


















































Hadoop distributed file system (HDFS), HDFS concept
- 2. Data format, analyzing data with Hadoop, scaling out, Hadoop streaming, Hadoop pipes, design of Hadoop distributed file system (HDFS), HDFS concepts, Java interface, data flow, Hadoop I/O, data integrity, compression, serialization, Avro, file-based data structures, MapReduce workflows, unit tests with MRUnit, test data and local tests, anatomy of MapReduce job run, classic Map-reduce, YARN, failures in classic Map-reduce and YARN, job scheduling, shuffle andsort, task execution, MapReduce types, input formats, output formats Contents 2
- 3. Hadoop is an open-source software framework for storing and processing large datasets ranging in size from gigabytes to petabytes. Hadoop was developed at the Apache Software Foundation in 2005. It is written in Java. The traditional approach like RDBMS is not sufficient due to the heterogeneity of the data. Apache Hadoop 3
- 4. So Hadoop comes as the solution to the problem of big data i.e. storing and processing the big data with some extra capabilities. Its co-founder Doug Cutting named it on his son’s toy elephant. There are mainly two components of Hadoop which are : Hadoop Distributed File System (HDFS) Yet Another Resource Negotiator(YARN). Apache Hadoop 4
- 5. Hadoop is designed to scale up from a single server to thousands of machines, each offering local computation and storage. Applications built using HADOOP are run on large data sets distributed across clusters of commodity computers. Commodity computers are cheap and widely available, these are useful for achieving greater computational power at a low cost. In Hadoop data resides in a distributed file system which is called a Hadoop Distributed File system. Why Hadoop? 5
- 6. In Hadoop data resides in a distributed file system which is called a Hadoop Distributed File system. HDFS splits files into blocks and sends them across various nodes in form of large clusters. The Hadoop Distributed File System (HDFS) is based on the Google File System (GFS) and provides a distributed file system that is designed to run on commodity hardware. Commodity hardware is cheap and widely available, these are useful for achieving greater computational power at a low cost. HDFS 6
- 7. It is highly fault-tolerant and is designed to be deployed on low-cost hardware. It provides high throughput access to application data and is suitable for applications having large datasets. Hadoop framework includes the following two modules : Hadoop Common: These are Java libraries and utilities required by other Hadoop modules. Hadoop YARN: This is a framework for job scheduling and cluster resource management HDFS 7
- 9. Hadoop Core Components 9 Hadoop Distributed File System (HDFS): Data can be distributed over a cluster of computers Yet Another Resource Negotiator (YARN): This is a framework for job scheduling and cluster resource management. Hadoop MapReduce: This is YARN-based system for parallel processing of large data sets.
- 10. Ambari™: A web-based tool for provisioning, managing, and monitoring Apache Hadoop clusters which includes support for Hadoop HDFS, Hadoop MapReduce, Hive, HCatalog, HBase, ZooKeeper, Oozie, Pig and Sqoop. Avro™: A data serialization system. Cassandra™: A scalable multi-master database with no single points of failure. Chukwa™: A data collection system for managing large distributed systems. Flume™: A tool used to collect, aggregate and move huge amounts of streaming data into HDFS. Other Ecosystem Components/Projects 10
- 11. HBase™: A scalable, distributed database that supports structured data storage for large tables. Hive™: A data warehouse infrastructure that provides data summarization and ad hoc querying. Mahout™: A Scalable machine learning and data mining library. Oozie™: A server-based workflow scheduling system to manage Hadoop jobs; Pig™: A high-level data-flow language and execution framework for parallel computation. Other Ecosystem Components/Projects 11
- 12. Spark™: A fast and general compute engine for Hadoop data. Spark provides a simple and expressive programming model that supports a wide range of applications. Scoop™: A connectivity tool for moving data between relational databases and data warehouses and Hadoop. Tez™: A generalized data-flow programming framework, built on Hadoop YARN, which provides a powerful and flexible engine. ZooKeeper™: A high-performance coordination service for distributed applications. it is a highly available service used for the management of Hadoop operations, and many components of Hadoop depend on it. Other Ecosystem Components/Projects 12
