Hadoop Migration from 0.20.2 to 2.0
Download as PPTX, PDF•0 likes•965 views

Hadoop was upgraded from version 0.20.2 to 2.0 across 5 production clusters storing over 1 petabyte of data and processing billions of events daily. Key challenges included managing configurations across heterogeneous clusters, allowing data movement between clusters on different versions, ensuring application compatibility, addressing capacity limitations, and performing the upgrade with minimal downtime. Extensive testing, parallel component upgrades, and rolling restarts were used to successfully complete the upgrade while maintaining over 99% uptime and without any failures.



















Hadoop Migration from 0.20.2 to 2.0
- 1. Hadoop 0.20.2 to 2.0 Jabir Ahmed https://twitter.com/jabirahmed https://www.linkedin.com/in/jabirahmed
- 2. • New Features • HA Namenode • YARN • Bug fixes & performance improvements • keeping pace with the community and to be ready to adapt technologies that are being built rapidly over Hadoop Why Hadoop 2.0 ?
- 3. Analytics Reporting Data Streaming via HDFS Adhoc Querying /Modeling Real time data processing Hadoop Usage @ inmobi
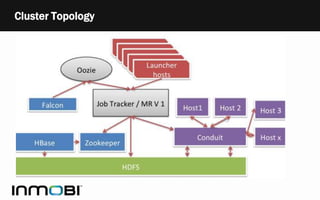
- 4. • HDFS & MRV1 • Falcon ‣ Active MQ • HBase • Conduit ‣ Scribe ‣ Conduit Worker ‣ Pintail Hadoop Eco System • Zoo-keeper • Oozie • WebHDFS • Pig • Hive • Hcatalog & Metastore
- 6. • 5 Production Quality Clusters spread across 5 co-locations • 30 to 150 Node clusters • Largest is over 1 Peta Byte • Average 500TB • 2,00,000+ Jobs Per day • 6TB of data generated every day • 10,000,000,000 Events Generated a day (10 Billion) Clusters In Inmobi
- 7. Cluster topology Centralized Cluster Co-located Clusters Co-located Clusters
- 8. Upgraded Components Component Old version New version Other Changes HDFS 0.20.2 2.0 Job-tracker 0.20.2 2.0 Oozie 3.3.2 3.3.2 Recompiled Hbase 0.90.6 0.94.6 Webhdfs -NA- 0.0.3 Re-Compiled internally Falcon 0.2.3 0.4.5 Pig 0.8.1 0.11.0 Zookeeper 3.3.4 3.4.5 Conduit Recompiled
- 9. 1. Configuration management 1. Heterogeneous clusters 2. Host Level Configurations were really hard to manage 2. Data movement had to continue between clusters which could/would run different version of Hadoop 3. All applications had to be seamlessly migrated with least downtime & NO failures 4. Capacity Challenges 1. Network Challenges 2. Hardware Limitations 3. Storage & Computation limitations 5. Expected uptime for each of the clusters in over 99%, which meant we couldn’t keep the cluster down for upgrade for a long time 6. Roll back was not possible Challenges
- 10. How we over came the challenges
- 11. 1. Configuration Management Problem ‣ We had configurations in debians like ‣ Cluster_Conf_version_1.deb ‣ Cluster_conf_version_2.deb and so on ‣ For 5 cluster and 10 components we would manage a lot of debs each with 15-20 Confs ‣ Changing a property value across the cluster was time consuming Packages & configurations ‣ Since host specific Configurations were really hard to manage we deprecated debians ‣ Moved entire Package & configuration to puppet Advantages ‣ Under 10 files to manage ‣ Everything was managed via templates and only host/component/cluster specific variables had to be set appropritely ‣ Verification & confidence was higher with puppet while deploying changes in production
- 12. 1.1 Sample puppet configuration Template <% mapred_queues.each_pair do |key,value| -%> <!-- setting for queue <%= key %> --> <property> <name>mapred.capacity- scheduler.queue.<%= key %>.capacity</name> <value><%= value %></value> </property> <% end -%> Actual values $mapred_queues={ ”reporting" => 25, ”analytics" => 12, ”default" => 21, ”Hourly" => 14, ”daily" => 13, ....... } Apply template file { "${conf_location}/capacity- scheduler.xml": ensure => present, owner => root, group => root, mode => 644, content => template('grid/hadoop2.0/hadoopC oreConfig/capacity-scheduler.xml');
- 13. 2. Data Movement All applications had to change to pull the data from other clusters distcp across clusters was not possible with the standard hdfs & hftp protocols We had to use Web-HDFS • Code was patched to allow only reads All applications & Falcon feeds/data replications had to be tested & migrated to web-hdfs. Since web-hdfs was a SPOF, it had to be made scalable & high available All clients reading from HDFS had to also upgrade libraries • Ensured all stacks were compatible to read from upgraded HDFS • Some applications like falcon & conduit had to be enhanced to use the webhdfs protocol as a pre-requisite.
