From Postgres to Cassandra (Rimas Silkaitis, Heroku) | C* Summit 2016
Download as PPTX, PDF4 likes2,576 views

The document discusses the transition from PostgreSQL to Cassandra, highlighting key differences between SQL and NoSQL databases and the advantages of using Cassandra, such as linear scalability and flexible data models. It provides detailed instructions on setting up tables in Cassandra, including primary keys, partitioning, and replication strategies. Additionally, it addresses challenges with data types and offers general tips for efficiently querying data in Cassandra.













































![SQL-like
[sēkwel lahyk]
adjective
Resembling SQL in appearance,
behavior or character
adverb
In the manner of SQL](https://image.slidesharecdn.com/2016-cassandra-summit-from-postgres-to-cassandra-160926060610/85/From-Postgres-to-Cassandra-Rimas-Silkaitis-Heroku-C-Summit-2016-46-320.jpg)














































From Postgres to Cassandra (Rimas Silkaitis, Heroku) | C* Summit 2016
- 1. Rimas Silkaitis From Postgres to Cassandra
- 2. NoSQL vs SQL
- 3. ||
- 4. &&
- 7. app cloud
- 10. $ git push heroku master Counting objects: 11, done. Delta compression using up to 8 threads. Compressing objects: 100% (10/10), done. Writing objects: 100% (11/11), 22.29 KiB | 0 bytes/s, done. Total 11 (delta 1), reused 0 (delta 0) remote: Compressing source files... done. remote: Building source: remote: remote: -----> Ruby app detected remote: -----> Compiling Ruby remote: -----> Using Ruby version: ruby-2.3.1
- 11. Heroku Postgres Over 1 Million Active DBs
- 12. Heroku Redis Over 100K Active Instances
- 13. Apache Kafka on Heroku
- 14. Runtime
- 15. Runtime Workers
- 16. $ psql psql => d List of relations schema | name | type | owner --------+----------+-------+----------- public | users | table | neovintage public | accounts | table | neovintage public | events | table | neovintage public | tasks | table | neovintage public | lists | table | neovintage
- 21. $ psql psql => d List of relations schema | name | type | owner --------+----------+-------+----------- public | users | table | neovintage public | accounts | table | neovintage public | events | table | neovintage public | tasks | table | neovintage public | lists | table | neovintage
- 22. Site Traffic Events * Totally Not to Scale
- 24. CREATE TABLE users ( id bigserial, account_id bigint, name text, email text, encrypted_password text, created_at timestamptz, updated_at timestamptz ); CREATE TABLE accounts ( id bigserial, name text, owner_id bigint, created_at timestamptz, updated_at timestamptz );
- 25. CREATE TABLE events ( user_id bigint, account_id bigint, session_id text, occurred_at timestamptz, category text, action text, label text, attributes jsonb );
- 26. Table
- 27. events
- 29. $ psql neovintage::DB=> e INSERT INTO events ( user_id, account_id, category, action, created_at) VALUES (1, 2, “in_app”, “purchase_upgrade” “2016-09-07 11:00:00 -07:00”);
- 31. Constraints • Data has little value after a period of time • Small range of data has to be queried • Old data can be archived or aggregated
- 32. There’s A Better Way
- 33. &&
- 35. $ psql psql => d List of relations schema | name | type | owner --------+----------+-------+----------- public | users | table | neovintage public | accounts | table | neovintage public | events | table | neovintage public | tasks | table | neovintage public | lists | table | neovintage
- 36. Why Introduce Cassandra? • Linear Scalability • No Single Point of Failure • Flexible Data Model • Tunable Consistency
- 38. I only know relational databases. How do I do this?
- 42. Postgres is Typically Run as Single Instance*
- 43. • Partitioned Key-Value Store • Has a Grouping of Nodes (data center) • Data is distributed amongst the nodes
- 44. Cassandra Cluster with 2 Data Centers
- 46. SQL-like [sēkwel lahyk] adjective Resembling SQL in appearance, behavior or character adverb In the manner of SQL
- 47. s Talk About Primary K Partition
- 48. Table
- 49. Partition Key
- 51. • 5 Node Cluster • Simplest terms: Data is partitioned amongst all the nodes using the hashing function.
