



















Hardware architecture of Summit Supercomputer
- 1. SUMMIT SUPERCOMPUTER Supervisor: Dr. R. Venkatesan Presentation by: Vigneshwar Ramaswamy Masc. in Computer Engineering MUN ID: 201990029 Memorial University of Newfoundland, Canada Summit Supercomputer Architecture 1
- 2. Outline • Introduction • Summit Overview • Specification of Summit • IBM Power9 Architecture • NVIDIA Tesla V100 Architecture • Interconnect • Application Summit Supercomputer Architecture 2
- 3. Introduction • Summit was the fastest computer in the world from November 2018 to June 2020. • 2nd Rank on TOP500 peak speed 148.6 pflops ( High Performance Linpack benchmark). • 8th Rank on Green500 with power efficiency of 14.719 Gflops/watt. • As of June 2018 – 2020, the summit topped HPCG benchmark used by 5 out of 6 Gordon Bell Finalist teams. • Summit has Achieved to reach exa operations per second (exaop), achieving 1.88 exaops during a Genmoic Analysis and expected to reach 3.3 exaops using mixed precision calculations. Summit Supercomputer Architecture 3
- 4. Summit Overview and Specifications • Processor: IBM POWER9™ (2/node) • GPUs: 27,648 NVIDIA Volta V100s (6/node) • Theoretical Peak (Rpeak) performance :200 Pflops • Linpack performance :-148.6 PFlops. • It has 2,414,592 cores • 250petabytes storage capacity • Nodes: 4,608 • Memory/ each node: 512GB DDR4 + 96GB HBM2 (1/2TF,CPU-GPU accessing) • NV Memory/node: 1600GB • Total System Memory: >10PB DDR4 + HBM + Non-volatile Summit Supercomputer Architecture 4
- 5. Summit Overview and Specifications • Interconnect Topology: Mellanox EDR 100G InfiniBand,Non-blocking Fat Tree • 25gigabytes per second between nodes • In-Network Computing acceleration for communications frameworks such as MPI(Message Passing Interface). • Peak Power Consumption: 13MW • Operating system :Red Hat Enterprise Linux (RHEL) version 7.4. Summit Supercomputer Architecture 5
- 6. Summit Nodes Summit Supercomputer Architecture 6 FIGURE 1: SUMMIT NODE BLOCK DIAGRAM SOURCE: Summit, Oak Ridge National Laboratory (official web page), https://www.olcf.ornl.gov/summit/
- 7. IBM POWER9 Processor • Summit’s POWER9 processor contain 24 active cores (4 hardware threads/core). • Peripheral component interconnect express (PCI – Express) Gen4. • NVLink 2.0 • 14nm finFET Semiconductor Process with 8.0 billion transistors • High Bandwidth Signaling Technology • 16Gb/s interface – Local SMP • 25 Gb/s interface – 25G Link – Accelerator, remote SMP Summit Supercomputer Architecture 7 FIGURE 2: POWER9 ARCHITECTURE SOURCE: S. K. Sadasivam, B. W. Thompto, R. Kalla and W. J. Starke, "IBM Power9 Processor Architecture," in IEEE Micro, vol. 37, no. 2, pp. 40-51, Mar.-Apr. 2017.doi: 10.1109/MM.2017.40
- 8. Core pipeline • Microarchitecture has Reduced pipeline length. • Removes the instruction grouping technique . • Introduces new features to proactively avoid hazards in the load store unit (LSU) and improve the LSU’s execution efficiency. • Complete up to 128 instruction per cycle.(SMT 4) • New lock management control improves the performance Summit Supercomputer Architecture 8 FIGURE 3: POWER9 VS POWER8 PIPELINE STAGES SOURCE: S. K. Sadasivam, B. W. Thompto, R. Kalla and W. J. Starke, "IBM Power9 Processor Architecture," in IEEE Micro, vol. 37, no. 2, pp. 40-51, Mar.-Apr. 2017.doi: 10.1109/MM.2017.40
- 9. Key components of Power9 core Summit Supercomputer Architecture 9 Figure 4: SMT4 Core Figure 5: SMT8 Core Figure 6: Power9 SMT4 core. The detailed core block diagram shows all the key components of the Power9 core.
