Hadoop Summit 2015: Performance Optimization at Scale, Lessons Learned at Twitter (Alex Levenson)
130 likes85,703 views

The document discusses performance optimization lessons learned from Twitter's use of Hadoop, which processes over 300 petabytes of data daily. Key takeaways include the importance of profiling to identify bottlenecks, the benefits of using efficient serialization methods, and leveraging columnar storage formats like Apache Parquet for improved performance. It emphasizes that understanding IO and CPU costs can lead to significant compute resource savings.
































![USE HADOOP'S RAW COMPARATOR API
Hadoop comes with a RawComparator API for comparing
records in their serialized (raw) form
Don't make sorting more expensive than it already is
public interface RawComparator<T> {
public int compare(byte[] b1, int s1, int l1,
byte[] b2, int s2, int l2);
}](https://image.slidesharecdn.com/alexlevensonhadoopsummitv3-150609221151-lva1-app6891/85/Hadoop-Summit-2015-Performance-Optimization-at-Scale-Lessons-Learned-at-Twitter-Alex-Levenson-33-320.jpg)
![USE HADOOP'S RAW COMPARATOR API
Unfortunately, this requires you to write a custom comparator
by hand
And assumes that your data is actually easy to compare in its
serialized form
Don't make sorting more expensive than it already is
public interface RawComparator<T> {
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2);
}](https://image.slidesharecdn.com/alexlevensonhadoopsummitv3-150609221151-lva1-app6891/85/Hadoop-Summit-2015-Performance-Optimization-at-Scale-Lessons-Learned-at-Twitter-Alex-Levenson-34-320.jpg)






























Hadoop Summit 2015: Performance Optimization at Scale, Lessons Learned at Twitter (Alex Levenson)
- 1. L E S S O N S L E A R N E D AT T W I T T E R H A D O O P P E R F O R M A N C E O P T I M I Z AT I O N AT S C A L E A L E X L E V E N S O N | I A N O ' C O N N E L L | @ T H I S W I L LW O R K @ 0 X 1 3 8
- 2. DATA PLATFORM @TWITTER Develop, maintain, and support the core data processing libraries used at Twitter In a good position to make system-wide performance improvements Core Data Libraries Team
- 3. DATA PLATFORM @TWITTER Idiomatic functional Scala library for writing Hadoop map reduce Functional programming is a natural fit for map reduce Compile time type checked Core Data Libraries Team github.com/twitter/scalding
- 4. DATA PLATFORM @TWITTER Columnar storage format for the Hadoop ecosystem Uses the Google Dremel column shredding and assembly algorithm Core Data Libraries Team APACHE PARQUET github.com/apache/parquet-mr
- 5. DATA PLATFORM @TWITTER Streaming map reduce for hybrid realtime / batch topologies Write once, execute in parallel on Storm / Heron (online) and Scalding (offline) Core Data Libraries Team SUMMINGBIRD github.com/twitter/summingbird
- 6. Hadoop at Twitter Scale H A D O O P AT T W I T T E R
- 8. 100k MAP REDUCE JOBS DAILY MULTIPLES OF
- 11. At this scale, even small system-wide improvements can save significant amounts of compute resources C O S T AT S C A L E
- 12. What does your Hadoop cluster spend most of its time doing? W H AT T O I M P R O V E ?
