Getting Started on Hadoop
35 likes19,490 views

The document discusses a meetup focused on using Hadoop and AWS Elastic MapReduce for data processing, particularly illustrating the 'wordcount' example as a fundamental use case. It covers the architecture and workflow of MapReduce, including phases like mapping, shuffling, and reducing, as well as the significance of fault tolerance and scalability in cloud environments. Additionally, it highlights practical applications of text analytics using the Enron email dataset, showcasing techniques such as inverted index and social graph analysis.

































![Using R to Determine a Threshold…
data <- read.csv("thresh.tsv", sep='t', header=F)
t_data <- data[,3]
print(summary(t_data))
# pass through values for 80+ percentile
qntile <- .8
t_thresh <- quantile(t_data, qntile)
# CDF plot
title <- "CDF threshold max(tfidf)"
xtitle <- paste("thresh:", t_thresh)
par(mfrow=c(2, 1))
plot(ecdf(t_data), xlab=xtitle, main=title)
abline(v=t_thresh, col="red")
abline(h=qtile, col="yellow")
# box-and-whisker plot
boxplot(t_data, horizontal=TRUE)
rug(t_data, side=1)](https://image.slidesharecdn.com/enron-100719200921-phpapp01/85/Getting-Started-on-Hadoop-35-320.jpg)







Getting Started on Hadoop
- 1. Getting Started on Hadoop Silicon Valley Cloud Computing Meetup Mountain View, 2010-07-19 http://www.meetup.com/cloudcomputing/calendar/13911740/ Paco Nathan @pacoid http://ceteri.blogspot.com/ Examples of Hadoop Streaming, based on Python scripts running on the AWS Elastic MapReduce service. • first, a brief history… • AWS Elastic MapReduce • “WordCount” example as “Hello World” for MapReduce • text mining Enron Email Dataset from Infochimps.com • inverted index, semantic lexicon, social graph • data visualization using R and Gephi All source code for this talk is available at: http://github.com/ceteri/ceteri-mapred
- 2. How Does MapReduce Work? map(k1, v1) → list(k2, v2) reduce(k2, list(v2)) → list(v3) Several phases, which partition a problem into many tasks: • load data into DFS… • map phase: input split → (key, value) pairs, with optional combiner • shuffle phase: sort on keys to group pairs… load-test your network! • reduce phase: each task receives the values for one key • pull data from DFS… NB: “map” phase is required, the rest are optional. Think of set operations on tuples (and check out Cascading.org). Meanwhile, given all those (key, value) pairs listed above, it’s no wonder that key/value stores have become such a popular topic of conversation…
- 3. How Does MapReduce Work? map(k1, v1) → list(k2, v2) reduce(k2, list(v2)) → list(v3) The property of data independence among tasks allows for highly parallel processing… maybe, if the stars are all aligned :) Primarily, a MapReduce framework is largely about fault tolerance, and how to leverage “commodity hardware” to replace “big iron” solutions… That phrase “big iron” might apply to Oracle + NetApp. Or perhaps an IBM zSeries mainframe… Or something – expensive, undoubtably. Bonus questions for self-admitted math geeks: Foresee any concerns about O(n) complexity, given the functional definitions listed above? Keep in mind that each phase cannot conclude and progress to the next phase until after each of its tasks has successfully completed.
- 4. A Brief History… circa 1979 – Stanford, MIT, CMU, etc. set/list operations in LISP, Prolog, etc., for parallel processing http://www-formal.stanford.edu/jmc/history/lisp/lisp.htm circa 2004 – Google MapReduce: Simplified Data Processing on Large Clusters Jeffrey Dean and Sanjay Ghemawat http://labs.google.com/papers/mapreduce.html circa 2006 – Apache Hadoop, originating from the Nutch Project Doug Cutting http://research.yahoo.com/files/cutting.pdf circa 2008 – Yahoo web scale search indexing Hadoop Summit, HUG, etc. http://developer.yahoo.com/hadoop/ circa 2009 – Amazon AWS Elastic MapReduce Hadoop modified for EC2/S3, plus support for Hive, Pig, etc. http://aws.amazon.com/elasticmapreduce/
- 5. Why run Hadoop in AWS? • elastic: batch jobs on clusters can consume many nodes, scalable demand, not 24/7 – great case for using EC2 • commodity hardware: MR is built for fault tolerance, great case for leveraging AMIs • right-sizing: difficult to know a priori how large of a cluster is needed – without running significant jobs (test k/v skew, data quality, etc.) • when your input data is already in S3, SDB, EBS, RDS… • when your output needs to be consumed in AWS … You really don't want to buy rack space in a datacenter before assessing these issues – besides, a private datacenter probably won’t even be cost-effective afterward.
