Galaxy Big Data with MariaDB
Download as PPTX, PDF•5 likes•4,118 views

Galaxy Semiconductor's case study discusses their scalable big data architecture using MariaDB 10 to address data challenges, achieve high insertion rates, and ensure fail-safety. They highlight the implementation of partitioning, sharding, and compression techniques to handle substantial data volumes efficiently, achieving a peak insertion rate of 2 TB per day with significant data compression. Future steps involve enhancing monitoring capabilities and automating recovery processes to optimize the performance and reliability of their big data solutions.

























Galaxy Big Data with MariaDB
- 1. 1 Galaxy Semiconductor Intelligence Case Study: Big Data with MariaDB 10 Bernard Garros, Sandrine Chirokoff, Stéphane Varoqui
- 2. Galaxy confidential Galaxy Big Data scalability Menu • About Galaxy Semiconductor (BG) • The big data challenge (BG) • Scalable, fail-safe architecture for big data (BG) • MariaDB challenges: compression (SV) • MariaDB challenges: sharding (SC) • Results (BG) • Next Steps (BG) • Q&A 2
- 3. Galaxy confidential About Galaxy Semiconductor • A software company dedicated to semiconductor: Quality improvement Yield enhancement NPI acceleration Test cell OEE optimization • Founded in 1988 • Track record of building products that offer the best user experience + premier customer support • Products used by 3500+ users and all major ATE companies 3 via SEMICONDUCTOR INTELLIGENCE
- 4. Galaxy confidential 4 Galaxy Teo, Ireland HQ, G&A Galaxy East Sales, Marketing, Apps Galaxy France R&D, QA, & Apps Partner Taiwan Sales & Apps Partner Israel Sales Partner Singapore Sales & Apps Galaxy West Sales, Apps Partner Japan Sales & Apps Partner China Sales & Apps Worldwide Presence
- 5. Galaxy confidential Test Data production / consumption 5 ATE Test Data Files ETL, Data Cleansing Yield-Man Data Cube(s) ETL Galaxy TDR Examinator-Pro Browser-based dashboards Custom Agents Data Mining OEE Alarms PAT Automated Agents SYA
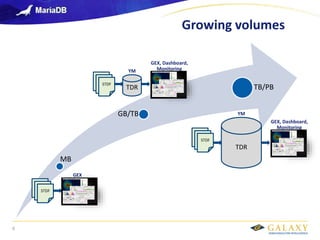
- 6. Galaxy confidential Growing volumes 6 MB GEX STDF STDF STDF GB/TB GEX, Dashboard, Monitoring TDR YM STDF STDF STDF TB/PB GEX, Dashboard, Monitoring TDR YM STDF STDF STDF
- 7. Galaxy confidential Big Data, Big Problem • More data can produce more knowledge and higher profits • Modern systems make it easy to generate more data • The problem is how to create a hardware and software platform that can make full and effective use of all this data as it continues to grow • Galaxy has the expertise to guide you to a solution for this big data problem that includes: – Real-time data streams – High data insertion rates – Scalable database to extreme data volumes – Automatic compensation for server failures – Use of inexpensive, commodity servers – Load balancing 7
- 8. Galaxy confidential First-level solutions • Partitioning – SUMMARY data • High level reports • 10% of the volume • Must be persistent for a long period (years) – RAW data • Detailed data inspection • 90% of the volume • Must be persistent for a short period (months) • PURGE – Partitioning per date (e.g. daily) on RAW data tables – Instant purge by drop partitions • Parallel insertion 8 Yield-Man Yield-Man Yield-Man
- 9. Galaxy confidential New customer use case 9 • Solution needs to be easily setup • Solution needs to handle large (~50TB+) data • Need to handle large insertion speed of approximately 2 MB/sec Solutions • Solution 1: Single scale-up node (lots of RAM, lots of CPU, expensive high-speed SSD storage, single point of failure, not scalable, heavy for replication) • Solution 2: Cluster of commodity nodes (see later)
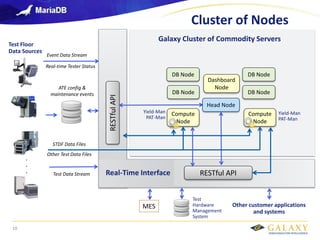