- 13. A data/file format defines how information is stored in HDFS. Hadoop does not have a default file format and the choice of a format depends on its use. The big problem in the performance of applications that use HDFS is the information search time and the writing time. Managing the processing and storage of large volumes of information is very complex that’s why a certain data format is required. DATA FORMAT 13
- 14. The choice of an appropriate file format can produce the following benefits: Optimum writing time Optimum reading time File divisibility Adaptive scheme and compression support DATA FORMAT 14
- 15. Some of the most commonly used formats of the Hadoop ecosystem are : ● Text/CSV: A plain text file or CSV is the most common format both outside and within the Hadoop ecosystem. ● SequenceFile: The SequenceFile format stores the data in binary format, this format accepts compression but does not store metadata. DATA FORMAT 15
- 16. ● Avro: Avro is a row-based storage format. This format includes the definition of the scheme of your data in JSON format. Avro allows block compression along with its divisibility, making it a good choice for most cases when using Hadoop. ● Parquet: Parquet is a column-based binary storage format that can store nested data structures. This format is very efficient in terms of disk input/output operations when the necessary columns to be used are specified. DATA FORMAT 16
- 17. ● RCFile (Record Columnar File): RCFile is a columnar format that divides data into groups of rows, and inside it, data is stored in columns. ● ORC (Optimized Row Columnar): ORC is considered an evolution of the RCFile format and has all its benefits alongside some improvements such as better compression, allowing faster queries. DATA FORMAT 17
- 18. While the MapReduce programming model is at the heart of Hadoop, it is low-level and as such becomes an unproductive way for developers to write complex analysis jobs. To increase developer productivity, several higher-level languages and APIs have been created that abstract away the low-level details of the MapReduce programming model. There are several choices available for writing data analysis jobs. . Analysing Data with Hadoop : 18
- 19. The Hive and Pig projects are popular choices that provide SQL-like and procedural data flow-like languages, respectively. HBase is also a popular way to store and analyze data in HDFS. It is a column-oriented database, and unlike MapReduce, provides random read and write access to data with low latency. MapReduce jobs can read and write data in HBase’s table format, but data processing is often done via HBase’s own client API. . Analysing Data with Hadoop : 19
- 20. There are two commonly used types of data scaling : Up Out Scaling up, or vertical scaling : It involves obtaining a faster server with more powerful processors and more memory. This solution uses less network hardware, and consumes less power; but ultimately. For many platforms, it may only provide a short-term fix, especially if continued growth is expected. . Scaling In Vs Scaling Out : 20
- 21. Scaling out, or horizontal scaling : It involves adding servers for parallel computing. The scale-out technique is a long-term solution, as more and more servers may be added when needed. But going from one monolithic system to this type of cluster may be difficult, although extremely effective solution. . Scaling In Vs Scaling Out : 21
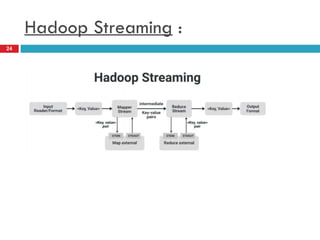
- 22. It is a feature that comes with a Hadoop distribution that allows developers or programmers to write the Map-Reduce program using different programming languages like Ruby, Perl, Python, C++, etc. We can use any language that can read from the standard input(STDIN) like keyboard input and all and write using standard output(STDOUT). Although Hadoop Framework is completely written in java programs for Hadoop do not necessarily need to code in Java programming language. . Hadoop Streaming : 22
- 23. The main advantage of the Hadoop streaming utility is that it allows Java as well as non-Java programmed MapReduce jobs to be executed over Hadoop clusters. The Hadoop streaming supports the Perl, Python, PHP, R, and C++ Translate the application logic into the Mapper and Reducer sections with the key and value output elements. Three main components: Mapper, Reducer, and Driver. Hadoop Streaming : 23
- 25. We have an Input Reader which is responsible for reading the input data and produces the list of key-value pairs. We can read data in .csv format, in delimiter format, from a database table, image data(.jpg, .png), audio data etc. This list of key-value pairs is fed to the Map phase and Mapper will work on each of these key-value pair of each pixel and generate some intermediate key-value pairs. After shuffling and sorting, the intermediate key-value pairs are fed to the Reducer: then the final output produced by the reducer will be written to the HDFS. These are how a simple Map-Reduce job works. Hadoop Streaming : 25