- 53. Replication Factor Setting this parameter tells Cassandra how many nodes to copy incoming the data to This is a replication factor of 3
- 54. But I thought Cassandra had tables?
- 55. Prior to 3.0, tables were called column families
- 56. Let’s Model Our Events Table in Cassandra
- 58. We’re not going to go through any setup Plenty of tutorials exist for that sort of thing Let’s assume were working with 5 node cluster
- 59. $ psql neovintage::DB=> d events Table “public.events" Column | Type | Modifiers ---------------+--------------------------+----------- user_id | bigint | account_id | bigint | session_id | text | occurred_at | timestamp with time zone | category | text | action | text | label | text | attributes | jsonb |
- 60. $ cqlsh cqlsh> CREATE KEYSPACE IF NOT EXISTS neovintage_prod WITH REPLICATION = { ‘class’: ‘NetworkTopologyStrategy’, ‘us-east’: 3 };
- 61. $ cqlsh cqlsh> CREATE SCHEMA IF NOT EXISTS neovintage_prod WITH REPLICATION = { ‘class’: ‘NetworkTopologyStrategy’, ‘us-east’: 3 };
- 62. KEYSPACE == SCHEMA • CQL can use KEYSPACE and SCHEMA interchangeably • SCHEMA in Cassandra is somewhere between `CREATE DATABASE` and `CREATE SCHEMA` in Postgres
- 63. $ cqlsh cqlsh> CREATE SCHEMA IF NOT EXISTS neovintage_prod WITH REPLICATION = { ‘class’: ‘NetworkTopologyStrategy’, ‘us-east’: 3 }; Replication Strategy
- 64. $ cqlsh cqlsh> CREATE SCHEMA IF NOT EXISTS neovintage_prod WITH REPLICATION = { ‘class’: ‘NetworkTopologyStrategy’, ‘us-east’: 3 }; Replication Factor
- 65. Replication Strategies • NetworkTopologyStrategy - You have to define the network topology by defining the data centers. No magic here • SimpleStrategy - Has no idea of the topology and doesn’t care to. Data is replicated to adjacent nodes.
- 66. $ cqlsh cqlsh> CREATE TABLE neovintage_prod.events ( user_id bigint primary key, account_id bigint, session_id text, occurred_at timestamp, category text, action text, label text, attributes map<text, text> );
- 67. Remember the Primary Key? • Postgres defines a PRIMARY KEY as a constraint that a column or group of columns can be used as a unique identifier for rows in the table. • CQL shares that same constraint but extends the definition even further. Although the main purpose is to order information in the cluster. • CQL includes partitioning and sort order of the data on disk (clustering).
- 68. $ cqlsh cqlsh> CREATE TABLE neovintage_prod.events ( user_id bigint primary key, account_id bigint, session_id text, occurred_at timestamp, category text, action text, label text, attributes map<text, text> );
- 69. Single Column Primary Key • Used for both partitioning and clustering. • Syntactically, can be defined inline or as a separate line within the DDL statement.
- 70. $ cqlsh cqlsh> CREATE TABLE neovintage_prod.events ( user_id bigint, account_id bigint, session_id text, occurred_at timestamp, category text, action text, label text, attributes map<text, text>, PRIMARY KEY ( (user_id, occurred_at), account_id, session_id ) );
- 71. $ cqlsh cqlsh> CREATE TABLE neovintage_prod.events ( user_id bigint, account_id bigint, session_id text, occurred_at timestamp, category text, action text, label text, attributes map<text, text>, PRIMARY KEY ( (user_id, occurred_at), account_id, session_id ) ); Composite Partition Key
- 72. $ cqlsh cqlsh> CREATE TABLE neovintage_prod.events ( user_id bigint, account_id bigint, session_id text, occurred_at timestamp, category text, action text, label text, attributes map<text, text>, PRIMARY KEY ( (user_id, occurred_at), account_id, session_id ) ); Clustering Keys
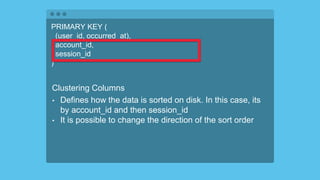
- 73. PRIMARY KEY ( (user_id, occurred_at), account_id, session_id ) Composite Partition Key • This means that both the user_id and the occurred_at columns are going to be used to partition data. • If you were to not include the inner parenthesis, the the first column listed in this PRIMARY KEY definition would be the sole partition key.
