




































![Computing LDA
Inputs:
word[d][i] document words
k # topics
a doc topic concentration
b topic word concentration
Also:
n # docs
len[d] # words in document
v vocabulary size](https://image.slidesharecdn.com/lecture2textanalysis1-181004175354/85/Frontiers-of-Computational-Journalism-week-2-Text-Analysis-42-320.jpg)
![Computing LDA
Outputs:
topics[n][i] doc/word topic assignments
topic_words[k][v] topic words dist
doc_topics[n][k] document topics dist](https://image.slidesharecdn.com/lecture2textanalysis1-181004175354/85/Frontiers-of-Computational-Journalism-week-2-Text-Analysis-43-320.jpg)
![topics -> topic_words
topic_words[*][*] = b
for d=1..n
for i=1..len[d]
topic_words[topics[d][i]][word[d][i]] += 1
for j=1..k
normalize topic_words[j]](https://image.slidesharecdn.com/lecture2textanalysis1-181004175354/85/Frontiers-of-Computational-Journalism-week-2-Text-Analysis-44-320.jpg)
![topics -> doc_topics
doc_topics[*][*] = a
for d=1..n
for i=1..len[d]
doc_topics[d][topics[d][i]] +=1
for d=1..n
normalize doc_topics[d]](https://image.slidesharecdn.com/lecture2textanalysis1-181004175354/85/Frontiers-of-Computational-Journalism-week-2-Text-Analysis-45-320.jpg)
![Update topics
// for each word in document, sample a new topic
for d=1..n
for i=1..len[d]
w = word[d][i]
for t=1..k
p[t] = doc_topics[d][j] * topic_words[j][w]
topics[d][i] = sample from p[t]](https://image.slidesharecdn.com/lecture2textanalysis1-181004175354/85/Frontiers-of-Computational-Journalism-week-2-Text-Analysis-46-320.jpg)




















![A number of previous tools aim to help the user “explore” a
document collection (such as [6, 9, 10, 12]), though few of
these tools have been evaluated with users from a specific
target domain who bring their own data, making us suspect
that this imprecise term often masks a lack of understanding
of actual user tasks.
Overview: The Design, Adoption, and Analysis of a Visual Document
Mining Tool For Investigative Journalists, Brehmer et al, 2014](https://image.slidesharecdn.com/lecture2textanalysis1-181004175354/85/Frontiers-of-Computational-Journalism-week-2-Text-Analysis-68-320.jpg)











Frontiers of Computational Journalism week 2 - Text Analysis
- 1. Frontiers of Computational Journalism Columbia Journalism School Week 2: Text Analysis September 15, 2017
- 2. This class • The Overview document mining platform • Newsblaster • Topic models • Word Embeddings • Word counting again • Hard NLP problems in Journalism
- 3. The Overview Document Mining System
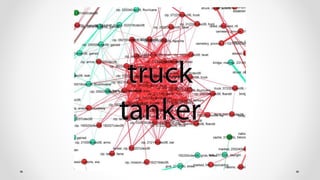
- 4. Clustering of Iraq War Logs, Dec 2010
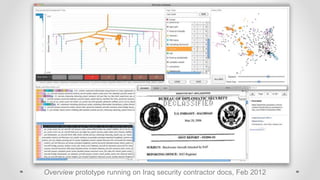
- 6. Overview prototype running on Iraq security contractor docs, Feb 2012
- 9. Used Overview’s “topic tree” (TF-IDF clustering) to find a group of key emails from a listserv. Summer 2013.
- 10. Technical troubles with a new system meant that almost 70,000 North Carolina residents received their food stamps late this summer. That’s 8.5 percent of the number of clients the state currently serves every month. The problem was eventually traced to web browser compatibility issues. WRAL reporter Tyler Dukes obtained 4,500 pages of emails — on paper — from various government departments and used DocumentCloud and Overview to piece together this story. https://blog.overviewdocs.com/completed-stories/
- 11. Finalist, 2014 Pulitzer Prize in Public Service
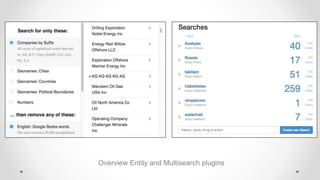
- 13. Overview Entity and Multisearch plugins
- 14. Newsblaster (your basic news aggregator architecture)
- 17. Scrape Handcrafted list of source URLs (news front pages) and links followed to depth 4 “For each page examined, if the amount of text in the largest cell of the page (after stripping tags and links) is greater than some particular constant (currently 512 characters), it is assumed to be a news article, and this text is extracted.” (At least it’s simple. This was 2002. How often does this work now?)
- 18. Text extraction from HTML Now multiple services/apis to do this, e.g. Mercury
- 19. Cluster Events
- 20. Cluster Events Surprise! • encode articles into feature vectors • cosine distance function • hierarchical clustering algorithm
- 21. But news is an on-line problem... Articles arrive one at a time, and must be clustered immediately. Can’t look forward in time, can’t go back and reassign. Greedy algorithm.
