












![MapReduce
• “Single Threaded” MapReduce:
cat input/* | map | sort | reduce > output
• Map program parses the input and emits [key,value] pairs
• Sort by key
Reduce
Map Sort
• Extrapolate to PB of data on thousands of nodes
© 2011 MyDrive Solutions Limited
15](https://image.slidesharecdn.com/hadoop-accu2010copy-110725071753-phpapp02/85/Introduction-to-Hadoop-ACCU2010-16-320.jpg)












Introduction to Hadoop - ACCU2010
- 1. MapReduce with Apache Hadoop Analysing Big Data April 2010 Gavin Heavyside [email protected]
- 2. About MyDrive Solutions • Founded in 2006 to develop software that addresses driving safety and risk, congestion, and fuel economy • Based in the Surrey Technology Centre, Guildford, UK • Analyse terabytes of GPS data from cars, vans & trucks • MyDrive® - Unique & sophisticated system that understands how drivers behave: Insurance companies can measure and understand driver risk Drivers can improve fuel economy Fleet managers can improve fleet safety & eco-driving © 2011 MyDrive Solutions Limited 2
- 3. Big Data • Data volumes increasing • NYSE: 1TB new trade data/day • Google: Processes 20PB/day (Sep 2007) http://tcrn.ch/agYjEL • LHC: 15PB data/year • Facebook: several TB photos uploaded/day © 2011 MyDrive Solutions Limited 3
- 4. “Medium” Data • Most of us aren’t at Google or Facebook scale • But: data at the GB/TB scale is becoming more common • Outgrow conventional databases • Disks are cheap, but slow • 1TB drive - £50 • 2.5 hours to read 1TB at 100MB/s © 2011 MyDrive Solutions Limited 4
- 5. Two Challenges • Managing lots of data • Doing something useful with it © 2011 MyDrive Solutions Limited 5
- 6. Managing Lots of Data • Access and analyse any or all of your data • SAN technologies (FC, iSCSI, NFS) • Querying (MySQL, PostgreSQL, Oracle) ➡ Cost, network bandwidth, concurrent access, resilience ➡ When you have 1000s of nodes, MTBF < 1 day © 2011 MyDrive Solutions Limited 6
- 7. Analysing Lots of Data • Parallel processing • HPC • Grid Computing • MPI • Sharding ➡ Too big for memory, specialised HW, complex, scalability ➡ Hardware reliability in large clusters © 2011 MyDrive Solutions Limited 7
- 8. Apache Hadoop • Reliable, scalable distributed computing platform • HDFS - high throughput fault-tolerant distributed file system • MapReduce - fault-tolerant distributed processing • Runs on commodity hardware • Cost-effective • Open source (Apache License) © 2011 MyDrive Solutions Limited 8
- 9. Hadoop History • 2003-2004 Google publishes MapReduce & GFS papers • 2004 Doug Cutting add DFS & MapReduce to Nutch • 2006 Cutting joins Yahoo!, Hadoop moves out of Nutch • Jan 2008 - top level Apache project • April 2010: 95 companies on PoweredBy Hadoop wiki • Yahoo!, Twitter, Facebook, Microsoft, New York Times, LinkedIn, Last.fm, IBM, Baidu, Adobe "The name my kid gave a stuffed yellow elephant. Short, relatively easy to spell and pronounce, meaningless, and not used elsewhere: those are my naming criteria. Kids are good at generating such. Googol is a kid's term" Doug Cutting © 2011 MyDrive Solutions Limited 9
- 10. Hadoop Ecosystem • HDFS • MapReduce • HBase • ZooKeeper • Pig • Hive • Chukwa • Avro © 2011 MyDrive Solutions Limited 10
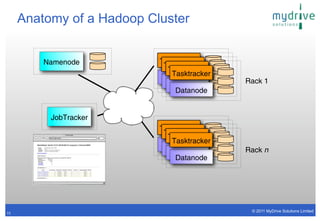