- 13. Profile your cluster, you might be surprised by what you find M E A S U R E - D O N ' T G U E S S
- 14. ENABLE JVM PROFILING WITH -XPROF Built into the JVM (HotSpot), so there's nothing to install Xprof: a low overhead profiler built into the jvm mapreduce.task.profile='true' mapreduce.task.profile.maps='0-' mapreduce.task.profile.reduces='0-' mapreduce.task.profile.params='-Xprof'
- 15. ENABLE JVM PROFILING WITH -XPROF Low overhead (uses stack sampling) Surfaces the most expensive methods Prints directly to task logs (stdout) Xprof: a low overhead profiler built into the jvm
- 16. Flat profile of 412.48 secs (38743 total ticks): SpillThread Interpreted + native Method 12.5% 0 + 32215 org.apache.hadoop.io.compress.lz4.Lz4Compressor.compressBytesDirect 4.6% 0 + 822 java.io.FileOutputStream.writeBytes ... 19.4% 352 + 3082 Total interpreted (including elided) Compiled + native Method 50.0% 8549 + 299 java.lang.StringCoding.decode 16.9% 2823 + 158 cascading.tuple.hadoop.io.HadoopTupleInputStream.getNextElement 4.1% 734 + 0 sun.nio.cs.UTF_8$Decoder.decode 2.3% 401 + 0 org.apache.hadoop.mapred.IFileOutputStream.write 2.0% 352 + 0 cascading.tuple.hadoop.util.TupleComparator.compare 1.7% 296 + 0 org.apache.hadoop.mapred.MapTask$MapOutputBuffer.compare ... 79.0% 13514 + 467 Total compiled Thread-local ticks: 54.3% 21053 Blocked (of total)
- 17. HADOOP CONFIGURATION OBJECT Looks and behaves a lot like a HashMap Surprisingly expensive Configuration conf = new Configuration() conf.set("myKey", "myValue") String value = conf.get("myKey")
- 18. HADOOP CONFIGURATION OBJECT Constructor reads + unzips + parses an XML file from disk Surprisingly expensive public class KryoSerialization { public KryoSerialization() { this(new Configuration()) } }
- 19. HADOOP CONFIGURATION OBJECT get() method involves regular expressions, variable substitution Surprisingly expensive String value = conf.get("myKey")
- 20. HADOOP CONFIGURATION OBJECT Calling these methods in a loop, or once per record, is expensive Some (non trivial) jobs were spending 30% of their time in Configuration methods Surprisingly expensive
- 21. It's hard to predict what needs to be optimized without a profiler L E S S O N L E A R N E D
- 22. If you don't profile, you could be missing easy wins L E S S O N L E A R N E D
- 23. Measure whether IO or CPU is your biggest cost L E S S O N L E A R N E D
- 24. INTERMEDIATE COMPRESSION Xprof surfaced that compression + decompression in the spill thread was taking a lot of time Intermediate outputs are temporary We now use lz4 instead of lzo level 3, which produces 30% larger intermediate data that's faster to read Made some large jobs 1.5X faster Find the right balance
- 25. Record Serialization + Deserialization can be the most expensive part of your job L E S S O N L E A R N E D
- 26. Record Serialization is CPU intensive, and may overshadow IO L E S S O N L E A R N E D
- 27. How to reduce costs due to record serialization? L E S S O N L E A R N E D
- 28. USE HADOOP'S RAW COMPARATOR API Hadoop MR deserializes the map output keys in order to sort them between the map and reduce phases Don't make sorting more expensive than it already is deserialize(keyBytes1).compare(deserialize(keyBytes2))
- 29. USE HADOOP'S RAW COMPARATOR API This can cost a lot, especially for complex non-primitive keys, which is fairly common Don't make sorting more expensive than it already is requests.groupBy { req => (req.country, req.client) }
- 30. USE HADOOP'S RAW COMPARATOR API This can cost a lot, especially for complex non-primitive keys, which is fairly common Don't make sorting more expensive than it already is Complex object that requires sorting requests.groupBy { req => (req.country, req.client) }
- 31. Flat profile of 412.48 secs (38743 total ticks): SpillThread Interpreted + native Method 12.5% 0 + 32215 org.apache.hadoop.io.compress.lz4.Lz4Compressor.compressBytesDirect 4.6% 0 + 822 java.io.FileOutputStream.writeBytes ... 19.4% 352 + 3082 Total interpreted (including elided) Compiled + native Method 50.0% 8549 + 299 java.lang.StringCoding.decode 16.9% 2823 + 158 cascading.tuple.hadoop.io.HadoopTupleInputStream.getNextElement 4.1% 734 + 0 sun.nio.cs.UTF_8$Decoder.decode 2.3% 401 + 0 org.apache.hadoop.mapred.IFileOutputStream.write 2.0% 352 + 0 cascading.tuple.hadoop.util.TupleComparator.compare 1.7% 296 + 0 org.apache.hadoop.mapred.MapTask$MapOutputBuffer.compare ... 79.0% 13514 + 467 Total compiled Thread-local ticks: 54.3% 21053 Blocked (of total)
- 32. USE HADOOP'S RAW COMPARATOR API Hadoop comes with a RawComparator API for comparing records in their serialized (raw) form Don't make sorting more expensive than it already is deserialize(keyBytes1).compare(deserialize(keyBytes2)) compare(keyBytes1, keyBytes2)
- 33. USE HADOOP'S RAW COMPARATOR API Hadoop comes with a RawComparator API for comparing records in their serialized (raw) form Don't make sorting more expensive than it already is public interface RawComparator<T> { public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2); }
- 34. USE HADOOP'S RAW COMPARATOR API Unfortunately, this requires you to write a custom comparator by hand And assumes that your data is actually easy to compare in its serialized form Don't make sorting more expensive than it already is public interface RawComparator<T> { public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2); }
- 35. SCALA MACROS FOR RAW COMPARATORS Macros to the rescue! A slightly more hipster API for Raw Comparators in Scala And a handful of macros to generate implementations of this API for tuples, case classes, thrift objects, primitives, Strings, etc.