- 22. Single pass clustering put first story in its own cluster repeat get next story S look for cluster C with distance < T if found put S in C else put S in new cluster
- 23. Now sort events into categories Categories: U.S., World, Finance, Science and Technology, Entertainment, Sports. Primitive operation: what topic is this story in?
- 24. TF-IDF, again Each category has pre-assigned TF-IDF coordinate. Story category = closest point. “finance” category “world”category latest story
- 25. Cluster summarization Problem: given a set of documents, write a sentence summarizing them. Active research area in AI. Recent progress with recurrent neural network techniques. But initial algorithms go back to 1950s.
- 26. Generating News Headlines with Recurrent Neural Networks, Konstantin Lopyrev
- 27. Topic Modeling – Matrix Techniques
- 28. We used a machine-learning method known as latent Dirichlet allocation to identify the topics in all 14,400 petitions and to then categorize the briefs. This enabled us to identify which lawyers did which kind of work for which sorts of petitioners. For example, in cases where workers sue their employers, the lawyers most successful getting cases before the court were far more likely to represent the employers rather than the employees. The Echo Chamber, Reuters
- 29. Problem Statement Can the computer tell us the “topics” in a document set? Can the computer organize the documents by “topic”? Note: TF-IDF tells us the topics of a single document, but here we want topics of an entire document set.
- 30. One simple technique Sum TF-IDF scores for each word across entire document set, choose top ranking words. Cluster descriptions in Overview prototype generated this way
- 31. Topic Modeling Algorithms Basic idea: reduce dimensionality of document vector space, so each dimension is a topic. Each document is then a vector of topic weights. We want to figure out what dimensions and weights give a good approximation of the full set of words in each document. Many variants: LSI, PLSI, LDA, NMF
- 32. Matrix Factorization Approximate term-document matrix V as product of two lower rank matrixes V W H = m docs by n terms m docs by r "topics" r "topics" by n terms
- 33. Matrix Factorization A "topic" is a group of words that occur together. words in this topic topics in this document
- 34. Non-negative Matrix Factorization All elements of document coordinate matrix W and topic matrix H must be >= 0 Simple iterative algorithm to compute. Still have to choose number of topics r
- 36. Latent Dirichlet Allocation Imagine that each document is written by someone going through the following process: 1. For each doc d, choose mixture of topics p(z|d) 2. For each word w in d, choose a topic z from p(z|d) 3. Then choose word from p(w|z) A document has a distribution of topics. Each topic is a distribution of words. LDA tries to find these two sets of distributions.
- 37. "Documents" LDA models each document as a distribution over topics. Each word belongs to a single topic.
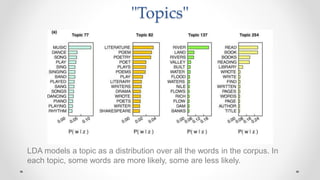
- 38. "Topics" LDA models a topic as a distribution over all the words in the corpus. In each topic, some words are more likely, some are less likely.
- 41. K topics topic for word word in doc topics in doc topic concentration parameter word concentration parameter LDA Plate Notation D docs words in topics N words in doc
- 42. Computing LDA Inputs: word[d][i] document words k # topics a doc topic concentration b topic word concentration Also: n # docs len[d] # words in document v vocabulary size
- 43. Computing LDA Outputs: topics[n][i] doc/word topic assignments topic_words[k][v] topic words dist doc_topics[n][k] document topics dist
- 44. topics -> topic_words topic_words[*][*] = b for d=1..n for i=1..len[d] topic_words[topics[d][i]][word[d][i]] += 1 for j=1..k normalize topic_words[j]
- 45. topics -> doc_topics doc_topics[*][*] = a for d=1..n for i=1..len[d] doc_topics[d][topics[d][i]] +=1 for d=1..n normalize doc_topics[d]
- 46. Update topics // for each word in document, sample a new topic for d=1..n for i=1..len[d] w = word[d][i] for t=1..k p[t] = doc_topics[d][j] * topic_words[j][w] topics[d][i] = sample from p[t]
- 47. Dimensionality reduction Output of NMF and LDA is a vector of much lower dimension for each document. ("Document coordinates in topic space.") Dimensions are “concepts” or “topics” instead of words. Can measure cosine distance, cluster, etc. in this new space.
- 49. Word Embedding
- 50. More than a Million Pro-Repeal Net Neutrality Comments were Likely Faked, Jeff Kao
- 51. Word vectors with semantics Word embedding is a function f(w) which maps a string (word) to a vector with ~200 dimensions. We hope that words with similar meanings have similar vectors. Then we can do things like: - Compare the meaning of two words - Compare the meaning of two sentences - Classify words/sentences by topic - Implement semantic search …basically everything we use TF-IDF for.
- 52. Distributional Semantics The distributional hypothesis in linguistics is derived from the semantic theory of language usage, i.e. words that are used and occur in the same contexts tend to have similar meanings. The underlying idea that "a word is characterized by the company it keeps" was popularized by Firth. - Wikipedia
- 53. Autoencoder
- 54. Train network to predict word from context Word2Vec Tutorial - The Skip-Gram Model, Chris McCormick
- 55. Captures word use semantics king – man + woman = queen paris – france + poland = warsaw Capturing semantic meanings using deep learning, Lior Shkiller
- 56. Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings, Bolukbasi1 et al.
