From HDFS to S3: Migrate Pinterest Apache Spark Clusters
2 likes575 views

The document discusses Pinterest migrating their Apache Spark clusters from HDFS to S3 storage. Some key points: 1) Migrating to S3 provided significantly better performance due to the higher IOPS of modern EC2 instances compared to their older HDFS nodes. Jobs saw 25-35% improvements on average. 2) S3 is eventually consistent while HDFS is strongly consistent, so they implemented the S3Committer to handle output consistency issues during job failures. 3) Metadata operations like file moves were very slow in S3, so they optimized jobs to reduce unnecessary moves using techniques like multipart uploads to S3.



















































From HDFS to S3: Migrate Pinterest Apache Spark Clusters
- 2. From HDFS to S3: Migrate Pinterest Apache Spark Clusters Xin Yao, Daniel Dai Pinterest
- 3. About us Xin Yao [email protected] ▪ Tech Lead at Pinterest (Ads Team) ▪ Previously on Data Warehouse team at Facebook and Hulu Daniel Dai [email protected] ▪ Tech Lead at Pinterest (Data Team) ▪ PMC member for Apache Hive and Pig ▪ Previously work at Cloudera/Hortonworks and Yahoo
- 4. Agenda ▪ NextGen Big Data Platform ▪ Performance ▪ S3 Consistency ▪ Storage Difference ▪ Scheduling ▪ Spark at Pinterest
- 5. Agenda ▪ NextGen Big Data Platform ▪ Performance ▪ S3 Consistency ▪ Storage Difference ▪ Scheduling ▪ Spark at Pinterest
- 6. Big Data Platform Spark Hive Mesos/Aurora HDFS Kafka Presto ▪ Use Cases ▪ Ads ▪ Machine Learning ▪ Recommendations ▪ ...
- 7. Old vs New cluster Spark Hive Mesos/Aurora HDFS Kafka Old Cluster New Cluster Presto Spark Hive YARN S3 Kafka Presto
- 8. Agenda ▪ NextGen Big Data Platform ▪ Performance ▪ S3 Consistency ▪ Storage Difference ▪ Scheduling ▪ Spark at Pinterest
- 9. Identify Bottleneck of Old Cluster
- 10. Low local disk IOPS Slow Shuffle Slow Job Slow Workflow Old Cluster: Performance Bottleneck
- 11. Why Local Disk IO is important for Spark ▪ Spark mappers write shuffle data to local disk ▪ Spark mappers read local disk to serve shuffle data for reducer ▪ Spark spills data to local disk when data is bigger than memory
- 12. A Simple Aggregation Query SELECT id, max(value) FROM table GROUP BY id
- 13. 9k Mappers * 9k Reducers map map map ... reducer reducer reducer ... 9K Mappers Network 9k ReducersMapper Local Disk Mappers Reducers
- 14. 9k * 9k | One Mapper Machine map map reducer reducer reducer Local Disk 270k IO Ops Too many for our machine ... 30 Mappers ... One Mapper Machine | 30 Mappers Mapper machine ... ...
- 15. How to optimize jobs in old Cluster
- 16. Optimization. Reduce # of Mapper/Reducer map map map ... reducer reducer reducer ... 3K Mappers Network 3k Reducersmapper local disk input input input input input input input input input More files per Mapper NetworkMappers Reducers
- 17. Optimization map map map ... reducer reducer reducer input input input input input input input input input mapper local disk 30k Ops 9X better One Mapper Machine | 10 Mappers ... 10 Mappers ... Mapper machine ... input input input ...