- 27. Hadoop Pipes is the name of the C++ interface to Hadoop MapReduce. Unlike Streaming, this uses standard input and output to communicate with the map and reduce code. Pipes uses sockets as the channel over which the task tracker communicates with the process running the C++ map or reduce function. Hadoop Pipes : 27
- 28. HDFS is a filesystem designed for storing very large files with streaming data access patterns, running on clusters of commodity hardware. Very large files: “Very large” in this context means files that are hundreds of megabytes, gigabytes, or terabytes in size. There are Hadoop clusters running today that store petabytes of data. Streaming data access : HDFS is built around the idea that the most efficient data processing pattern is a write-once, read-many-times pattern. A dataset is typically generated or copied from source, then various analyses are performed on that dataset over time. Design of HDFS : 28
- 29. Commodity hardware : Hadoop doesn’t require expensive, highly reliable hardware to run on. It’s designed to run on clusters of commodity hardware (commonly available hardware available from multiple vendors3) for whichthe chance of node failure across the cluster is high, at least for large clusters. HDFS is designed to carry on working without a noticeable interruption to the user in the face of such failure. Design of HDFS : 29
- 30. Features of HDFS : It is suitable for the distributed storage and processing. Hadoop provides a command interface to interact with HDFS. The built-in servers of namenode and datanode help users to easily check the status of cluster. Streaming access to file system data. HDFS provides file permissions and authentication. Design of HDFS : 30
- 31. Architecture of HDFS : 31
- 32. Namenode The namenode is the commodity hardware that contains the GNU/Linux operating system and the namenode software. It is a software that can be run on commodity hardware. The system having the namenode acts as the master server and it does the following tasks − Manages the file system namespace. Regulates client’s access to files. It also executes file system operations such as renaming, closing, and opening files and directories. Contd.. 32
- 33. Datanode The datanode is a commodity hardware having the GNU/Linux operating system and datanode software. For every node (Commodity hardware/System) in a cluster, there will be a datanode. These nodes manage the data storage of their system. Datanodes perform read-write operations on the file systems, as per client request. They also perform operations such as block creation, deletion, and replication according to the instructions of the namenode. Contd.. 33
- 34. Block Generally the user data is stored in the files of HDFS. The file in a file system will be divided into one or more segments and/or stored in individual data nodes. These file segments are called as blocks. In other words, the minimum amount of data that HDFS can read or write is called a Block. The default block size is 64MB, but it can be increased as per the need to change in HDFS configuration. Contd.. 34
- 35. Goals of HDFS Fault detection and recovery Since HDFS includes a large − number of commodity hardware, failure of components is frequent. Therefore HDFS should have mechanisms for quick and automatic fault detection and recovery. Huge datasets HDFS should have hundreds of nodes per cluster − to manage the applications having huge datasets. Hardware at data A requested task can be done efficiently, when the − computation takes place near the data. Especially where huge datasets are involved, it reduces the network traffic and increases the throughput. Contd.. 35
- 36. Advantages of HDFS: It is inexpensive, immutable in nature, stores data reliably, ability to tolerate faults, scalable, block structured, can process a large amount of data simultaneously and many more. Disadvantages of HDFS: It’s the biggest disadvantage is that it is not fit for small quantities of data. Also, it has issues related to potential stability, restrictive and rough in nature. Hadoop also supports a wide range of software packages such as Apache Flumes, Apache Oozie, Apache HBase, Apache Sqoop, Apache Spark, Apache Storm, Apache Pig, Apache Hive, Apache Phoenix, Cloudera Impala. Contd.. 36