- 36. SCALA MACROS FOR RAW COMPARATORS 1 3 f o o 0 1 17 1 88 ... Macros to the rescue! First, creates a custom dense serialization format that's easy to compare 1 3 f o o 0 1 22 0 ... ... non-null String null value non-null int non-null int null value
- 37. SCALA MACROS FOR RAW COMPARATORS 1 3 f o o 0 1 17 1 88 ... Macros to the rescue! Then, creates a compare method that takes advantage of this format 1 3 f 0 o 0 1 22 0 ... ...
- 38. SCALA MACROS FOR RAW COMPARATORS Macros to the rescue! TotalComputeTime Default Raw Comparators 1.5X FASTER
- 39. How to reduce costs due to record serialization? L E S S O N L E A R N E D
- 40. COLUMN PROJECTION Don't read or deserialize data that you don't need struct User { 1: i64 id 2: Address address 3: string name 4 list<Interest> interests }
- 41. COLUMN PROJECTION Columnar file formats like Apache Parquet support this directly Specialized record deserializers can skip over unwanted fields in row oriented storage Don't read or deserialize data that you don't need
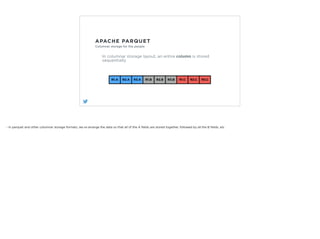
- 42. APACHE PARQUET Columnar storage for the people In traditional row-oriented storage layout, an entire record is stored sequentially R1.A R1.B R1.C R2.A R2.B R2.C R3.A R3.B R3.C
- 43. APACHE PARQUET Columnar storage for the people In traditional row-oriented storage layout, an entire record is stored sequentially 9903489083 "123 elm street" "alice" "columnar file formats" 9903489084 "333 oak street" "bob" "Hadoop" Compressed with lzo / gzip / snappy
- 44. APACHE PARQUET Columnar storage for the people In columnar storage layout, an entire column is stored sequentially R1.A R2.A R3.A R1.B R2.B R3.B R1.C R2.C R3.C
- 45. APACHE PARQUET Columnar storage for the people All user ids stored together In columnar storage layout, an entire column is stored sequentially 9903489083 9903489084 9903489085 9903489075 9903489088 9903489087 "123 elm street" "333 oak street" "827 maple drive"
- 46. APACHE PARQUET Columnar storage for the people Schema aware storage can use specialized encodings 9903489083 9903489084 9903489085 9903489075 9903489088 9903489087 9903489083 +1 +1 -10 +3 -1 delta "twitter.com/foo/bar" "blog.twitter.com" "twitter.com/foo/bar" "twitter.com/foo/bar" "blog.twitter.com" "blog.twitter.com" "blog.twitter.com" "blog.twitter.com/123" "twitter.com/foo/bar": 0 "blog.twitter.com": 1 "blog.twitter.com/123": 2 0 1 0 0 1 1 1 2 dictionary
- 47. FILE SIZE COMPARISON SizeinGB B64 Lzo Thrift Block Lzo Thrift Gzipped Json Lzo Parquet 2X SMALLER B64 Lzo Thrift Block Lzo Thrift Gzipped Json Lzo Parquet
- 48. APACHE PARQUET Columnar storage for the people Collocating entire columns allows for efficient column projection Read off disk only the columns you need Possibly more importantly: deserialize only the columns you need
- 49. TotalComputeTime 1 column 10 columns 40 columns Parquet Lzo Thrift COLUMN PROJECTION WITH PARQUET 3X FASTER 1.5X FASTER 1.15X FASTER
- 50. TotalComputeTime 1 column 10 columns 40 columns Parquet Lzo Thrift COLUMN PROJECTION WITH PARQUET 3X FASTER 1.5X FASTER 1.15X FASTER
