












![14
Map-Reduce Execution Engine
(Example: Color Count)
Shuffle & Sorting
based on k
Input blocks
on HDFS
Produces (k, v)
( , 1)
Consumes(k, [v])
( , [1,1,1,1,1,1..])
Produces(k’, v’)
( , 100)
Users only provide the “Map” and “Reduce” functions](https://image.slidesharecdn.com/hadoop-part1-250304095226-ec1444a7/85/Hadoop-part1-in-cloud-computing-subject-pptx-14-320.jpg)





![20
Example 2: Color Count
Shuffle & Sorting
based on k
Input blocks
on HDFS
Produces (k, v)
( , 1)
Consumes(k, [v])
( , [1,1,1,1,1,1..])
Produces(k’, v’)
( , 100)
Job: Count the number of each color in a data set
Part0003
Part0002
Part0001
That’s the output file, it has
3 parts on probably 3
different machines](https://image.slidesharecdn.com/hadoop-part1-250304095226-ec1444a7/85/Hadoop-part1-in-cloud-computing-subject-pptx-20-320.jpg)





![26
Optimization 1: Takes Place inside
Mappers
Shuffle & Sorting
based on k
Input blocks
on HDFS
Produces (k, v)
( , 100)
Consumes(k, [v])
( , [1,1,1,1,1,1..])
Produces(k’, v’)
( , 100)
Saves network messages (Typically very expensive phase)
Part0003
Part0002
Part0001
That’s the output file, it has
3 parts on probably 3
different machines](https://image.slidesharecdn.com/hadoop-part1-250304095226-ec1444a7/85/Hadoop-part1-in-cloud-computing-subject-pptx-26-320.jpg)


![29
Optimization 2: Outside Mappers, But on
Each Machine
Shuffle & Sorting
based on k
Input blocks
on HDFS
Produces (k, v)
( , 1)
Consumes(k, [v])
( , [1,1,1,1,1,1..])
Produces(k’, v’)
( , 100)
Combiner runs on each node to partially aggregate the local mappers’ output
Part0003
Part0002
Part0001
That’s the output file, it has
3 parts on probably 3
different machines](https://image.slidesharecdn.com/hadoop-part1-250304095226-ec1444a7/85/Hadoop-part1-in-cloud-computing-subject-pptx-29-320.jpg)









![39
Reminder about Covered Phases
Shuffle & Sorting
based on k
Input blocks
on HDFS
Produces (k, v)
( , 1)
Consumes(k, [v])
( , [1,1,1,1,1,1..])
Produces(k’, v’)
( , 100)
Job: Count the number of each color in a data set
Part0003
Part0002
Part0001
That’s the output file, it has
3 parts on probably 3
different machines](https://image.slidesharecdn.com/hadoop-part1-250304095226-ec1444a7/85/Hadoop-part1-in-cloud-computing-subject-pptx-39-320.jpg)
















Hadoop-part1 in cloud computing subject.pptx
- 2. 2 Large-Scale Data Analytics • MapReduce computing paradigm (E.g., Hadoop) vs. Traditional database systems Database vs. Many enterprises are turning to Hadoop Especially applications generating big data Web applications, social networks, scientific applications
- 3. 3 Why Hadoop is able to compete? Scalability (petabytes of data, thousands of machines) Database vs. Flexibility in accepting all data formats (no schema) Commodity inexpensive hardware Efficient and simple fault- tolerant mechanism Performance (tons of indexing, tuning, data organization tech.) Features: - Provenance tracking - Annotation management - ….