- 6. But why run Hadoop on Elastic MapReduce? • virtualization: Hadoop needs some mods to run well in that kind of environment • pay-per-drink: absorbs cost of launching nodes • secret sauce: Cluster Compute Instances (CCI) and Spot Instances (SI) • DevOps: EMR job flow mgmt optimizes where your staff spends their (limited) time+capital • logging to S3, works wonders for troubleshooting
- 7. A Tale of Two Ventures… Adknowledge: in 2008, our team became one of the larger use cases running Hadoop on AWS • prior to the launch of EMR • launching clusters of up to 100 m1.xlarge • initially 12 hrs/day, optimized down to 4 hrs/day • displaced $3MM capex for Netezza ShareThis: in 2009, our team used even more Hadoop on AWS than that previous team • this time with EMR • larger/more frequent jobs • lower batch failure rate • faster turnaround on results • excellent support • smaller team required • much less budget
- 8. “WordCount”, a “Hello World” for MapReduce Definition: count how often each word appears within a collection of text documents. A simple program which illustrates a pretty good test case for what MapReduce can perform, since it incorporates: • minimal amount code • document feature extraction (where words are “terms”) • symbolic and numeric values • potential use of a combiner • bipartite graph of (doc, term) tuples • not so many steps away from useful indexing… When a framework can run “WordCount” in parallel at scale, then it can handle much larger, more interesting compute problems as well.
- 9. Bipartite Graph Wikipedia: “…a bipartite graph is a graph whose vertices can be divided into two disjoint sets U and V such that every edge connects a vertex in U to one in V… ” http://en.wikipedia.org/wiki/Bipartite_graph Consider the case where: U ≡ { documents } V ≡ { terms } Many kinds of text analytics products can be constructed based on this data structure as a foundation.
- 10. “WordCount”, in other words… map(doc_id, text) → list(word, count) reduce(word, list(count)) → list(sum_count)
- 11. “WordCount”, in other words… void map (String doc_id, String text): for each word w in segment(text): emitPartial(w, "1"); void reduce (String word, Iterator partial_counts): int count = 0; for each pc in partial_counts: count += Int(pc); emitResult(String(count));
- 12. Hadoop Streaming One way to approach MapReduce jobs in Hadoop is to use streaming. In other words, use any kind of script which can be run from a command line and read/write data via stdin and stdout: http://hadoop.apache.org/common/docs/current/streaming.html#Hadoop+Streaming The following examples use Python scripts for Hadoop Streaming. One really great benefit is that then you can dev/test/debug your MapReduce code on small data sets from a command line simply by using pipes: cat input.txt | mapper.py | sort | reducer.py BTW, there are much better ways to handle Hadoop Streaming in Python on Elastic MapReduce – for example, using the “boto” library. However, these examples are kept simple so they’ll fit into a tech talk!
- 13. “WordCount”, in other words…
- 14. “WordCount”, in other words…
- 15. “WordCount”, in other words… # this Linux command line... cat foo.txt | map_wc.py | sort | red_wc.py # produces output like this... tuple 9 term 6 tfidf 6 sort 5 analysis 2 wordcount 1 user 1 # depending on input - # which could be HTML content, tweets, email, etc.
- 16. Speaking of Email… Enron pioneered innovative corporate accounting methods and energy market manipulations, involving a baffling array of fraud techniques. The firm soared to a valuation of over $60B (growing 56% in 1999, 87% in 2000) while inducing a state of emergency in California – which cost the state over $40B. Subsequent prosecution of top execs plus the meteoric decline in the firm’s 2001 share value made for a spectacular #EPIC #FAIL http://en.wikipedia.org/wiki/Enron_scandal http://en.wikipedia.org/wiki/California_electricity_crisis Thanks to CALO and Infochimps, we have a half million email messages collected from Enron managers during their, um, “heyday” period: http://infochimps.org/datasets/enron-email-dataset--2 http://www.cs.cmu.edu/~enron/ Let’s use Hadoop to help find out: what were some of the things those managers were talking about?
- 17. Simple Text Analytics Extending from how “WordCount” works, we’ll add multiple kinds of output tuples, plus two stages of mappers and reducers, to generate different kinds of text analytics products: • inverted index • co-occurrence analysis • TF-IDF filter • social graph While doing that, we'll also perform other statistical analysis and data visualization using R and Gephi
- 18. Mapper 1: RFC822 Parser map_parse.py takes a list of URI for where to read email messages, parses each message, then emits multiple kinds of output tuples: (doc_id, msg_uri, date) (sender, receiver, doc_id) (term, term_freq, doc_id) (term, co_term, doc_id) Note that our dataset includes approximately 500,000 email messages, with an average of about 100 words in each message. Also, there are 10E+5 unique terms. That will tend to be a constant in English texts, which is great to know when configuring capacity.
