





























![Read JDK APIs carefully
•
What is the problem with this code?
File fileList[] = dir.listFiles();
For(File f : fileList) {
…
}](https://image.slidesharecdn.com/diskfailinplace-120223123812-phpapp02/85/Hadoop-Disk-Fail-In-Place-DFIP-32-320.jpg)



Hadoop - Disk Fail In Place (DFIP)
- 1. Hadoop Disk Fail Inplace Bharath Mundlapudi (Email: [email protected]) Core Hadoop Engineer
- 2. About Me! • Current Hadoop Engineering, Yahoo! - Performance, Utilization & HDFS core group. • Recent Past Javasoft & J2EE Group, Sun - JVM Performance, SIP container, XML & Web Services.
- 3. My contribution to Hadoop • Namenode memory improvements • Developed tools to understand cluster utilization and performance at scale. • Namenode & Job tracker - Garbage collector tunings. • Disk Fail Inplace
- 4. Agenda • Disk Fail Inplace • Methodology • Issues found • Operational Changes • Hadoop Changes • Lessons learned
- 5. Disk Failures Isn’t Hadoop already handling disk failures?
- 6. Where are we today? In Hadoop, If a single disk in a node fails, the entire node is blacklisted for the TaskTracker, and the DataNode process fails to startup.
- 7. Trends in commodity nodes • More Storage – 12 * 3TB • More Compute power – 24 core • RAM – 48GB
- 9. Impact of a single disk failure Old generation grids: New grids: (6 x 1.5TB drives, 12 slots) (12 x 3TB drives, 24 slots) 10PB, 3 replica grid = 10 PB, 3 replica grid = 3777 nodes 944 nodes Failure of one disk = Failure of one disk = Loss of 0.02% of grid storage Loss of 0.1% of grid storage, i.e. 5 times magnified loss of storage Failure of one disk = Failure of one disk = Loss of 0.02% of grid compute Loss of 0.1% of grid compute capacity capacity, i.e 5 times magnified loss of compute
- 10. Node Statistics Total Active Blackliste Excluded nodes d 30242 28436(94%) 65 (0.2%) 1741(6%) Breakout of blacklisted nodes in all grids Ethernet Link Failure Disk Failure 11 (16% of failures) 54 (83% of failures)
- 11. What is DFIP? • DFIP – Disk Fail Inplace • We want to run Hadoop even when disks fail until a threshold. • Primarily – DataNode and TaskTracker • We took a holistic approach to solve this disk failure problem.
- 12. Why now? • Trend in high density disks (36TB) – Cost of losing a node is high • To increase operational efficiency – Utilization – Scaling data – Various other benefits
- 13. Where to inject a failure? • Complete stack analysis for disk failures. DataNode TaskTracker JVM Linux SCSI Device Driver
- 15. Lab Setup • 40 node cluster on two racks • Kickstart and TFTP Server • Kerberos Server
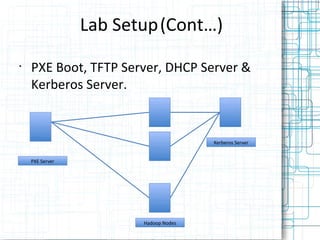
- 16. Lab Setup(Cont…) • PXE Boot, TFTP Server, DHCP Server & Kerberos Server. Kerberos Server PXE Server Hadoop Nodes
- 17. Operational Improvement • With DFIP, Completely changed Hadoop deployment layout. • Linux re-image time took 4 hours on a 12 disk system. Improvement: We reduced the re-image time to 20 minutes (12X better).
- 18. Hadoop Changes
- 19. Analysis Phase • Which files are used? – Use linux system commands to identify these. • Identified all the files used by datanode and tasktracker. Logs, tmp, conf, libraries(system), jars etc.
- 20. Methodology • Umount –l • Chmod 000, 400 etc • System Tap – Similar to Dtrace in solaris. – Probes the modules of interest. – Written probes for SCSI and CCISS modules.
- 21. Failure Framework • System Tap (stap) based framework • Requires root privileges • Time duration based injection • Developed for SCSI and CCISS drivers.
- 22. Hadoop Changes • Umbrella Jira – Hadoop Disk Fail Inplace HADOOP-7123 TaskTracker Datanode HADOOP-7124 HADOOP-7125
- 23. File Management • Separate out user and system files • RAID1 on system files • System files – Kernel files, Hadoop binaries, pids and logs & JDK • User files – HDFS data, Task logs and output & Distributed cache etc.
- 24. Datanode impact • Separation of system and user files • Datanode logs on RAID1 • DataNode doesn’t honor volumes tolerated. – Jira – HDFS-1592 • DataNode process doesn’t exit when disks fail – Jira – HDFS-1692
- 25. Datanode: HDFS-1592 • DataNode doesn’t honor volumes tolerated. – Startup failure.
- 26. Datanode: HDFS-1692 • DataNode process doesn’t exit when disks fail – Runtime issue (Secure Mode).
- 27. TaskTracker Impact • Separation of system and user files • Tasktracker logs on RAID1 • Tasktracker should handle disk failures at both startup and runtime. – Jira: MAPREDUCE-2413 • Distribute task userlogs on multiple disks. – Jira: MAPREDUCE-2415 ² Components impacted: - Linux task controller, Default task controller, Health check script, Security and most of the components in Tasktracker.
- 28. Tasktracker: MAPREDUCE-2413 • Tasktracker should handle disk failures at both startup and runtime. – Keep track of good disks all the time. – Pass the good disks to all the components like DefaultTaskController and LinuxTaskController. – Periodically check for disk failures – If disk failures happens, re-init the TaskTracker. – Modified Health Check Scripts.
- 29. TaskTracker: MAPREDUCE-2415 • Distribute task userlogs on multiple disks. – Single point of failure.
- 30. Rigorous Testing • Random writer benchmark (With failures) • Terasort benchmark (With failures) • Gridmixv3 benchmark (With failures) • Passed 950 QA tests • Tested with Valgrind for Memory leaks
- 32. Read JDK APIs carefully • What is the problem with this code? File fileList[] = dir.listFiles(); For(File f : fileList) { … }
- 33. Exception Handling • ServerSocket.accept() will throw AsynchronousCloseException
- 34. Future Work • Disk Hot Swap. • More kinds of failures – Timeouts, CRC errors, network, CPU, Memory etc • And more :-)
- 35. Thank you Contacts: Email: [email protected] Linkedin: http://www.linkedin.com/pub/bharath-mundlapudi/2/148/501