Hadoop Architecture_Cluster_Cap_Plan
Download as PPTX, PDF0 likes284 views

Hadoop is an open-source framework that processes large datasets in a distributed manner across commodity hardware. It uses a distributed file system (HDFS) and MapReduce programming model to store and process data. Hadoop is highly scalable, fault-tolerant, and reliable. It can handle data volumes and variety including structured, semi-structured and unstructured data.












![Install High level basic steps
• 1) Install Linux OS (CentOS 6.X), user accounts enabled/created: root/welcome1, hdpadmin/welcome1
Hadoop Admin GROUPID and USERID minimum should be 2000
• 2) Ensure SSH, python2.6 package installed running if not then install using root access
• 3) Setup hostname(FQDN) maps to IP using hosts file
• 4) Setup hostname or update the hostname entry network file
• 5) Tune kernel params, Disable IPv6 & transparent memory pages
• 6) Disable selinux
• 7) Ensure iptables or firewall off for demo setup[Later you can enable and allow required ports and access]
• 8) Ensure DNS name resolution to IP Address and vice versa
• 9) Install NTP service and assign to the region of NTP server
• 10) Hard and Soft limits for files, umask
• 11) Reboot
• 12) Hadoop Admin account must be part of sudoers list
• 13) Enable password less authentication using ssh](https://image.slidesharecdn.com/hadoopclustercapplan-201208170825/85/Hadoop-Architecture_Cluster_Cap_Plan-14-320.jpg)
Hadoop Architecture_Cluster_Cap_Plan
- 1. Gartner says about the big data • Data Volume - Size in GB, TB, PB and ZB • Data Variety - Type & Structured/Unstructured • Data Velocity - Store & Retrieve speed • Data Complexity - How much complex is your data • Data used for Business Analytics (OLAP) • Open Source Big Data Framework(Hadoop derived from GFS) • Built using Sun/Oracle Java language • Distributed/Parallel computing platform • Effective of way Fail over handling • Commodity hardware support to handle big data • Simple programming model MapReduce (v1/v2) / Hadoop Streaming etc • Again with old approach - File System with Distributed Storage principle • Block Structured FS, Isolated Process • Batch Oriented Job execution
- 2. • What is the purpose of a Hadoop? Hadoop built using sun(oracle)java technology to process the big data which in terms of GB,TB, etc. size on commodity hardware • By considering the below resources for parallel process apache designed the system 1. CPU (Central Processing Unit) 2. RAM (Random Access Memory) 3. IO (Input & Output operations) 4. Network Bandwidth (Data transfer over network speed) Adv: Low Cost Ownership(LOC) Highly Scalable Distributed Storage and Process Platform Fast, Reliable Self Healing mechanism
- 3. Flat Files XML files RDBMS MultipleInputDataSources Big Data Architecture by Narayana Basetty Sqoop Flume, Kafka SCM App Fin App Bank App Many Apps J2EE UI Tableau QlikView SAP WebI Many UX Apps SparkMapReduce Python RDBMS
- 4. Data Process Layers Data Lake Discover, Prepare & Integrate Biz Data Final Reports Data Cold Data SQL (Sqoop) Data Discover and Stage Data(Hive) Final De- Norm/Report Data Stream Data Flow RDBMS Data Flow Hot Data (Flume/ Kafka) Data Discover and stage Data(Spark Stream) Final De- Norm/Report Data Flat/XML etc Flow Files Dump Discover and Files process(Hive External/Parser) Final De- Norm/Report Data
- 6. Hadoop Cluster Infra – Capacity Planning Sample UseCase Description Volume Calculation System Memory Daily Ingest Rate 500GB RAM Replication Factor 3 (copies of each hdfs block) Name Node 1 million blocks = 1GB NN Memory = TotalClusterStorage-MB/BlockSize-MB other process RAM Note: 150bytes per block, MapR no NN Daily Raw Data Volume as per replication 1.5 TB Ingest X Replication Data Node Memory Range IO bound : 2-4GB, CPU bound : 4-8GB Node Total Available Storage 20 TB 10 X 2 TB SSD (SATA II) OS System Reserved Space?? 10 GB Data Node IO Bound = 4GB * # of physical cores + 2G 4GB Node Manager + 4GB OS MapReduce Temp Storage 25% Stage area MapRed/Hive Jobs data Data Node CPU Bound = 8GB * # of physical cores + 2 + 4GB Node Manager + 4GB OS Node Raw Usable Storage 15TB Node Raw Storage – MapRed Reserve Resource Manager Memory = 4GB * # of physical cor Process + 4GB OS 1 Year(Flat Growth) 37 Nodes (Ingest X Replication X 365)/Node Raw Usable Storage
- 7. Hadoop Cluster Infra – Capacity Planning Sample UseCase Description High Availability RAM, Cores, Processors Name Node(s) 3 Compute Nodes, 3 Zoo Keeper 1 TB, 8, 8 Resource Manager Node(s) 3 Compute Nodes, 3 Zoo Keeper 20 GB, 8, 8 Data Node 100 Compute Nodes (100 * 10 slots * 2 TB) 62 GB(Depends on), 8, 8 Job History Server 2 Compute Nodes 2 TB, 8, 8 OS System Reserved Space 25 GB 50GB MapReduce Temp Storage 20% Stage area MapRed/Hive Jobs data Edge Nodes(User) 2 or 4 or 6 Compute Nodes(Depends on users) 64GB, Shared Disks, 8, 8 Ambari 1 Compute Node 15 GB , 8, 8 SQL server(My SQL) 3 (In Replication), 500GB disk 16 GB, 8,8