- 4. 4 What is Hadoop • Hadoop is a software framework for distributed processing of large datasets across large clusters of computers • Large datasets Terabytes or petabytes of data • Large clusters hundreds or thousands of nodes • Hadoop is open-source implementation for Google MapReduce • Hadoop is based on a simple programming model called MapReduce • Hadoop is based on a simple data model, any data will fit
- 5. 5 What is Hadoop (Cont’d) • Hadoop framework consists on two main layers • Distributed file system (HDFS) • Execution engine (MapReduce)
- 6. 6 Hadoop Master/Slave Architecture • Hadoop is designed as a master-slave shared-nothing architecture Master node (single node) Many slave nodes
- 7. 7 Design Principles of Hadoop • Need to process big data • Need to parallelize computation across thousands of nodes • Commodity hardware • Large number of low-end cheap machines working in parallel to solve a computing problem • This is in contrast to Parallel DBs • Small number of high-end expensive machines
- 8. 8 Design Principles of Hadoop • Automatic parallelization & distribution • Hidden from the end-user • Fault tolerance and automatic recovery • Nodes/tasks will fail and will recover automatically • Clean and simple programming abstraction • Users only provide two functions “map” and “reduce”
- 9. 9 Who Uses MapReduce/Hadoop • Google: Inventors of MapReduce computing paradigm • Yahoo: Developing Hadoop open-source of MapReduce • IBM, Microsoft, Oracle • Facebook, Amazon, AOL, NetFlix • Many others + universities and research labs
- 10. 10 Hadoop: How it Works
- 11. 11 Hadoop Architecture Master node (single node) Many slave nodes • Distributed file system (HDFS) • Execution engine (MapReduce)
- 12. 12 Hadoop Distributed File System (HDFS) Centralized namenode - Maintains metadata info about files Many datanode (1000s) - Store the actual data - Files are divided into blocks - Each block is replicated N times (Default = 3) File F 1 2 3 4 5 Blocks (64 MB)
- 13. 13 Main Properties of HDFS • Large: A HDFS instance may consist of thousands of server machines, each storing part of the file system’s data • Replication: Each data block is replicated many times (default is 3) • Failure: Failure is the norm rather than exception • Fault Tolerance: Detection of faults and quick, automatic recovery from them is a core architectural goal of HDFS • Namenode is consistently checking Datanodes
- 14. 14 Map-Reduce Execution Engine (Example: Color Count) Shuffle & Sorting based on k Input blocks on HDFS Produces (k, v) ( , 1) Consumes(k, [v]) ( , [1,1,1,1,1,1..]) Produces(k’, v’) ( , 100) Users only provide the “Map” and “Reduce” functions
- 15. 15 Properties of MapReduce Engine • Job Tracker is the master node (runs with the namenode) • Receives the user’s job • Decides on how many tasks will run (number of mappers) • Decides on where to run each mapper (concept of locality) • This file has 5 Blocks run 5 map tasks • Where to run the task reading block “1” • Try to run it on Node 1 or Node 3 Node 1 Node 2 Node 3
- 16. 16 Properties of MapReduce Engine (Cont’d) • Task Tracker is the slave node (runs on each datanode) • Receives the task from Job Tracker • Runs the task until completion (either map or reduce task) • Always in communication with the Job Tracker reporting progress In this example, 1 map-reduce job consists of 4 map tasks and 3 reduce tasks
- 17. 17 Key-Value Pairs • Mappers and Reducers are users’ code (provided functions) • Just need to obey the Key-Value pairs interface • Mappers: • Consume <key, value> pairs • Produce <key, value> pairs • Reducers: • Consume <key, <list of values>> • Produce <key, value> • Shuffling and Sorting: • Hidden phase between mappers and reducers • Groups all similar keys from all mappers, sorts and passes them to a certain reducer in the form of <key, <list of values>>
- 18. 18 MapReduce Phases Deciding on what will be the key and what will be the value developer’s responsibility
- 19. 19 Example 1: Word Count Map Tasks Reduce Tasks • Job: Count the occurrences of each word in a data set
- 20. 20 Example 2: Color Count Shuffle & Sorting based on k Input blocks on HDFS Produces (k, v) ( , 1) Consumes(k, [v]) ( , [1,1,1,1,1,1..]) Produces(k’, v’) ( , 100) Job: Count the number of each color in a data set Part0003 Part0002 Part0001 That’s the output file, it has 3 parts on probably 3 different machines
- 21. 21 Example 3: Color Filter Job: Select only the blue and the green colors Input blocks on HDFS Produces (k, v) ( , 1) Write to HDFS Write to HDFS Write to HDFS Write to HDFS • Each map task will select only the blue or green colors • No need for reduce phase Part0001 Part0002 Part0003 Part0004 That’s the output file, it has 4 parts on probably 4 different machines
- 22. 22 MapReduce Phases Deciding on what will be the key and what will be the value developer’s responsibility
- 23. 23 Processing Granularity • Mappers • Run on a record-by-record bases • Your code processes that record and may produce • Zero, one, or many outputs • Reducers • Run on a group-of-records bases (having same key) • Your code processes that group and may produce • Zero, one, or many outputs
- 24. How it looks like in Java Map function Reduce function Provide implementation for Hadoop’s Mapper abstract class Provide implementation for Hadoop’s Reducer abstract class Job configuration
- 25. 25 Optimization 1 • In Color Count example, assume I know that the number of colors is small can we optimize the map-side • Each map function can have a small main-memory hash table (color, count) • With each line, update the hash table and produce nothing • When done, report each color and its local count 10 5 7 20 Gain: Reduce the amount of shuffled/sorted data over the network Q1: Where to build the hash table? Q2: How to know when done?
