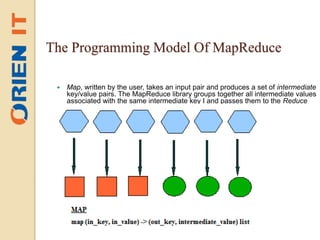
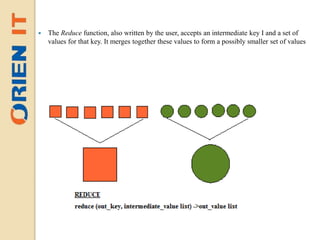
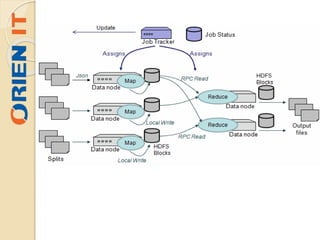
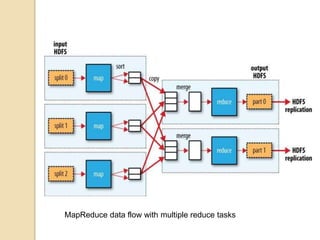
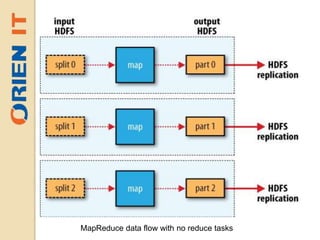
Big data refers to large volumes of unstructured or semi-structured data that is difficult to process using traditional databases and analysis tools. The amount of data generated daily is growing exponentially due to factors like increased internet usage and data collection by organizations. Hadoop is an open-source framework for distributed storage and processing of large datasets across clusters of commodity hardware. It uses HDFS for reliable storage and MapReduce as a programming model to process data in parallel across nodes.