- 10. Galaxy confidential Cluster of Nodes Other customer applications and systems Other Test Data Files Event Data Stream ATE config & maintenance events Real-time Tester Status Test Floor Data Sources STDF Data Files . . . RESTful API RESTful API Test Hardware Management System MES Galaxy Cluster of Commodity Servers DB Node DB Node DB Node DB Node Compute Node Compute Node Head Node Dashboard Node Yield-Man PAT-Man Yield-Man PAT-Man Real-Time Interface Test Data Stream 10
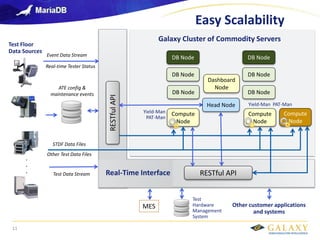
- 11. Galaxy confidential Easy Scalability Other customer applications and systems Other Test Data Files Event Data Stream ATE config & maintenance events Real-time Tester Status Test Floor Data Sources STDF Data Files . . . RESTful API Test Hardware Management System MES Galaxy Cluster of Commodity Servers DB Node DB Node DB Node DB Node Compute Node Compute Node Head Node Dashboard Node Yield-Man PAT-Man Yield-Man PAT-Man Real-Time Interface Test Data Stream DB Node DB Node Compute Node RESTful API 11
- 12. Galaxy confidential MariaDB challenges 12 ❏ From a single box to elastic architecture ❏ Reducing the TCO ❏ OEM solution ❏ Minimizing the impact on existing code ❏ Reach 200B records
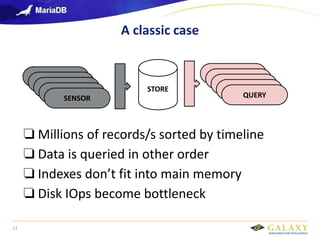
- 13. Galaxy confidential A classic case 13 SENSOR SENSOR SENSOR SENSOR SENSOR STORE QUERY QUERY QUERY QUERY QUERY ❏ Millions of records/s sorted by timeline ❏ Data is queried in other order ❏ Indexes don’t fit into main memory ❏ Disk IOps become bottleneck
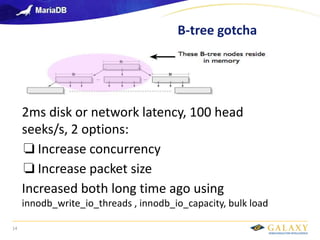
- 14. Galaxy confidential B-tree gotcha 14 2ms disk or network latency, 100 head seeks/s, 2 options: ❏ Increase concurrency ❏ Increase packet size Increased both long time ago using innodb_write_io_threads , innodb_io_capacity, bulk load
- 15. Galaxy confidential B-tree gotcha 15 With a Billion records, a single partition B-tree stops staying in main memory, a single write produces read IOps to traverse the tree: ❏ Use partitioning ❏ Insert in primary key order ❏ Big redo log and smaller amount of dirty pages ❏ Covering index The next step is to radically change the IO pattern
- 16. Galaxy confidential Data Structuring modeling 16 INDEXES MAINTENANCE NO INDEXES COLUMN STORE TTREE BTREE FRACTAL TREE STORE NDB InnoDB - MyISAM ZFS TokuDB LevelDB Cassandra Hbase InfiniDB Vertica MEMORY WRITE +++++ ++++ +++ +++++ +++++ READ 99% ++ + ++++ ++++++ READ 1% +++++ ++++ +++ ------- ------ DISK WRITE BTREE - +++ ++++ +++++ READ 99% - + ++++ +++++ READ 1% + +++ ----- -
- 17. Galaxy confidential INDEXES MAINTENANCE NO INDEXES COLUMN STORE TTREE BTREE FRACTAL TREE NDB InnoDB - MyISAM ZFS TokuDB LevelDB Cassandra Hbase InfiniDB Average Compression Rate NA 1/2 1/6 1/3 1/12 IO Size NA 4K to 64K Variable base on compression & Depth 64M 8M To 64M READ Disk Access Model NA O(Log(N)/ Log(B)) ~O(Log(N)/ Log(B)) O(N/B ) O(N/B - B Elimination) WRITE Disk Access Model NA O(Log(N)/ Log(B)) ~O(Log(N)/B) O(1/B ) O(1/B) Data Structure for big data 17
- 18. Galaxy confidential Top 10 Alexa’s PETA Bytes store is InnoDB 18 Top Alexa InnoDB Galaxy TokuDB ❏ DBA to setup Insert buffer + Dirty pages ❏ Admins to monitor IO ❏ Admins to increase # nodes ❏ Use flash & hybride storage ❏ DBAs to partition and shard ❏ DBAs to organize maintenance ❏ DBAs to set covering and clustering indexes ❏ Zipf read distribution ❏ Concurrent by design ❏ Remove fragmentation ❏ Constant insert rate regardless memory/disk ratio ❏ High compression rate ❏ No control over client architecture ❏ All indexes can be clustered
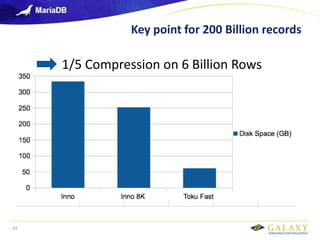
- 19. Galaxy confidential 19 1/5 Compression on 6 Billion Rows Key point for 200 Billion records
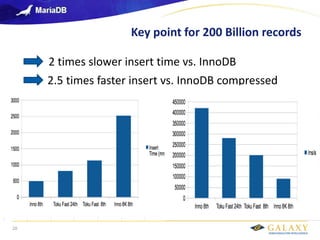
