Hadoop vs Apache Spark
Download as PPTX, PDF2 likes833 views

Hadoop and Apache Spark are key projects in the big data ecosystem, providing frameworks for distributed processing of large datasets. Hadoop features components like HDFS for storage, YARN for resource management, and MapReduce for processing, while Spark offers in-memory computations and easier programming capabilities, alongside Spark SQL for structured data and Spark Streaming for real-time data processing. Spark is generally considered faster and more efficient than Hadoop MapReduce, particularly in terms of ease of coding and latency performance.















Hadoop vs Apache Spark
- 2. Hadoop and Spark are popular Apache projects in the big data ecosystem. Apache Spark is an open-source platform, based on the original Hadoop MapReduce component of the Hadoop ecosystem.
- 3. Apache developed Hadoop project as open-source software for reliable, scalable, distributed computing. A framework that allows distributed processing of large datasets across clusters of computers using simple programming models. Hadoop can be easily scaled-up to multi cluster machines, each offering local storage and computation. Hadoop libraries are designed in such a way that it can detect the failed cluster at application layer and can handle those failures by it.
- 4. Hadoop Common: These are Java libraries and utilities required for running other Hadoop modules. These libraries provide OS level and filesystem abstractions and contain the necessary Java files and scripts required to start and run Hadoop. Hadoop Distributed File System (HDFS): A distributed file system that provides high-throughput access to application data. Hadoop YARN: A framework for job scheduling and cluster resource management. Hadoop MapReduce: A YARN-based system for parallel processing of large datasets. The project includes these modules:
- 5. Hadoop MapReduce, HDFS and YARN provide a scalable, fault-tolerant and distributed platform for storage and processing of very large datasets across clusters of commodity computers. Hadoop uses the same set of nodes for data storage as well as to perform the computations. This allows Hadoop to improve the performance of large scale computations by combining computations along with the storage.
- 7. Hadoop Distributed File System – HDFS HDFS is a distributed filesystem that is designed to store large volume of data reliably. HDFS stores a single large file on different nodes across the cluster of commodity machines. HDFS overlays on top of the existing filesystem. Data is stored in fine grained blocks, with default block size of 128MB. HDFS also stores redundant copies of these data blocks in multiple nodes to ensure reliability and fault tolerance. HDFS is a distributed, reliable and scalable file system.
- 8. YARN (Yet Another Resource Negotiator), a central component in the Hadoop ecosystem, is a framework for job scheduling and cluster resource management. The basic idea of YARN is to split up the functionalities of resource management and job scheduling/monitoring into separate daemons. Hadoop YARN
- 9. Hadoop MapReduce MapReduce is a programming model and an associated implementation for processing and generating large datasets with a parallel, distributed algorithm on a cluster. Mapper maps input key/value pair to set of intermediate pairs. Reducer takes this intermediate pairs and process to output the required values. Mapper processes the jobs in parallel on every cluster and Reducer process them in any available node as directed by YARN.
- 10. It is a framework for analysing data analytics on a distributed computing cluster. It provides in-memory computations for increasing speed and data processing over MapReduce. It utilizes the Hadoop Distributed File System (HDFS) and runs on top of existing Hadoop cluster. It can also process both structured data in Hive and streaming data from different sources like HDFS, Flume, Kafka, and Twitter.
- 11. Spark Stream Spark Streaming is an extension of the core Spark API. Processing live data streams can be done using Spark Streaming, that enables scalable, high-throughput, fault-tolerant stream. Input Data can be from any sources like WebStream (TCP sockets), Flume, Kafka, etc., and can be processed using complex algorithms with high-level functions like map, reduce, join, etc. Finally, processed data can be pushed out to filesystems (HDFS), databases, and live dashboards. We can also apply Spark’s graph processing algorithms and machine learning on data streams.
- 12. Spark SQL Apache Spark provides a separate module Spark SQL for processing structured data. Spark SQL has an interface, which provides detailed information about the structure of the data and the computation being performed. Internally, Spark SQL uses this additional information to perform extra optimizations.
- 13. Datasets and DataFrames A distributed collection of data is called as Dataset in Apache Spark. Dataset provides the benefits of RDDs along with utilizing the Spark SQL’s optimized execution engine. A Dataset can be constructed from objects and then manipulated using functional transformations. A DataFrame is a dataset organized into named columns. It is equally related to a relational database table or a R/Python data frame, but with richer optimizations under the hood. A DataFrame can be constructed, using various data source like structured data file or Hive tables or external databases or existing RDDs.
- 14. Resilient Distributed Datasets (RDDs) Spark works on fault-tolerant collection of elements that can be operated on in parallel, the concept called resilient distributed dataset (RDD). RDDs can be created in two ways, parallelizing an existing collection in driver program, or referencing a dataset in an external storage system, such as a shared filesystem, HDFS, HBase, etc.
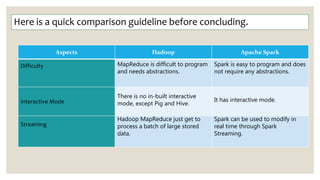
- 15. Here is a quick comparison guideline before concluding. Aspects Hadoop Apache Spark Difficulty MapReduce is difficult to program and needs abstractions. Spark is easy to program and does not require any abstractions. Interactive Mode There is no in-built interactive mode, except Pig and Hive. It has interactive mode. Streaming Hadoop MapReduce just get to process a batch of large stored data. Spark can be used to modify in real time through Spark Streaming.
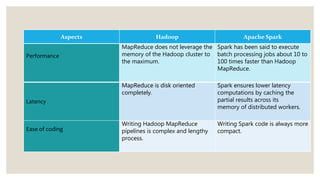
- 16. Aspects Hadoop Apache Spark Performance MapReduce does not leverage the memory of the Hadoop cluster to the maximum. Spark has been said to execute batch processing jobs about 10 to 100 times faster than Hadoop MapReduce. Latency MapReduce is disk oriented completely. Spark ensures lower latency computations by caching the partial results across its memory of distributed workers. Ease of coding Writing Hadoop MapReduce pipelines is complex and lengthy process. Writing Spark code is always more compact.
- 17. CONTACT US Write to us : [email protected] Visit Our Website: https://www.altencalsoftlabs.com USA | FRANCE | UK | INDIA | SINGAPORE