- 74. PRIMARY KEY ( (user_id, occurred_at), account_id, session_id ) Clustering Columns • Defines how the data is sorted on disk. In this case, its by account_id and then session_id • It is possible to change the direction of the sort order
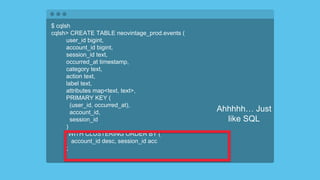
- 75. $ cqlsh cqlsh> CREATE TABLE neovintage_prod.events ( user_id bigint, account_id bigint, session_id text, occurred_at timestamp, category text, action text, label text, attributes map<text, text>, PRIMARY KEY ( (user_id, occurred_at), account_id, session_id ) ) WITH CLUSTERING ORDER BY ( account_id desc, session_id acc ); Ahhhhh… Just like SQL
- 76. Data TypesTypes
- 77. Postgres Type Cassandra Type bigint bigint int int decimal decimal float float text text varchar(n) varchar blob blob json N/A jsonb N/A hstore map<type>, <type>
- 78. Postgres Type Cassandra Type bigint bigint int int decimal decimal float float text text varchar(n) varchar blob blob json N/A jsonb N/A hstore map<type>, <type>
- 79. Challenges • JSON / JSONB columns don't have 1:1 mappings in Cassandra • You’ll need to nest MAP type in Cassandra or flatten out your JSON • Be careful about timestamps!! Time zones are already challenging in Postgres. • If you don’t specify a time zone in Cassandra the time zone of the coordinator node is used. Always specify one.
- 81. General Tips • Just like Table Partitioning in Postgres, you need to think about how you’re going to query the data in Cassandra. This dictates how you set up your keys. • We just walked through the semantics on the database side. Tackling this change on the application-side is a whole extra topic. • This is just enough information to get you started.
- 83. Runtime Workers
- 84. Runtime Workers
- 86. fdw
- 87. We’re not going to go through any setup, again…….. https://bitbucket.org/openscg/cassandra_fdw
- 88. $ psql neovintage::DB=> CREATE EXTENSION cassandra_fdw; CREATE EXTENSION
- 89. $ psql neovintage::DB=> CREATE EXTENSION cassandra_fdw; CREATE EXTENSION neovintage::DB=> CREATE SERVER cass_serv FOREIGN DATA WRAPPER cassandra_fdw OPTIONS (host ‘127.0.0.1'); CREATE SERVER
- 90. $ psql neovintage::DB=> CREATE EXTENSION cassandra_fdw; CREATE EXTENSION neovintage::DB=> CREATE SERVER cass_serv FOREIGN DATA WRAPPER cassandra_fdw OPTIONS (host ‘127.0.0.1'); CREATE SERVER neovintage::DB=> CREATE USER MAPPING FOR public SERVER cass_serv OPTIONS (username 'test', password ‘test'); CREATE USER
- 91. $ psql neovintage::DB=> CREATE EXTENSION cassandra_fdw; CREATE EXTENSION neovintage::DB=> CREATE SERVER cass_serv FOREIGN DATA WRAPPER cassandra_fdw OPTIONS (host ‘127.0.0.1'); CREATE SERVER neovintage::DB=> CREATE USER MAPPING FOR public SERVER cass_serv OPTIONS (username 'test', password ‘test'); CREATE USER neovintage::DB=> CREATE FOREIGN TABLE cass.events (id int) SERVER cass_serv OPTIONS (schema_name ‘neovintage_prod', table_name 'events', primary_key ‘id'); CREATE FOREIGN TABLE
- 92. neovintage::DB=> INSERT INTO cass.events ( user_id, occurred_at, label ) VALUES ( 1234, “2016-09-08 11:00:00 -0700”, “awesome” );
- 94. Some Gotchas • No Composite Primary Key Support in cassandra_fdw • No support for UPSERT • Postgres 9.5+ and Cassandra 3.0+ Supported