- 26. 26 Optimization 1: Takes Place inside Mappers Shuffle & Sorting based on k Input blocks on HDFS Produces (k, v) ( , 100) Consumes(k, [v]) ( , [1,1,1,1,1,1..]) Produces(k’, v’) ( , 100) Saves network messages (Typically very expensive phase) Part0003 Part0002 Part0001 That’s the output file, it has 3 parts on probably 3 different machines
- 27. 27 Inside the Mapper Class Called for each record Called once after all records (Here you can produce the output) Called once before any record (Here you can build the hash table) Reducer has similar functions…
- 28. 28 Optimization 2: Map-Combine- Reduce • What about partially aggregating the results from mappers on each machine Mappers 1…3 Mappers 4…6 Mappers 7…9 • A combiner is a reducer that runs on each machine to partially aggregate (that’s a user code) mappers’ outputs from this machine • Then, combiners output is shuffled/sorted for reducers
- 29. 29 Optimization 2: Outside Mappers, But on Each Machine Shuffle & Sorting based on k Input blocks on HDFS Produces (k, v) ( , 1) Consumes(k, [v]) ( , [1,1,1,1,1,1..]) Produces(k’, v’) ( , 100) Combiner runs on each node to partially aggregate the local mappers’ output Part0003 Part0002 Part0001 That’s the output file, it has 3 parts on probably 3 different machines
- 30. 30 Use a combiner Tell Hadoop to use a Combiner Not all jobs can use a combiner
- 31. 31 Optimizations 3: Speculative Execution • If one node is slow, it will slow the entire job • Speculative Execution: Hadoop automatically runs each task multiple times in parallel on different nodes • First one finishes, the others will be killed
- 32. 32 Optimizations 4: Locality • Locality: try to run the map code on the same machine that has the relevant data • If not possible, then machine in the same rack • Best effort, no guarantees
- 33. 33 Translating DB Operations to Hadoop Jobs • Select (Filter) Map-only job • Projection Map-only job • Grouping and aggregation Map-Reduce job • Duplicate Elimination Map-Reduce job • Map (Key= hash code of the tuple, Value= tuple itself) • Join Map-Reduce job
- 34. Joining Two Large Datasets: Re-Partition Join 34 Dataset A Dataset B Different join keys HDFS stores data blocks (Replicas are not shown) Mapper M+N Mapper 2 Mapper 1 Mapper 3 - Each mapper processes one block (split) - Each mapper produces the join key and the record pairs Reducer 1 Reducer 2 Reducer N Reducers perform the actual join Shuffling and Sorting Phase Shuffling and sorting over the network
- 35. Joining Large Dataset (A) with Small Dataset (B) Broadcast/Replication Join 35 Dataset A Dataset B Different join keys HDFS stores data blocks (Replicas are not shown) Mapper N Mapper 1 Mapper 2 • Every map task processes one block from A and the entire B • Every map task performs the join (MapOnly job) • Avoid the shuffling and reduce expensive phases
- 36. 36 Hadoop Fault Tolerance • Intermediate data between mappers and reducers are materialized to simple & straightforward fault tolerance • What if a task fails (map or reduce)? • Tasktracker detects the failure • Sends message to the jobtracker • Jobtracker re-schedules the task • What if a datanode fails? • Both namenode and jobtracker detect the failure • All tasks on the failed node are re-scheduled • Namenode replicates the users’ data to another node • What if a namenode or jobtracker fails? • The entire cluster is down Intermediate data (materialized)
- 37. 37 More About Execution Phases
- 38. Execution Phases • InputFormat • Map function • Partitioner • Sorting & Merging • Combiner • Shuffling • Merging • Reduce function • OutputFormat
- 39. 39 Reminder about Covered Phases Shuffle & Sorting based on k Input blocks on HDFS Produces (k, v) ( , 1) Consumes(k, [v]) ( , [1,1,1,1,1,1..]) Produces(k’, v’) ( , 100) Job: Count the number of each color in a data set Part0003 Part0002 Part0001 That’s the output file, it has 3 parts on probably 3 different machines
- 40. 40 Partitioners • The output of the mappers need to be partitioned • # of partitions = # of reducers • The same key in all mappers must go to the same partition (and hence same reducer) • Default partitioning is hash-based • Users can customize it as they need
- 41. 41 Customized Partitioner Returns a partition Id
- 42. 42 Optimization: Balance the Load among Reducers • Assume we have N reducers • Many keys {k1, k2, …, Km} • Distribution is skew • K1 and K2 have many records Send K1 to Reducer 1 Send K2 to Reducer 2 Rest are hash-based K3, K5 K7, K10, K20 ….. …..