- 8. Rack-1 Rack-2 hddev-c01-r01-03(NN) hddev-c01-r02-08(NN) hddev-c01-r01-04(RM) hddev-c01-r02-09(RM) hddev-c01-r01-05(Hive, Storm) hddev-c01-r02-10(Hive, Storm) hddev-c01-r01-06(Kafka) hddev-c01-r02-11(Kafka) hddev-c01-r01-07(Hbase) hddev-c01-r02-12 Hadoop Cluster - ACL - Hadoop Admin Load Balancer hddev-c01-edge-01 hddev-c01-edge-02 Current Infra Proposed Infra 1. 4 CPU cores, 24 GB RAM 2. Edge - shared disks 3. Hadoop Disk - SSD 1. 8 CPU cores, 62 GB RAM 2. Edge - Shared disks 3. Hadoop Disk - SSD hd - Hadoop, dev - Development, c- compute node, r - rack
- 9. Proposed Hadoop Cluster infra • Ideally 3 Racks ( By considering Failover on rack nodes) • Master - 3 NN(R1,R2,R3), 3 RM(R1,R2,R3), 3 ZK(R1,R2,R3) • Slave(Worker) - Remaining Data Node • Necessary storage disks • Minimum - 8 cores(preferred), 42 GB RAM (Ex: 10 nodes , 80 cores, 420 GB) • Max - As needed • Hortonworks Ambari - chooses automatically services(NN, RM etc) to install on the nodes. If Admin wanted , that can be customized. • NN HA, RM HA, Hive HA, ZK HA NN - Name Node, RM - Resource Manger, R - Rack, ZK - ZooKeeper, HA - High Availability
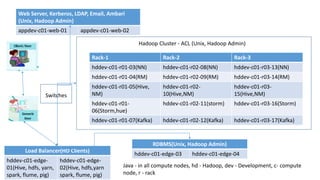
- 10. Hadoop Cluster - ACL (Unix, Hadoop Admin) Load Balancer(HD Clients) hddev-c01-edge- 01(Hive, hdfs, yarn, spark, flume, pig) hddev-c01-edge- 02(Hive, hdfs,yarn spark, flume, pig) Java - in all compute nodes, hd - Hadoop, dev - Development, c- compute node, r - rack Web Server, Kerberos, LDAP, Email, Ambari (Unix, Hadoop Admin) appdev-c01-web-01 appdev-c01-web-02 Rack-1 Rack-2 Rack-3 hddev-c01-r01-03(NN) hddev-c01-r02-08(NN) hddev-c01-r03-13(NN) hddev-c01-r01-04(RM) hddev-c01-r02-09(RM) hddev-c01-r03-14(RM) hddev-c01-r01-05(Hive, NM) hddev-c01-r02- 10(Hive,NM) hddev-c01-r03- 15(Hive,NM) hddev-c01-r01- 06(Storm,hue) hddev-c01-r02-11(storm) hddev-c01-r03-16(Storm) hddev-c01-r01-07(Kafka) hddev-c01-r02-12(Kafka) hddev-c01-r03-17(Kafka) Switches RDBMS(Unix, Hadoop Admin) hddev-c01-edge-03 hddev-c01-edge-04
- 11. Hadoop Basic components Service Type/Component Master/Slave Component Name HDP Cluster HDFS Master Name Node Yes HDFS Master Secondary NN(not required if NN HA sets up) Yes HDFS Slave Data Node Yes MapRed-2 Master History Server Yes YARN Master Resource Manager Yes YARN Slave Node Manager Yes Quorum Journals Master Journal Nodes(HA NN) Yes Co-Ordinator Master Zoo Keeper Yes HDFS/yarn Master Hive(rdbms) Edge Node Security Master Ranger(rdbms) Yes/Outside Security Master Knox Yes/Outside Security Master Kerberos Yes/Outside
- 12. Hadoop Good to Have Components Service Type/Component Master/Slave Component Name HDP Cluster Master Web Master Hue Yes Master Web Master Oozie Yes Spark Master S-Master Yes Spark Worker S-Worker Yes Spark Spark On Yarn Yes HDFS/standalone storage Master HMaster Yes HDFS/standalone storage Worker Region Server Yes Component Command-client Sqoop Edge Node Component Uses by Hive internal - Client Tez Edge Node Component Command-client Pig Edge Node
- 13. Hadoop Future Components Service Type/Component Master/Slave Component Name HDP Cluster Distributed Message Service Master Kafka Yes Stream service Master Flume Yes Stream service Master Flink Yes Stream service Master Storm Nimbus Yes Stream service Slave Storm Supervisor Yes Service Master Solr Yes Cluster Control Components Service Type/Component Master/Slave HDP Cluster Ambari Server Master(rdbms) No Ambari Agent Slave Yes RDBMS(mysql/postgresql etc) Master(Replication to be setup) No Ambari Metrics Master(rdbms) No
- 14. Install High level basic steps • 1) Install Linux OS (CentOS 6.X), user accounts enabled/created: root/welcome1, hdpadmin/welcome1 Hadoop Admin GROUPID and USERID minimum should be 2000 • 2) Ensure SSH, python2.6 package installed running if not then install using root access • 3) Setup hostname(FQDN) maps to IP using hosts file • 4) Setup hostname or update the hostname entry network file • 5) Tune kernel params, Disable IPv6 & transparent memory pages • 6) Disable selinux • 7) Ensure iptables or firewall off for demo setup[Later you can enable and allow required ports and access] • 8) Ensure DNS name resolution to IP Address and vice versa • 9) Install NTP service and assign to the region of NTP server • 10) Hard and Soft limits for files, umask • 11) Reboot • 12) Hadoop Admin account must be part of sudoers list • 13) Enable password less authentication using ssh