- 18. Result
- 20. New Cluster: Choose the right EC2 instance Old Cluster New Cluster EC2 Node Local Disk IOPS Cap 3k 40k EC2 Node Type r4.16xlarge r5d.12xlarge EC2 Node CPU 64 vcores 48 vcores EC2 Node Mem 480 GB 372 GB
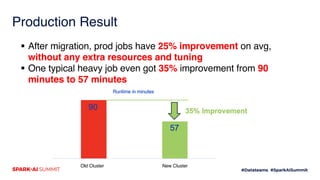
- 21. Production Result § After migration, prod jobs have 25% improvement on avg, without any extra resources and tuning § One typical heavy job even got 35% improvement from 90 minutes to 57 minutes Old Cluster New Cluster
- 22. Key Takeaways ▪ Measure before Optimize ▪ Premature optimization is the root of all evil
- 23. Key Takeaways ▪ Optimization could happen at different levels ▪ Cluster level ▪ New EC2 instance type ▪ Spark level ▪ Mapper number/cpu/mem tuning ▪ Job level ▪ Simplify logic
- 24. Agenda ▪ NextGen Big Data Platform ▪ Performance ▪ S3 Consistency ▪ Storage Difference ▪ Scheduling ▪ Spark at Pinterest
- 25. S3 != HDFS ▪ HDFS is a filesystem that is strong consistent. Changes are immediately visible ▪ S3 is an object storage service that is eventually consistent. There is no guarantee a change is immediately visible to the client. This might cause missing file issue without reader even know it.
- 26. Read after write consistency
- 27. Spark Job read less files from S3
- 28. How often does this happen ▪ Numbers from AWS: less than 1 in 10 million ▪ Numbers from our test: less than 1 in 50 million
- 29. Solution. Considerations ▪ Write Consistency ▪ Whether the job could write the output consistently, without partial or corrupted data as long as the job succeed. Even when some of the tasks failed or retried. ▪ Read Consistency ▪ Whether the job could read files in a folder, no more or less than it supposed to read. ▪ Monitor Consistency ▪ Requires Reader or Writer side change ▪ Query Performance
- 30. Solution. Considerations ▪ Storage ▪ Isolation ▪ Transaction ▪ Supports Spark ▪ Supports Hive/Presto ▪ Project Origin ▪ Adoption Effort
- 31. Solutions sorted by the complexity, simple => complex Raw S3 Data Quality Read Monitor Write Waiting Write Listing S3Committe r Consistent Listing S3Guard Iceberg Delta Lake Monitor Consistency No Partial Partial No No No N/A N/A N/A Write Consistency No No No No No Yes Yes Yes Yes Read Consistency No No Partial Partial Partial No Yes Yes Yes Reader/Writer change No No No Writer Writer Writer R/W R/W R/W Query Performance Normal Normal Normal Normal Normal Normal Normal Good Good Storage Normal Normal Normal Normal Normal Normal Normal Good Good Isolation No No No No No No No Strong Snapshot Strong Snapshot Transaction No No No No No No No Table Table Supports Spark Yes Yes Yes Yes Yes Yes Yes Yes Yes Supports Hive/Presto Yes Yes Yes Yes* Yes* Yes Yes WIP WIP Project Origin In House In House Not Exist Not Exist Not Exist Netflix OSS Hadoop 3.0 Apache Incubator Databricks OSS Effort None M M M M L XL XL
- 32. Our Approach ▪ Short Term ▪ S3 Committer ▪ Number of file monitor ▪ Data quality tool ▪ Long Term ▪ Systematical solutions
- 33. Agenda ▪ NextGen Big Data Platform ▪ Performance ▪ S3 Consistency ▪ Storage Difference ▪ Scheduling ▪ Spark at Pinterest
- 34. Performance Comparison: S3 vs HDFS ▪ Similar throughput ▪ Metadata operation is slow, especially move operation ▪ Our Spark streaming job is heavily impacted ▪ Spending most time moving output files around (3 times) 13s 55s Microbatch Runtime
- 35. Dealing with Metadata Operation ▪ Move file at least twice in a Spark Application ▪ commitTask ▪ commitJob ▪ May also move to the Hive table location output/_temporary/taskId/_temporary/taskAttemptID/part-xxxxxx output/_temporary/taskId/part-xxxxxx output/part-xxxxxx /warehouse/pinterest.db/table/date=20200626 commitTask commitJob Hive MoveTask df.write.mode(SaveMode.Append).insertInto(partitionedTable)