- 20. Galaxy confidential 20 2 times slower insert time vs. InnoDB 2.5 times faster insert vs. InnoDB compressed Key point for 200 Billion records
- 21. Galaxy confidential 21 ❏ Disk IOps on InnoDB was bottleneck, despite partitioning ❏ Moving to TokuDB, move bottleneck to CPU for compression ❏ So how to increase performance more? Sharding!! Galaxy take away for 200 Billion records
- 22. Galaxy confidential 22 INDEXES MAINTENANCE NO INDEXES COLUMN STORE TTREE BTREE FRACTAL TREE NDB InnoDB MyISAM ZFS TokuDB LevelDB Cassandra Hbase InfiniDB Vetica CLUSTERING Native Manual, Spider, Vitess, Fabric, Shardquery Manual, Spider, Vitess, Fabric, Shardquery Native Native # OF NODES +++++ +++ ++ +++++ + Sharding to fix CPU Bottleneck
- 23. Galaxy confidential 23 NO DATA IS STORED IN SPIDER NODES Spider… it’s a MED storage engine
- 24. Galaxy confidential 24 Preserve data consistency between shards Allow shard replica Enable joining between shards ha_spider.cc SEMI TRX
- 25. Galaxy confidential Spider - A Sharding + HA solution 25
- 26. Galaxy confidential Implemented architecture 26 SUMMARY universal tables RAW Sharded tables DATA NODE #1 COMPUTE NODE #1 … DATA NODE #2 DATA NODE #3 DATA NODE #4 HEAD NODE COMPUTE NODE #2 … •SPIDER •NO DATA •MONITORING •TOKUDB •COMPRESSED DATA •PARTITIONS Delay current insertion Replay insertion with new shard key 1/4 OR 1/2 1/4 OR 1/2 1/4 OR 1/2 1/4 OR 1/2
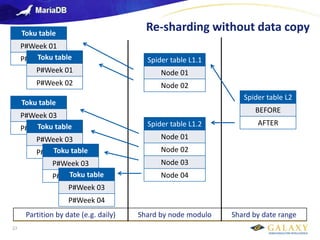
- 27. Galaxy confidential Re-sharding without data copy 27 Spider table L1.1 Node 01 Node 02 Spider table L1.2 Node 01 Node 02 Node 03 Node 04 Spider table L2 CURRENT Toku table P#Week 01 P#Week 02 Spider table L2 BEFORE AFTER Toku table P#Week 01 P#Week 02 Toku table P#Week 03 P#Week 04 Toku table P#Week 03 P#Week 04 Toku table P#Week 03 P#Week 04 Toku table P#Week 03 P#Week 04 Partition by date (e.g. daily) Shard by node modulo Shard by date range
- 28. Galaxy confidential Proven Performance 28 Galaxy has deployed its big data solution at a major test subcontractor in Asia with the following performance: • Peak data insertion rate : 2 TB of STDF data per day • Data compression of raw data : 60-80 % • DB retention of raw data : 3 months • DB retention of summary data : 1 year • Archiving of test data : Automatic • Target was 2MB/sec, we get about 10MB/sec • Since 17th June, steady production : – Constant insertion speed – 1400 files/day, 120 GB/day – ft_ptest_results: 92 billion rows / 1.5 TB across 4 nodes – ft_mptest_results: 14 billion rows / 266 GB acroos 4 nodes – wt_ptest_results: 9 billion rows / 153 GB across 4 nodes – 50TB available volume, total DB size is 8TB across all 4 nodes • 7 servers (22k$) + SAN ($$$) OR DAS (15k$)
- 29. Galaxy confidential File count inserted per day 29 • Integration issues up to May 7 • Raw & Summary-only data insertion up to May 18 • Raw & Summary data insertion, Problem solving, fine tuning up to June 16 • Steady production insertion of Raw & Summary data since June 17
- 30. Galaxy confidential File count and data size per day 30 • Up to 2TB inserted per day • Up to 20k files per day
- 31. Galaxy confidential Raw data insertion duration over file size (each colored series is 1 day) 31 Consistant insertion performance
- 32. Galaxy confidential What’s next? 32 • Make Yield-Man more SPIDER-aware: – Integrated scale-out (add compute/data nodes) – Native database schema upgrade on compute/data nodes • Add more monitoring capability to monitor SPIDER events (node failure, table desynchronization across nodes…) • Automate recover after failures/issues, today: – Manual script to detect de-synchronization – PT table sync from Percona to manually re-sync – Manual script to reintroduce table nodes in the cluster IN SPIDER 2014 ROADMAP