and Terracotta Server Array. Acquired by Software AG. 32 Max A. Alexejev
- 33. Terracotta Server Array All data is split in a number of sections, called stripes. Stripes consist of 2 or more Terracotta nodes. One of them is Active node, others have Passive status. All data is distributed among stripes and replicated inside stripes. Open Source limitation: only one stripe. Such setup will support HA, but will not distribute cache data. I.e., it is not horizontally scalable. 33 Max A. Alexejev
- 34. Max A. Alexejev QA Session And thank you for coming!
Editor's Notes
- #5: Add pictures
- #6: Add pictures
- #8: Add pictures
- #16: Well, sort em.
- #17: Didn’t I forget anything? Master-Master config, 4 example
- #24: Fix TBDs
- #25: Add picture
- #26: Check what Computational Grid really is
- #28: Add picture with partitions
- #30: TBD
- #31: TBD
- #32: TBD
- #33: Add picture
- #34: Add better pic with L1/L2/L3