- 36. Reduce Move Operations ▪ FileOutputCommitter algorithm 2 ▪ spark.hadoop.mapreduce.fileoutputcommitter.algorithm.version=2 ▪ Skip move operation in job level, only task level ▪ DirectOutputCommitter ▪ Further skip move operation at task level ▪ Problem: File corruption when job fail ▪ Netflix s3committer ▪ spark.sql.sources.outputCommitterClass=com.netflix.bdp.s3.S3PartitionedOutputCommitter ▪ Use multi-part upload api, no move operation ▪ Other solutions ▪ Iceberg ▪ Hadoop s3acommitter
- 37. Multipart Upload API ▪ For every file ▪ initiateMultipartUpload ▪ Multiple uploadPart ▪ Finally completeMultipartUpload/abortMultipartUpload ▪ AWS will save all parts until completeMultipartUpload/abortMultipartUpload ▪ Setup a lifecycle policy ▪ Separate s3 permission for abortMultipartUpload
- 38. S3committer ▪ Upload File to Output Directly use multi-part upload api ▪ Atomic completeMultipartUpload leaves no corrupt output ▪ Parallel upload parts of a file to increase throughput uploadPart completeMultipartUpload commitTask commitJob
- 39. The Last Move Operation ▪ Before: Use staging directory to figure out the new partitions ▪ After: A table level tracking file for the new partitions ds=20200101 ds=20200102 ds=20200103 ds=20200104 ds=20200105 ds=20200106 ds=20200107 ds=20200108 ds=20200109 ds=20200110 ds=20200111 Table ds=20200112 Staging Directory .s3_dyn_parts ds=20200101 ds=20200102 ds=20200103 ds=20200104 ds=20200105 ds=20200106 ds=20200107 ds=20200108 ds=20200109 ds=20200110 ds=20200111 ds=20200112 Table ds=20200112
- 40. The Result 13s 11s Microbatch runtime 13s 55s Microbatch runtime HFDS S3 HFDS S3
- 41. Fix Bucket Rate Limit Issue (503) ▪ S3 bucket partition ▪ Task and Job level retry ▪ Tune the parallelism in part file uploads
- 42. Improving S3Committer ▪ Fix Bucket Rate Limit (503) ▪ Parallel upload parts of a file to increase throughput ▪ Integrity check of S3 multipart upload ETags ▪ Fix thread pool leaking for long-running application ▪ Remove local output early
- 43. S3 Benefit Compare to HDFS ▪ Reduce 80% storage cost ▪ S3: 99.99% availability, 99.999999999% durability ▪ HDFS: 99.9% target availability ▪ Namenode single point failure ▪ Potential data lost
- 44. Agenda ▪ NextGen Big Data Platform ▪ Performance ▪ S3 Consistency ▪ Storage Difference ▪ Scheduling ▪ Spark at Pinterest
- 45. Things We Miss in Mesos ▪ Manage services inside Mesos ▪ Simple workflow, long running job and cron job via Aurora ▪ Rolling restart ▪ Built-in health check
- 46. Things We Like in Yarn ▪ Global view of all running applications ▪ Better queue management for organization isolation ▪ Consolidate with the rest of clusters
- 47. Cost Saving ▪ We achieve cost savings with YARN ▪ Queue isolation ▪ Preemption
- 48. Agenda ▪ NextGen Big Data Platform ▪ Performance ▪ S3 Consistency ▪ Storage Difference ▪ Scheduling ▪ Spark at Pinterest
- 49. Spark at Pinterest ▪ We are still in the early stages ▪ Spark represents 12% of all compute resource usage ▪ Batch use case ▪ Mostly Scala, also PySpark
- 50. We Are Working On ▪ Automatic migration from Hive -> Spark SQL ▪ Cascading/Scalding -> Spark ▪ Adopting Dr Elephant for Spark ▪ Used for code review ▪ Integrate with internal metrics system ▪ Include features from Sparklens ▪ Spark history server performance
- 52. Feedback Your feedback is important to us. Don’t forget to rate and review the sessions.