From Java Stream to Java DataFrame
Download as PPTX, PDF30 likes2,740 views

该文档介绍了从 Java Stream 到 DataFrame(名为 Poppy)的转变,强调了在广告平台 Tenmax 中处理大量原始日志数据的需求。Poppy 是一种轻量级的 Java DataFrame 库,支持 column-based 操作和并行计算,旨在简化数据聚合过程,同时解决 Java Stream 在处理 column-based 数据方面的局限性。文档还讨论了数据处理的结构、操作和执行上下文。










































From Java Stream to Java DataFrame
- 1. 2 0 1 6 . 0 8 F r o m J a v a S t r e a m t o J a v a D a t a F r a m e P o p c o r n y ( 陸 振 恩 )
- 2. Outline • 動機 • 從Java Stream到DataFrame的歷程 • Poppy簡介 • Demo
- 3. 動機 • TenMax是一個廣告平台 • 廣告就是要看報表 • 所有發生的event我們稱為rawlog • rawlog每個小時產生一次Aggregated Data • 看報表時可以以選擇一個時間區間,根據某些維度(dimensions),可以看出某些數值(metrics) • 這是常見的OLAP技巧 Raw Log Aggregated Data (Cube) Batch aggregateIngest Interactive Query
- 5. RDBMS的困境 • 傳統的RDBMS不適合非常大量的Log Ingestion • 更適合的有 – DFS: 但是Append-Only的環境比較適合 – Cassandra/Hbase: 除了Insert, 還可以Row-based的update, delete, partition scan DFS or Cassandra RDBMS Batch aggregateIngest Interactive Query
- 7. Aggregation有哪些Solution • Computation Engine – Hadoop MapReduce – Hive – Spark SQL – Impala • 但是都有以下的缺點 – 原本的設計都是針對Cluster環境所設計 – Heavy weight – 過多的Dependency (如果要把driver包在自己的程式中) – 只對HDFS-Compatible的data source比較友善 – Job啟動速度 – 如果要定義自己的UDF / UDAF 會很複雜 – 學習門檻 – 維運門檻 – …..
- 9. 中數據 • 資料量 – 一天會新增1G ~ 1T uncompressed data • 假設 – 一筆record = 1K, 1T資料 = 10億筆資料 – CPU 1 core一秒可以處理1萬筆資料 – 四核一天可以處理34.56億筆資料 • 其實一台機器綽綽有餘 • 更何況雲端機器可以Scale up,到16核都不是問題 • I/O跟Network throughput漸漸不是瓶頸 • 單機跑的solution可以減少很多的overhead • 單程序跑的solution也好寫好debug
- 11. Java8 • 語言特色 Lambda • 三神器 – Stream – Optional – CompletableFuture
- 12. Java Stream • Functional Reactive Programming (FRP) • Pipeline Style,Input透過一站一站的transformation最後輸出到Output • Streaming的特性,非常少的Memory Footprint,可以處理非常大量的資料。 forEach()map() filter() flapMap() peek()
- 13. 那Aggregation呢?