- 10. Cache Capacity of POWER9 Processor • L1I: 32 KiB (per core, 8-way set associative) • L1D: 32 KiB (per core, 8-way) • L2: 512 KiB (per pair of cores) • L3: 120 MiB eDRAM, 20-way Summit Supercomputer Architecture 10 FIGURE 7: SMT8 Cache SOURCE: S. K. Sadasivam, B. W. Thompto, R. Kalla and W. J. Starke, "IBM Power9 Processor Architecture," in IEEE Micro, vol. 37, no. 2, pp. 40-51, Mar.-Apr. 2017.doi: 10.1109/MM.2017.40
- 11. NVDIA Tesla V100 GPU Architecture • This GPU is built with 21 billion transistors • It has peak performance of 7.8 TFLOP/s of double precision floating point performance (FP64) • It has 15.7 TFLOP/s of single precision performance(FP32). • It has 5376 FP32 cores, 5376 INT32 cores, 2688 FP64 cores, 672 Tensor cores, 366 Texture units. • (8) 512-bit memory controllers control access to the 16 GB of HBM2 memory. • 6 MB L2 cache that is available to the SMs • NVIDIA’s NVLink interconnect to pass data between GPUs as well as from CPU-to-GPU Summit Supercomputer Architecture 11 FIGURE 8: NVIDIA TESLA V100 GPU ARCHITECTURE SOURCE: NVIDIA TESLA V100 GPU Architecture, White paper, https://images.nvidia.com/content/volta-architecture/pdf/volta-architecture- whitepaper.pdf
- 12. Volta Streaming Multiprocessor • This new Streaming Multiprocessor architecture delivers major improvements in performance and energy efficiency. • New mixed precision tensor Cores. • 50% higher efficiency on general computation workloads. • High performance L1 data cache. • V100 SM has 64 FP32 cores and 32 FP64 cores per SM. • Supports more threads, warps, and thread blocks when compared to prior GPU generations • A 128-KB combined memory block for shared memory and L1 cache can be configured to allow up to 96 KB of shared memory. • Each SM has four texture units which use to set the size of the L1 cache. Summit Supercomputer Architecture 12 FIGURE 9: VOLTA GV100 Streaming Multiprocessor (SM) SOURCE: NVIDIA TESLA V100 GPU Architecture, White paper, https://images.nvidia.com/content/volta- architecture/pdf/volta-architecture-whitepaper.pdf
- 13. Tensor Cores • V100 GPU contains 640 Tensor Cores: eight (8) per SM and two (2) per each processing block (partition) within an SM. • Each Tensor Cores performs 64 FP FMA(fused multiplication and addition) operations per clock. • For deep learning training ,Tensor Cores provide up to 12x higher peak TFLOPS on Tesla V100 compared to pascal. • For deep learning inference, Tensor Cores provide up to 6x higher peak TFLOPS on Tesla V100 when ompared to pascal. Summit Supercomputer Architecture 13 FIGURE 10: Pascal and Volta 4 x 4 matrix multiplication SOURCE: NVIDIA TESLA V100 GPU Architecture, White paper, https://images.nvidia.com/content/volta-architecture/pdf/volta-architecture- whitepaper.pdf
- 14. Tensor cores • Each Tensor Core operates on a 4x4 matrix and performs the following operation: • D = A×B + C, where A, B, C, and D are 4x4 matrices. • Each FP16 multiply gives a full-precision product which is accumulated in a FP32 addition to provide the result. Summit Supercomputer Architecture 14 FIGURE 11: Tensor Core 4 x 4 Matrix Multiply and accumulate FIGURE 12: Mixed Precision Multiply and Accumulate in Tensor core
- 15. Performance of Tensor Cores on Matrix Multiplications Summit Supercomputer Architecture 15 FIGURE 13: Single precision (FP32) FIGURE 14: Mixed precision
- 16. NVIDIA NVLink • In Summit Supercomputer, the Tesla V100 accelerators and Power9 CPUs are connected with NVLink. • More performance when compared to PCLe interconnects. • Each link provides 25 Gigabytes/second in each direction. Summit Supercomputer Architecture 16 FIGURE 15: NVDIA NVLink
- 17. Interconnect • Nodes are connected with Mellanox dual rail EDR InfiniBand network. • Each node it gives 25 GB/s Bandwidth . • Using dual-rail Mellanox EDR(Enhanced Data Rate) 100Gb/s InfiniBand interconnect for both storage and inter-process communications traffic • All nodes are interconnected with Non-Blocking Fat Tree topology. • Implemented by three level tree. Summit Supercomputer Architecture 17 FIGURE 16: ConnectX-5adapterandinterface withPOWER9 chips FIGURE 17: Fat Tree Topology
- 18. Application- Finding the Drug Compounds to fight against the corona virus • Summit was used to screen through a library of 8000 datasets of known FDA approved drug compounds to fight against the corona virus. • Narrowed down the dataset to 77 in just 2 days. • Summit uses Virus genome to search for a very specific type of drug compounds. • On comparing with the world’s fastest computer Fugaku, which was used to conduct molecule level simulations. • narrowed from 2128 existing drugs and picked 12 drugs that bond easily to the proteins in 10 days. • Fugaku can perform more than 415 quadrillion computations a second which is 2.8 times faster than summit. Summit Supercomputer Architecture 18
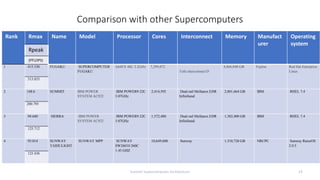
- 19. Comparison with other Supercomputers Summit Supercomputer Architecture 19 Rank Rmax Name Model Processor Cores Interconnect Memory Manufact urer Operating system Rpeak (PFLOPS) 1 415.530 FUGAKU SUPERCOMPUTER FUGAKU A64FX 48C 2.2GHz 7,299,072 Tofu interconnect D 4,866,048 GB Fujitsu Red Hat Enterprise Linux 513.855 2 148.6 SUMMIT IBM POWER SYSTEM AC922 IBM POWER9 22C 3.07GHz 2,414,592 Dual-rail Mellanox EDR Infiniband 2,801,664 GB IBM RHEL 7.4 200.795 3 94.640 SIERRA IBM POWER SYSTEM AC922 IBM POWER9 22C 3.07GHz 1,572,480 Dual-rail Mellanox EDR Infiniband 1,382,400 GB IBM RHEL 7.4 125.712 4 93.014 SUNWAY TAIHULIGHT SUNWAY MPP SUNWAY SW26010 260C 1.45 GHZ 10,649,600 Sunway 1,310,720 GB NRCPC Sunway RaiseOS 2.0.5 125.436
- 20. Supercomputers development over the past 27 years Summit Supercomputer Architecture 20 CM-5 Supercomputer Fugaku Supercomputer Sunway Taihu Light Summit Supercomputer
- 21. •Thank you Summit Supercomputer Architecture 21