







![What
is
Spark?
Spark
is
a
general
purpose
computaLonal
framework
-‐
more
flexibility
than
MapReduce.
It
is
an
implementaLon
of
a
2010
Berkley
paper
[1].
Key
properBes:
• Leverages
distributed
memory
• Full
Directed
Graph
expressions
for
data
parallel
computaLons
• Improved
developer
experience
Yet
retains:
Linear
scalability,
Fault-‐tolerance
and
Data
Locality
based
computaLons
1
-‐
hUp://www.cs.berkeley.edu/~matei/papers/2010/hotcloud_spark.pdf
9](https://image.slidesharecdn.com/hadoopandspark-140415211944-phpapp01/85/Hadoop-and-Spark-9-320.jpg)












![Fault
Tolerance
• RDDs
contain
lineage.
• Lineage
–
source
locaLon
and
list
of
transformaLons
• Lost
parLLons
can
be
re-‐computed
from
source
data
msgs = textFile.filter(lambda s: s.startsWith(“ERROR”))
.map(lambda s: s.split(“t”)[2])
HDFS
File
Filtered
RDD
Mapped
RDD
filter
(func
=
startsWith(…))
map
(func
=
split(...))
22](https://image.slidesharecdn.com/hadoopandspark-140415211944-phpapp01/85/Hadoop-and-Spark-22-320.jpg)



![Easy:
Example
–
Word
Count
• Spark
public static class WordCountMapClass extends MapReduceBase
implements Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value,
OutputCollector<Text, IntWritable> output,
Reporter reporter) throws IOException {
String line = value.toString();
StringTokenizer itr = new StringTokenizer(line);
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
output.collect(word, one);
}
}
}
public static class WorkdCountReduce extends MapReduceBase
implements Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterator<IntWritable> values,
OutputCollector<Text, IntWritable> output,
Reporter reporter) throws IOException {
int sum = 0;
while (values.hasNext()) {
sum += values.next().get();
}
output.collect(key, new IntWritable(sum));
}
}
• Hadoop
MapReduce
val spark = new SparkContext(master, appName, [sparkHome], [jars])
val file = spark.textFile("hdfs://...")
val counts = file.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
counts.saveAsTextFile("hdfs://...")
26](https://image.slidesharecdn.com/hadoopandspark-140415211944-phpapp01/85/Hadoop-and-Spark-26-320.jpg)
![Easy:
Example
–
Word
Count
• Spark
public static class WordCountMapClass extends MapReduceBase
implements Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value,
OutputCollector<Text, IntWritable> output,
Reporter reporter) throws IOException {
String line = value.toString();
StringTokenizer itr = new StringTokenizer(line);
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
output.collect(word, one);
}
}
}
public static class WorkdCountReduce extends MapReduceBase
implements Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterator<IntWritable> values,
OutputCollector<Text, IntWritable> output,
Reporter reporter) throws IOException {
int sum = 0;
while (values.hasNext()) {
sum += values.next().get();
}
output.collect(key, new IntWritable(sum));
}
}
• Hadoop
MapReduce
val spark = new SparkContext(master, appName, [sparkHome], [jars])
val file = spark.textFile("hdfs://...")
val counts = file.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
counts.saveAsTextFile("hdfs://...")
27](https://image.slidesharecdn.com/hadoopandspark-140415211944-phpapp01/85/Hadoop-and-Spark-27-320.jpg)
![Spark
Word
Count
in
Java
JavaSparkContext sc = new JavaSparkContext(...);!
JavaRDD<String> lines = ctx.textFile("hdfs://...");!
JavaRDD<String> words = lines.flatMap(!
new FlatMapFunction<String, String>() {!
public Iterable<String> call(String s) {!
return Arrays.asList(s.split(" "));!
}!
}!
);!
!
JavaPairRDD<String, Integer> ones = words.map(!
new PairFunction<String, String, Integer>() {!
public Tuple2<String, Integer> call(String s) {!
return new Tuple2(s, 1);!
}!
}!
);!
!
JavaPairRDD<String, Integer> counts =
ones.reduceByKey(!
new Function2<Integer, Integer, Integer>() {!
public Integer call(Integer i1, Integer i2) {!
return i1 + i2;!
}!
}!
);!
JavaRDD<String> lines =
sc.textFile("hdfs://log.txt");!
!
JavaRDD<String> words =!
lines.flatMap(line ->
Arrays.asList(line.split(" ")));!
!
JavaPairRDD<String, Integer> ones
=!
words.mapToPair(w -> new
Tuple2<String, Integer>(w, 1));!
!
JavaPairRDD<String, Integer>
counts =!
ones.reduceByKey((x, y) -> x
+ y);!
Java
8
Lamba
Expression
[1]
1
-‐
hUp://docs.oracle.com/javase/tutorial/java/javaOO/lambdaexpressions.html
28](https://image.slidesharecdn.com/hadoopandspark-140415211944-phpapp01/85/Hadoop-and-Spark-28-320.jpg)





![Conviva
Use-‐Case
[1]
• Monitor
online
video
consumpLon
• Analyze
trends
Need
to
run
tens
of
queries
like
this
a
day:
SELECT videoName, COUNT(1)
FROM summaries
WHERE date='2011_12_12' AND customer='XYZ'
GROUP BY videoName;
1
-‐
hUp://www.conviva.com/using-‐spark-‐and-‐hive-‐to-‐process-‐bigdata-‐at-‐conviva/
34](https://image.slidesharecdn.com/hadoopandspark-140415211944-phpapp01/85/Hadoop-and-Spark-34-320.jpg)
![Conviva
With
Spark
val
sessions
=
sparkContext.sequenceFile[SessionSummary,NullWritable]
(pathToSessionSummaryOnHdfs)
val
cachedSessions
=
sessions.filter(whereCondiLonToFilterSessions).cache
val
mapFn
:
SessionSummary
=>
(String,
Long)
=
{
s
=>
(s.videoName,
1)
}
val
reduceFn
:
(Long,
Long)
=>
Long
=
{
(a,b)
=>
a+b
}
val
results
=
cachedSessions.map(mapFn).reduceByKey(reduceFn).collectAsMap
35](https://image.slidesharecdn.com/hadoopandspark-140415211944-phpapp01/85/Hadoop-and-Spark-35-320.jpg)














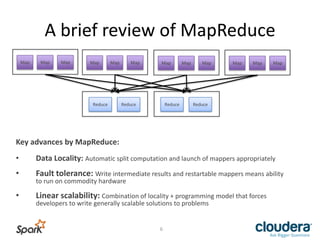
This document provides an overview and introduction to Spark, including: - Spark is a general purpose computational framework that provides more flexibility than MapReduce while retaining properties like scalability and fault tolerance. - Spark concepts include resilient distributed datasets (RDDs), transformations that create new RDDs lazily, and actions that run computations and return values to materialize RDDs. - Spark can run on standalone clusters or as part of Cloudera's Enterprise Data Hub, and examples of its use include machine learning, streaming, and SQL queries.























































