- 19. Reducer 1: TF-IDF and Co-Occurrence red_idf.py takes the shuffled output from map_parse.py, collects metadata for each term, calculates TF-IDF to use in a later stage for filtering, calculates co-occurrence probability, then emits all these results: (doc_id, msg_uri, date) (sender, receiver, doc_id) (term, idf, count) (term, co_term, prob_cooc) (term, tfidf, doc_id) (term, max_tfidf)
- 20. Mapper 1 + Reducer 1
- 21. Mapper 1 Output
- 22. Reducer 1 Output
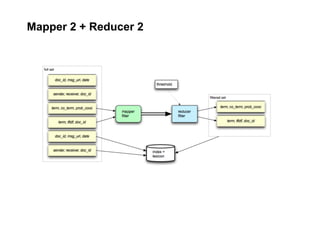
- 23. Mapper 2 + Reducer 2: Threshold Filter map_filter.py and red_filter.py apply a threshold (based on statistical analysis of TF-IDF) to filter results of co-occurrence analysis so that we begin to produce a semantic lexicon for exploring the data set. How do we determine a reasonable value for the TF-IDF threshold, for filtering terms? Sampling from the (term, max_tfidf) tuple, we run summary stats and visualization in R: cat dat.idf | util_extract.py m > thresh.tsv We also convert the sender/receiver social graph into CSV format for Gephi visualization: cat dat.parsed | util_extract.py s | util_gephi.py | sort -u > graph.csv
- 24. Mapper 2 + Reducer 2
- 25. Elastic MapReduce Job Flows…
- 26. Elastic MapReduce Job Flows…
- 27. Elastic MapReduce Job Flows…
- 28. Elastic MapReduce Job Flows…
- 29. Elastic MapReduce Job Flows…
- 30. Elastic MapReduce Job Flows…
- 31. Elastic MapReduce Job Flows…
- 32. Elastic MapReduce Job Flows…
- 33. Elastic MapReduce Output Part Files…
- 34. Exporting Data into Other Tools…
- 35. Using R to Determine a Threshold… data <- read.csv("thresh.tsv", sep='t', header=F) t_data <- data[,3] print(summary(t_data)) # pass through values for 80+ percentile qntile <- .8 t_thresh <- quantile(t_data, qntile) # CDF plot title <- "CDF threshold max(tfidf)" xtitle <- paste("thresh:", t_thresh) par(mfrow=c(2, 1)) plot(ecdf(t_data), xlab=xtitle, main=title) abline(v=t_thresh, col="red") abline(h=qtile, col="yellow") # box-and-whisker plot boxplot(t_data, horizontal=TRUE) rug(t_data, side=1)
- 36. Using R to Determine a Threshold… CDF threshold max(tfidf) 0.8 Fn(x) 0.4 0.0 0 2 4 6 8 thresh: 0.063252 0 1 2 3 4 5 6 7
- 37. Using Gephi to Explore the Social Graph…
- 38. Best Practices • Again, there are much more efficient ways to handle Hadoop Streaming and Text Analytics… • Unit Tests, Continuous Integration, etc., – all great stuff, but “Big Data” software engineering requires additional steps • Sample data, measure data ratios and cluster behaviors, analyze in R, visualize everything you can, calibrate any necessary “magic numbers” • Develop and test code on a personal computer in IDE, cmd line, etc., using a minimal data sets • Deploy to staging cluster with larger data sets for integration tests and QA • Run in production with A/B testing were feasible to evaluate changes quantitatively • Learn from others at meetups, unconfs, forums, etc.
- 39. Great Resources for Diving into Hadoop Google: Cluster Computing and MapReduce Lectures http://code.google.com/edu/submissions/mapreduce-minilecture/listing.html Amazon AWS Elastic MapReduce http://aws.amazon.com/elasticmapreduce/ Hadoop: The Definitive Guide, by Tom White http://oreilly.com/catalog/9780596521981 Apache Hadoop http://hadoop.apache.org/ Python “boto” interface to EMR http://boto.cloudhackers.com/emr_tut.html
- 40. Excellent Products for Hadoop in Production Datameer http://www.datameer.com/ “Democratizing Big Data” Designed for business users, Datameer Analytics Solution (DAS) builds on the power and scalability of Apache Hadoop to deliver an easy-to-use and cost-effective solution for big data analytics. The solution integrates rapidly with existing and new data sources to deliver sophisticated analytics. Cascading http://www.cascading.org/ Cascading is a feature-rich API for defining and executing complex, scale-free, and fault tolerant data processing workflows on a Hadoop cluster, which provides a thin Java library that sits on top of Hadoop's MapReduce layer. Open source in Java.
- 41. Scale Unlimited – Hadoop Boot Camp Santa Clara, 22-23 July 2010 http://www.scaleunlimited.com/courses/hadoop-bootcamp-santaclara • An extensive overview of the Hadoop architecture • Theory and practice of solving large scale data processing problems • Hands-on labs covering Hadoop installation, development, debugging • Common and advanced “Big Data” tasks and solutions Special $500 discount for SVCC Meetup members: http://hadoopbootcamp.eventbrite.com/?discount=DBDatameer Sample material – list of questions about intro Hadoop from the recent BigDataCamp: http://www.scaleunlimited.com/blog/intro-to-hadoop-at-bigdatacamp
- 42. Getting Started on Hadoop Silicon Valley Cloud Computing Meetup Mountain View, 2010-07-19 http://www.meetup.com/cloudcomputing/calendar/13911740/ Paco Nathan @pacoid http://ceteri.blogspot.com/ Examples of Hadoop Streaming, based on Python scripts running on the AWS Elastic MapReduce service. All source code for this talk is available at: http://github.com/ceteri/ceteri-mapred