- 57. More than a Million Pro-Repeal Net Neutrality Comments were Likely Faked, Jeff Kao
- 59. How much influence does the media really have over elections? Digging into the data, Jonathan Stray Many stories can be done with word counts
- 60. Mediacloud – many media sources
- 61. Google ngram viewer - 12% of all English books
- 62. Comparing two document sets Let me talk about Downton Abbey for a minute. The show's popularity has led many nitpickers to draft up lists of mistakes. ... But all of these have relied, so far as I can tell, on finding a phrase or two that sounds a bit off, and checking the online sources for earliest use. I lack such social graces. So I thought: why not just check every single line in the show for historical accuracy? ... So I found some copies of the Downton Abbey scripts online, and fed every single two-word phrase through the Google Ngram database to see how characteristic of the English Language, c. 1917, Downton Abbey really is. - Ben Schmidt, Making Downton more traditional
- 63. Bigrams that do not appear in English books between 1912 and 1921.
- 64. Bigrams that are at least 100 times more common today than they were in 1912-1921
- 66. Hard NLP problems in journalism
- 67. What is this investigative journalist doing with documents?
- 68. A number of previous tools aim to help the user “explore” a document collection (such as [6, 9, 10, 12]), though few of these tools have been evaluated with users from a specific target domain who bring their own data, making us suspect that this imprecise term often masks a lack of understanding of actual user tasks. Overview: The Design, Adoption, and Analysis of a Visual Document Mining Tool For Investigative Journalists, Brehmer et al, 2014
- 69. Computation + Journalism Symposium 9/2016
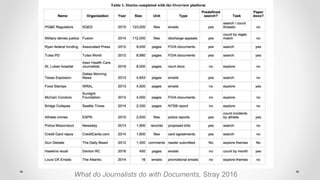
- 70. What do Journalists do with Documents, Stray 2016
- 71. What are the challenges that standard NLP doesn’t address?
- 72. Muckrock.com can automate some parts of the FOIA request process. Getting data is hard
- 73. Data is insanely contextual VICTS AND SUSPS BECAME INV IN VERBA ARGUMENT SUSP THEN BEGAN HITTING VICTS IN THE FACE Typical incident description processed by LA Times crime classifier
- 74. If your algorithm isn’t robust to input noise, don’t even bother Data is insanely dirty – OCR and more
- 75. Most NER implementations have low recall (~70%) Investigations would prefer higher recall, lower precision Entities found out of 150 Entity recognition is not solved!
- 76. Entity recognition that depends on parsing fails.
- 77. Suffolk County public safety committee transcript, Reference to a body left on the street due to union dispute (via Adam Playford, Newsday, 2014) Text search may not find the target
- 78. Journalists have problems well beyond state of the art of NLP
- 79. A document describing a modification to one of the loans used to finance the Trump Soho hotel (New York City ACRIS document 2006083000784001)
- 80. Excerpt of the hand-built chronological list of New York City real estate public records concerning the Trump Soho hotel. Color coding indicates documents on the same date (Giannina Segnini / Columbia Journalism School)
Editor's Notes
- #2: To open: Media cloud https://mediacloud.org/ Google ngram https://books.google.com/ngrams
- #5: https://blog.overviewdocs.com/2010/12/10/a-full-text-visualization-of-the-iraq-war-logs/
- #6: https://blog.overviewdocs.com/2010/12/10/a-full-text-visualization-of-the-iraq-war-logs/
- #9: https://blog.overviewdocs.com/2014/01/15/algorithms-are-not-enough-lessons-bringing-computer-science-to-journalism/
- #10: https://blog.overviewdocs.com/completed-stories/
- #11: https://source.opennews.org/articles/human-assisted-reporting/
- #27: https://nlp.stanford.edu/courses/cs224n/2015/reports/1.pdf
- #29: http://www.reuters.com/investigates/special-report/scotus/
- #42: https://www.cs.princeton.edu/~chongw/papers/WangBlei2011.pdf
- #51: https://hackernoon.com/more-than-a-million-pro-repeal-net-neutrality-comments-were-likely-faked-e9f0e3ed36a6
- #52: https://en.wikipedia.org/wiki/File:Autoencoder_structure.png
- #53: https://en.wikipedia.org/wiki/Distributional_semantics
- #54: https://en.wikipedia.org/wiki/File:Autoencoder_structure.png
- #55: https://en.wikipedia.org/wiki/File:Autoencoder_structure.png
- #56: https://www.oreilly.com/learning/capturing-semantic-meanings-using-deep-learnings-of-computational-linguistics/
- #57: https://arxiv.org/pdf/1607.06520.pdf
- #58: https://hackernoon.com/more-than-a-million-pro-repeal-net-neutrality-comments-were-likely-faked-e9f0e3ed36a6
- #60: http://www.niemanlab.org/2016/01/how-much-influence-does-the-media-really-have-over-elections-digging-into-the-data/
- #76: https://www.programmableweb.com/news/performance-comparison-10-linguistic-apis-entity-recognition/elsewhere-web/2016/11/03