- 11. Anatomy of a Hadoop Cluster Namenode Tasktracker Tasktracker Tasktracker Tasktracker Datanode Rack 1 Datanode Datanode Datanode JobTracker Tasktracker Tasktracker Tasktracker Tasktracker Datanode Datanode Rack n Datanode Datanode © 2011 MyDrive Solutions Limited 11
- 12. HDFS • Reliable shared storage • Modelled after GFS • Very large files • Streaming data access • Commodity Hardware • Replication • Tolerate regular hardware failure © 2011 MyDrive Solutions Limited 12
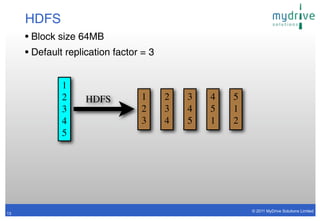
- 13. HDFS • Block size 64MB • Default replication factor = 3 1 2 HDFS 1 2 3 4 5 3 2 3 4 5 1 4 3 4 5 1 2 5 © 2011 MyDrive Solutions Limited 13
- 14. HDFS • Block size 64MB • Default replication factor = 3 1 2 HDFS 1 2 3 4 5 3 2 3 4 5 1 4 3 4 5 1 2 5 © 2011 MyDrive Solutions Limited 13
- 15. MapReduce • Based on 2004 Google paper • Concepts from Functional Programming • Used for lots of things within Google (and now everywhere) • Parallel Map => Shuffle & Sort => Parallel Reduce • Easy to understand and write MapReduce programs • Move the computation to the data • Rack-aware • Linear Scalability • Works with HDFS, S3, KFS, file:// and more © 2011 MyDrive Solutions Limited 14
- 16. MapReduce • “Single Threaded” MapReduce: cat input/* | map | sort | reduce > output • Map program parses the input and emits [key,value] pairs • Sort by key Reduce Map Sort • Extrapolate to PB of data on thousands of nodes © 2011 MyDrive Solutions Limited 15
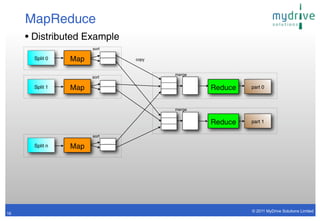
- 17. MapReduce • Distributed Example sort Split 0 Map copy merge sort Split 1 Map Reduce part 0 merge Reduce part 1 sort Split n Map © 2011 MyDrive Solutions Limited 16
- 18. MapReduce can be good for: • “Embarrassingly Parallel” problems • Semi-structured or unstructured data • Index generation • Log analysis • Statistical analysis of patterns in data • Image processing • Generating map tiles • Data Mining • Much, much more © 2011 MyDrive Solutions Limited 17
- 19. MapReduce is not be good for: • Real-time or low-latency queries • Some graph algorithms • Algorithms that can’t be split into independent chunks • Some types of joins* • Not a replacement for RDBMS © 2011 MyDrive Solutions Limited 18
- 20. Writing MapReduce Programs • Java • Pipes (C++, sockets) • Streaming • Frameworks, e.g. wukong(ruby), dumbo(python) • JVM languages e.g. JRuby, Clojure, Scala • Cascading.org • Cascalog • Pig • Hive © 2011 MyDrive Solutions Limited 19
- 21. Streaming Example (ruby) • mapper.rb • reducer.rb © 2011 MyDrive Solutions Limited 20
- 22. Pig • High level language for writing data analysis programs • Runs MapReduce jobs • Joins, grouping, filtering, sorting, statistical functions • User-defined functions • Optional schemas • Sampling • Pig Latin similar to imperative language, define steps to run © 2011 MyDrive Solutions Limited 21
- 23. Pig Example © 2011 MyDrive Solutions Limited 22
- 24. Hive • Data warehousing and querying • HiveQL - SQL-like language for querying data • Runs MapReduce jobs • Joins, grouping, filtering, sorting, statistical functions • Partitioning of data • User-defined functions • Sampling • Declarative syntax © 2011 MyDrive Solutions Limited 23
- 25. Hive Example © 2011 MyDrive Solutions Limited 24
- 26. Getting Started • http://hadoop.apache.org • Cloudera Distribution (VM, source, rpm, deb) • Elastic MapReduce • Cloudera VM • Pseudo-distributed cluster © 2011 MyDrive Solutions Limited 25