- 37. The first way is to back up the files that make up the persistent state of the filesystem metadata. Hadoop can be configured so that the namenode writes its persistent state to multiple filesystems. These writes are synchronous and atomic. The usual configuration choice is to write to local disk as well as a remote NFS mount. Second Way:It is also possible to run a secondary namenode, which despite its name does not act as a namenode. Its main role is to periodically merge the namespace image with the edit log to prevent the edit log from becoming too large. But this can shaped to act as primary namenode What precautions HDFS is taking to recover file system in case of namenode failure: 37
- 38. Hadoop comes with a set of primitives for data I/O. Some of these are techniques that are more general than Hadoop, such as data integrity and compression, but deserve special consideration when dealing with multiterabyte datasets. Others are Hadoop tools or APIs that form the building blocks for developing distributed systems, such as serialization frameworks and on-disk data structures Hadoop I/O 38
- 39. Users of Hadoop rightly expect that no data will be lost or corrupted during storage or processing. However, since every I/O operation on the disk or network carries with it a small chance of introducing errors into the data that it is reading or writing, when the volumes of data flowing through the system are as large as the ones Hadoop is capable of handling, the chance of data corruption occurring is high. The usual way of detecting corrupted data is by computing a checksum for the data when it first enters the system, and again whenever it is transmitted across a channel that is unreliable and hence capable of corrupting the data. The data is deemed to be corrupt if the newly generated checksum doesn’t exactly match the original. Data Integrity 39
- 40. This technique doesn’t offer any way to fix the data—merely error detection. (And this is a reason for not using low-end hardware; in particular, be sure to use ECC memory.) Note that it is possible that it’s the checksum that is corrupt, not the data, but this is very unlikely, since the checksum is much smaller than the data. HDFS transparently checksums all data written to it and by default verifies checksums when reading data. A separate checksum is created for every io.bytes.per.checksum bytes of data. The default is 512 bytes, and since a CRC-32 checksum is 4 bytes long, the storage overhead is less than 1%. Data Integrity in HDFS 40
- 41. Datanodes are responsible for verifying the data they receive before storing the data and its checksum. This applies to data that they receive from clients and from other datanodes during replication. If it detects an error, the client receives a ChecksumException, a subclass of IOException. When clients read data from datanodes, they verify checksums as well, comparing them with the ones stored at the datanode. When a client successfully verifies a block, it tells the datanode, which updates its log. Keeping statistics such as these is valuable in detecting bad disks. Aside from block verification on client reads, each datanode runs a DataBlockScanner in a background thread that periodically verifies all the blocks stored on the datanode. This is to guard against corruption due to “bit rot” intoe physicalstorage media. Data Integrity in HDFS 41
- 42. Apache Avro is a language-neutral data serialization system. Since Hadoop writable classes lack language portability, Avro becomes quite helpful, as it deals with data formats that can be processed by multiple languages. Avro is a preferred tool to serialize data in Hadoop. Avro has a schema-based system. A language-independent schema is associated with its read and write operations. Avro serializes the data which has a built-in schema. Avro serializes the data into a compact binary format, which can be deserialized by any application. Avro uses JSON format to declare the data structures. Presently, it supports languages such as Java, C, C++, C#, Python, and Ruby. Avro 42
- 43. Mainly, Avro heavily depends on its schema. Basically, it permits every data to be written with no prior knowledge of the schema. We can say Avro serializes fast and the data resulting after serialization is least in size with schemas. Avro Schema 43