- 43. 43 Input/Output Formats • Hadoop’s data model Any data in any format will fit • Text, binary, in a certain structure • How Hadoop understands and reads the data ?? • The input format is the piece of code that understands the data and how to reads it • Hadoop has several built-in input formats to use • Text files, binary sequence files
- 44. 44 Input Formats Record reader reads bytes and converts them to records
- 45. 45 Tell Hadoop which Input/Output Formats Define the formats
- 46. We Covered All Execution Phases • InputFormat • Map function • Partitioner • Sorting & Merging • Combiner • Shuffling • Merging • Reduce function • OutputFormat
- 47. 47 Any Questions So Far…
- 48. 48 More on HDFS
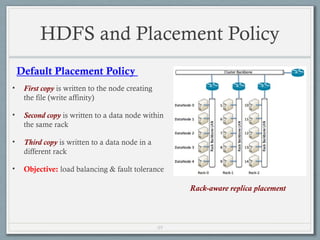
- 49. 49 HDFS and Placement Policy • First copy is written to the node creating the file (write affinity) • Second copy is written to a data node within the same rack • Third copy is written to a data node in a different rack • Objective: load balancing & fault tolerance Default Placement Policy Rack-aware replica placement
- 50. Safemode Startup 03/04/2025 50 On startup Namenode enters Safemode (few seconds). Each DataNode checks in with Heartbeat and BlockReport. Namenode verifies that each block has acceptable number of replicas If things are fine Namenode exits Safemode If some blocks are under replicated Replicate these blocks to other Datanodes Then, exit safemode
- 51. The Communication Protocol 03/04/2025 51 All HDFS communication protocols are layered on top of the TCP/IP protocol A client establishes a connection to a configurable TCP port on the Namenode machine. It talks ClientProtocol with the Namenode The Datanodes talk to the Namenode using Datanode protocol File transfers are done directly between datanodes Does not go though the namenode
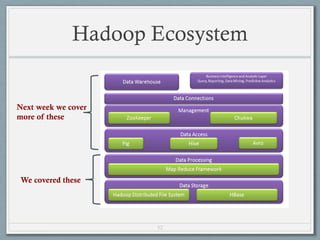
- 52. 52 Hadoop Ecosystem We covered these Next week we cover more of these
- 53. 53 Configuration • Several files control Hadoop’s cluster configurations • Mapred-site.xml: map-reduce parameters • Hdfs-site.xml: HDFS parameters • Matsers: Which node(s) are the master ones • Slaves: which nodes are the slaves • Hadoop has around 190 parameters • Mostly 10-20 are the effective ones
- 55. 55 Bigger Picture: Hadoop vs. Other Systems Distributed Databases Hadoop Computing Model - Notion of transactions - Transaction is the unit of work - ACID properties, Concurrency control - Notion of jobs - Job is the unit of work - No concurrency control Data Model - Structured data with known schema - Read/Write mode - Any data will fit in any format - (un)(semi)structured - ReadOnly mode Cost Model - Expensive servers - Cheap commodity machines Fault Tolerance - Failures are rare - Recovery mechanisms - Failures are common over thousands of machines - Simple yet efficient fault tolerance Key Characteristics - Efficiency, optimizations, fine-tuning - Scalability, flexibility, fault tolerance • Cloud Computing • A computing model where any computing infrastructure can run on the cloud • Hardware & Software are provided as remote services • Elastic: grows and shrinks based on the user’s demand • Example: Amazon EC2
- 56. 56 Recall…DBMS • Data is nicely structured (known in advance) • Data is correct & certain • Data is relatively static & small-mid size • Access pattern: Mix Read/Write • Notion of transactions In Big Data: It is read only, No notion of transactions
- 57. 57 What About Hadoop • Any structure will fit • Data is correct & certain • Data is static, but scales to petabytes • Access pattern: Read-Only • Notion of jobs In Big Data: It is read only, No notion of transactions