- 14. 先了解一下SQL吧
- 15. From RawLog Where (DayRange) Group By sum(),sum(),sum() hour=?,dim1=?,dim2=? val1, val2, val3 sum(),sum(),sum() hour=?,dim1=?,dim2=? val1, val2, val3 sum(),sum(),sum() hour=?,dim1=?,dim2=? val1, val2, val3 sum(),sum(),sum() hour=?,dim1=?,dim2=? val1, val2, val3 sum(),sum(),sum() hour=?,dim1=?,dim2=? val1, val2, val3 sum(),sum(),sum() hour=?,dim1=?,dim2=? val1, val2, val3
- 16. Java Stream Aggregation From Where GroupBy Aggregation count(), sum()
- 17. 然後Mapper是
- 18. 然後Reducer是
- 20. Java Stream • 對於這種應用好像有點複雜 • 不太好用的平行處理 • java.util.stream.Collector對於多metrics的aggregation很麻煩 • 有些時候我們想要的是Column Based的操作,而不是單純的對一個Type操作
- 22. Introduction to Poppy • Poppy是一個Java的DataFrame Library • 什麼是Data Frame? – Column based (Schema) – 可以做類似RDBMS的相關操作 select, from, where, group by, aggregation, order by • Poppy還有以下特色 – Stream based (適合較大數據) – 支援partition以及平行計算 – User Defined Function, User Defined Aggregation Function – Lightweight • 其實就是有Schema版本的Java Stream http://tenmax.github.io/poppy/
- 24. Poppy • Pipeline分成三部分 – Input – Operations – Output http://tenmax.github.io/poppy/ OutputOperation Operation Operation OperationInput
- 25. Input • By Iterable DataFrame.from(Class<T> clazz, java.util.Iterable... iterables) • By DataSource DataFrame.from(io.tenmax.DataSource dataSource) • 其中DataSource的定義是 http://tenmax.github.io/poppy/
- 26. Output • iterator(), forEach() • toList(),toMap(), print() • DataFrame.to(DataSink dataSink) • 其中DataSink的定義是 http://tenmax.github.io/poppy/
- 27. Operations • project() • filter() • Aggregation() • groupby() • Sort() • distinct() • peek() • cache() http://tenmax.github.io/poppy/
- 28. Projection (Select) http://tenmax.github.io/poppy/
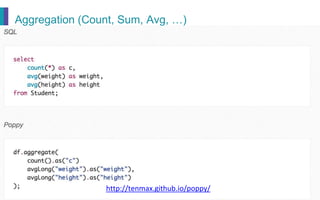
- 30. Aggregation (Count, Sum, Avg, …) http://tenmax.github.io/poppy/
- 34. User-Defined Function http://tenmax.github.io/poppy/ • 使用 java.util.function,Function<T,R>
- 35. User-Defined Aggregation Function http://tenmax.github.io/poppy/ • 使用 java.util.stream,Collector<T,A,R>
- 36. 平行計算 • Partition是平行的基本單位 • 一個DataSource可以提供多個Partition • 透過dataFrame.parallel(n)來決定平行的thread個數 http://tenmax.github.io/poppy/
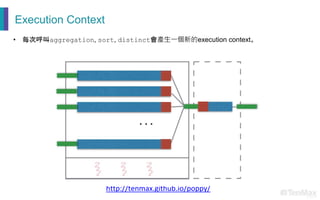
- 37. Execution Context • 一個Execution Context代表的是一個thread pool。 • 在其中可能有 n 個threads,以及 m 個partitions • 通常m >= n,每個thread在處理完一個partition之後,會去拉下一個還未處理的partition http://tenmax.github.io/poppy/
- 38. Execution Context • 每次呼叫aggregation, sort, distinct會產生一個新的execution context。 http://tenmax.github.io/poppy/
- 40. Conclusion • Java Stream對於Column-based的需求不太容易處理。 • 我們提供的DataFrame Library – Poppy提供了更簡單的方法來處理Column-based的資料。 • 可以很輕易的平行化來處理大量的資料。 • 但是又非常的lightweight http://tenmax.github.io/poppy/
- 41. Conclusion • Java Stream對於Column-based的需求不太容易處理。 • 我們提供的DataFrame Library – Poppy提供了更簡單的方法來處理Column-based的資料。 • 可以很輕易的平行化來處理大量的資料。 • 但是又非常的lightweight http://tenmax.github.io/poppy/
- 42. Reference • Project Site - http://tenmax.github.io/poppy/ • Poppy User Manual - http://tenmax.github.io/poppy/ • Poppy Javadoc - http://tenmax.github.io/poppy/docs/javadoc/index.html • Java多執行緒的基本知識 - https://www.gitbook.com/book/popcornylu/java_multithread/details • pq - https://github.com/tenmax/pq http://tenmax.github.io/poppy/