- 44. Avro is a language-neutral data serialization system. It can be processed by many languages (currently C, C++, C#, Java, Python, and Ruby). Avro creates binary structured format that is both compressible and splittable. Hence it can be efficiently used as the input to Hadoop MapReduce jobs. Avro provides rich data structures. For example, you can create a record that contains an array, an enumerated type, and a sub record. These datatypes can be created in any language, can be processed in Hadoop, and the results can be fed to a third language. Avro schemas defined in JSON, facilitate implementation in the languages that already have JSON libraries. Avro creates a self-describing file named Avro Data File, in which it stores data along with its schema in the metadata section. Avro is also used in Remote Procedure Calls (RPCs). During RPC, client and server exchange schemas in the connection handshake. Avro Features 44
- 45. Mainly, for two purposes, we use Avro, like: Data serialization RPC (Remote procedure call) protocol Although, some key points are: We are able to read the data from disk with applications, by using Avro even which are written in other languages besides java or the JVM. Also, Avro allows us to transfer data across a remote system without any overhead of java serialization. We use Avro when we need to store the large set of data on disk, as it conserves space. Further, by using Avro for RPC, we get a better remote data transfer. Why Avro? 45
- 46. Step 1 Create schemas. Here you need to design Avro schema − according to your data. Step 2 Read the schemas into your program. It is done in two ways − − By Generating a Class Corresponding to Schema Compile the schema − using Avro. This generates a class file corresponding to the schema By Using Parsers Library You can directly read the schema using parsers − library. Step 3 Serialize the data using the serialization API provided for Avro, − which is found in the package org.apache.avro.specific. Step 4 Deserialize the data using deserialization API provided for Avro, − which is found in the package org.apache.avro.specific. Working of Avro
- 47. Writing a program in MapReduce follows a certain pattern. You start by writing your map and reduce functions, ideally with unit tests to make sure they do what you expect. Then you write a driver program to run a job, which can run from your IDE using a small subset of the data to check that it is working. If it fails, you can use your IDE’s debugger to find the source of the problem. When the program runs as expected against the small dataset, you are ready to unleash it on a cluster. Running against the full dataset is likely to expose some more issues, which you can fix by expanding your tests and altering your mapper or reducer to handle the new cases. Developing A Map-Reduce Application :
- 48. After the program is working, you may wish to do some tuning : First by running through some standard checks for making MapReduce programs faster Second by doing task profiling. Profiling distributed programs are not easy, but Hadoop has hooks to aid in the process. Before we start writing a MapReduce program, we need to set up and configure the development environment. Components in Hadoop are configured using Hadoop’s own configuration API. Developing A Map-Reduce Application :
- 49. An instance of the Configuration class represents a collection of configuration properties and their values. Each property is named by a String, and the type of a value may be one of several, including Java primitives such as boolean, int, long, and float and other useful types such as String, Class, and java.io.File; and collections of Strings. Developing A Map-Reduce Application :
- 50. Hadoop MapReduce jobs have a unique code architecture that follows a specific template with specific constructs. This architecture raises interesting issues when doing test-driven development (TDD) and writing unit tests. With MRUnit, you can craft test input, push it through your mapper and/or reducer, and verify its output all in a JUnit test. As do other JUnit tests, this allows you to debug your code using the JUnit test as a driver. A map/reduce pair can be tested using MRUnit’s MapReduceDriver. , a combiner can be tested using MapReduceDriver as well. A PipelineMapReduceDriver allows you to test a workflow of map/reduce jobs. Unit Tests With MR Unit :
- 51. Currently, partitioners do not have a test driver under MRUnit. MRUnit allows you to do TDD(Test Driven Development) and write lightweight unit tests which accommodate Hadoop’s specific architecture and constructs. Example: We’re processing road surface data used to create maps. The input contains both linear surfaces and intersections. The mapper takes a collection of these mixed surfaces as input, discards anything that isn’t a linear road surface, i.e., intersections, and then processes each road surface and writes it out to HDFS. We can keep count and eventually print out how many non-road surfaces are input. For debugging purposes, we can additionally print out how many road surfaces were processed. Unit Tests With MR Unit :
- 52. THANK YOU.