- 27. Learn More • http://hadoop.apache.org • Books • Mailing Lists • Commercial Support & Training, e.g. Cloudera © 2011 MyDrive Solutions Limited 26
- 28. Related • Cassandra 0.6 has Hadoop integration - run MapReduce jobs against data in Cassandra • NoSQL DBs with MapReduce functionality include CouchDB, MongoDB, Riak and more • RDBMS with MapReduce include Aster, Greenplum, HadoopDB and more © 2011 MyDrive Solutions Limited 27
- 29. Gavin Heavyside [email protected] www.mydrivesolutions.com © 2011 MyDrive Solutions Limited 28
Editor's Notes
- #2: \n
- #3: \n
- #4: Andrei Alexandrescu - 1300ish photos/second at facebook\n
- #5: \n
- #6: \n
- #7: Use only subset/sample of data\nA server might have a MTBF of a few years\nWith thousands you can expect failures at least daily\nSystem needs to be handle HW failures\n
- #8: \n
- #9: Explain what we mean by commodity hardware \n8-core, 16-24GB ram, 4x1TB disks, gig ethernet\n\n
- #10: 95 Companies not exhaustive!\n
- #11: Zookeeper - distributed synchronisation service\nLocking, race conditions. Used for HBase distributed column-oriented database\nChukwa is large-scale log collection & analysis tools\nAvro - like protocol buffers - move towards default IPC mechanism in Hadoop\n
- #12: Mention secondary namenode\nNamenode is point of failure - not highly available\nMention lots of disks - JBOD: don&#x2019;t stripe, don&#x2019;t RAID\nRack-aware - splits will be processed local to the HDFS blocks where possible.\nPseudo distributed cluster can run all services on single machine\nDN/TT on lots of machines, NN, SNN, JT depend on cluster size.\n
- #13: Optimised for large (GB) files\n64MB block size not efficient for lots of small files -> concatenate them\n\n\n
- #14: \n
- #15: Text data\nBinary data (protocol buffers, avro)\nCustom input/output formats\n\n
- #16: \n
- #17: Compare with previous example, splits on each node, shuffle to reduce nodes\nTalk about partitioning\nReducers have to wait until the map and sort/shuffle has finished\nCombiners can run on Tasktracker\nCan be single Reducer or many\n\n
- #18: Mention Speculative Execution\nForward index: list of words per document\nInverted Index: list of documents containing word\nOnce you &#x201C;get&#x201D; it, you start to see how lots of problems can be parallelised\nMap Tiles at Google - Tech Talk on YouTube\n
- #19: Algorithm has a strict data dependency between iterations? Might not be efficient to parallelise with MapReduce\n
- #20: JVM languages can access the Hadoop Java classes\nStreaming works in any language that can read/write stdin/stdout\nCascalog brand new; only heard about it last night\n
- #21: Implements a map-side hash join\n
- #22: SAMPLE command samples random parts of data\nSPLIT\nAVG, COUNT, CONCAT, MIN, MAX, SUM\nCustom input/output formats\n
- #23: \n
- #24: Hive developed at Facebook, contributed back to community\nSQL is a declarative language, you specify an outcome, and the query planner generates a sequence of steps.\nAd-hoc queries using basic SQL\nCustom input/output formats\n
- #25: Create Table\nLoad Data\nSelect/Join/Group\n
- #26: \n
- #27: Cloudera do developer training and sysadmin training\nCloudera do commercial support\nOther providers on Hadoop homepage\n\n
- #28: Cassandra is an alternative to HBase - seems to have more momentum behind it.\nPlenty of hobbyist/small-scale MapReduce frameworks out there\n
- #29: \n