- 51. APACHE PARQUET Columnar storage for the people Parquet is often slower to read all columns than row oriented storage Parquet is a dense format, read performance scales with the number of columns in the schema -- nulls take time read Sparse, row oriented formats (thrift) scale with the number of columns present in the data -- nulls take no time read
- 52. COLUMN PROJECTION FOR ROW ORIENTED DATA Row oriented is a very common way to store Thrift, Avro, Protocol Buffers, etc. Specialized record deserializers can skip over unwanted fields in these row oriented storage formats Prototype implemented as a Scala macro that creates a custom deserializer at compile time Don't deserialize data that you don't need
- 53. COLUMN PROJECTION FOR ROW ORIENTED DATA Don't deserialize data that you don't need 198 111 121 054 e l m _ s t r ... a l i c e ... Decode User Id to Long Skip over unwanted address field Decode Name to String
- 54. COLUMN PROJECTION FOR ROW ORIENTED DATA No IO savings But only decodes the fields you care about into objects CPU time spent decoding Strings can be huge compared to time it takes to load + ignore the encoded bytes Don't deserialize data that you don't need
- 55. TotalComputeTime Number of Columns Selected 1 7 10 13 48 Parquet Thrift Parquet Pig Lzo Thrift + Projection COLUMN PROJECTION: THRIFT VS. PARQUET Parquet Thrift has a lot of room for improvement Parquet faster than row oriented until 13 columns This schema is relatively flat, and most columns populated
- 56. APACHE PARQUET Columnar storage for the people Predicate push-down also allows parquet to skip over records that don't match your filter criteria Parquet stores statistics about chunks of records, so in some cases entire chunks of data can be skipped after examining these statistics
- 57. APACHE PARQUET Columnar storage for the people Combining both column projection and predicate push down is a powerful combination
- 58. TotalComputeTime Lzo Thrift Parquet + Filter Parquet + Filter + Project FILTER PUSH DOWN WITH PARQUET 4.3X FASTER
- 59. APACHE PARQUET Columnar storage for the people Predicate push-down performance depends on the nature of the filter Searching for rare records is the best case, entire chunks of records are likely to not contain the records you are looking for
- 60. Key take aways I N S U M M A R Y
- 61. IN SUMMARY Key takeaways Profile! Serialization is expensive, and Hadoop does a lot of it Choose a storage format that fits your access patterns Use column projection Sorting is expensive -- use Raw Comparators IO may not be your bottleneck -- more IO for less CPU may be a good tradeoff
- 62. ACKNOWLEDGEMENTS Thanks to everyone involved! Dmitriy Ryaboy @squarecog Gera Shegalov @gerashegalov Julien Le Dem @J_ Katya Gonina @katyagonina Mansur Ashraf @mansur_ashraf Oscar Boykin @posco Sriram Krishnan @krishnansriram Tianshuo Deng @tsdeng Zak Taylor @zakattacktaylor And many more!
- 63. GET INVOLVED Contributions always welcome! github.com/twitter/scalding github.com/twitter/algebird github.com/twitter/chill github.com/apache/parquet-mr
- 64. JOIN THE FLOCK We're Hiring! Work on data processing challenges at scale Strong commitment to open source jobs.twitter.com Data Platform: (https://about.twitter.com/careers/positions?jvi=oipMYfwb,Job)
- 65. Q U E S T I O N S ? A L E X L E V E N S O N | I A N O ' C O N N E L L | @ T H I S W I L LW O R K @ 0 X 1 3 8