- 14. 3. Application Challenges • 2 Versions of applications had to be maintained ‣ One for 0.20 and the other for 2.0 ‣ To avoid disruption in current business & respective development • Staging cluster had to be rebuilt to run 2 version of Hadoop for pre prod testing,validation and sign off • A lot of applications had to be made compatible since some functions & classes were deprecated in 2.0 • Few class path changes were identified in pre-prod testing
- 15. Capacity was a limitation since our headroom in other co-locations was only 30% but we were flipping 100% from one region to another • Network & Infra challenge ‣ N/W bandwidth for latency to avoid delays in data movement. ‣ Other stacks also had to check for capacity while we did a failover for the upgrade • Ensuring we have enough capacity in other cluster to process data while meeting SLA’s ‣ Added physical nodes to existing clusters & dependent stacks if it was required. ‣ Added more conduit/scribe agents to handle the increase in traffic during upgrade. 4. Capacity Challenges
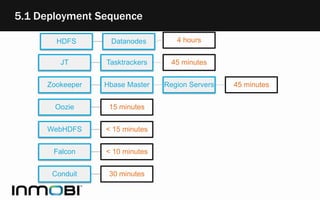
- 16. 5. Deployment & Upgrade • Rolling upgrade of clusters • The GSLB was changed to redirect traffic to closest region • Had to latencies were met as per the business requirement • Maintenance was scheduled at a time when the impact was least. • The time chosen was when the # of requests were the least for the specific region to ensure we don’t impact the performance and also don’t require 100% capacity in the failed over region • Data was processed on another cluster to have business continuity. • Since datanode upgrade depends on the number of blocks on the datanode we cleaned up HDFS to reduce the blocks on the datanodes which eventually helped in expediting the upgrade process • Upgrading components in parallel where there was no dependency
- 17. 5.1 Deployment Sequence HDFS Datanodes 4 hours JT Tasktrackers 45 minutes Zookeeper Hbase Master Region Servers 45 minutes Oozie 15 minutes WebHDFS < 15 minutes Falcon < 10 minutes Conduit 30 minutes
- 18. Most of the nagios checks and metrics collected in ganglia remained the same New Monitoring • Monitoring for new services like web-hdfs had to be added. Monitoring changes • Nagios had minor changes to monitor the edits since the edits had changed from ‣ edits & edits.new to ‣ edits_0000000000357071448- 0000000000357619117 edits_inprogress_000000000035873924 1 Ganglia Metrics • Ganglia was over whelmed with the new RS metric so we had to patch it to skip sending some metric that wasn’t required. ‣ Custom filter was written to filter events that were not used 6. Monitoring & Metrics
- 19. • The job tracker had a memory leak and had to be restarted once every 3-4 days • https://issues.apache.org/jira/browse/MAPREDUCE-5508 • Hbase started emitting 1000’s of metrics per table brining ganglia down & we had to patch it internally to fix it Issues / Bugs encountered
- 20. • One step at a time • We didn’t want to do a lot of things at one go, so we took small steps and at the end achieved the goal • Team work, Works! • Its really hard to do this as a “One Man Show”, we noticed immense sense of trust and responsibility among the team during the entire process • Every Mistake was a learning • Every mistake that was done in the initial stages was not a reason to blame each other but we went ahead and fixed it ensuring it didn’t happen again • Finally • There were smooth upgrades ! Learning & Best Practices
Editor's Notes
- #3: We broke the upgrade in 2 phases 1. HDFS upgrade & HA 2. YARN
- #10: ----- Meeting Notes (06/05/14 00:08) -----every procument had some slight variations in terms of specs some had more ram some had 6 disk and some 12 disks CPU cores were differentRoll back was not possibleFailures in production strict No noQA test cases were re verified
- #12: Hardware specs kept changing with every new procurementSome had more ram , some had more disks etc.Since we grew significantly in terms of number of servers , debians were a tech debt and we took this as an opportunity to fix it----- Meeting Notes (06/05/14 00:23) -----verification of configs post installation was simpler
- #13: We built a separate module for the configuration that could be used across all clusters going forwardAll the properties were verified, deprecated properties were retained along with the new properties to avoid any failures , just in case they were being used anywhereThis significantly reduced the time we took post installation to validate if the configurations were correct since it was all centralized
- #15: 5-10 Pipelines each with multiple jobs QA effortTest casesData validationEvery bug had to be fixed & merged in two placesDeployment Challenges