High Availability PostgreSQL with Zalando Patroni
21 likes26,326 views

The document discusses the high availability of PostgreSQL using Patroni, including master election, streaming replication, and failover management. It explains components like etcd for leader election and consensus, configuration parameters for Patroni, and the use of pg_rewind for recovering from master failures. Additionally, it outlines the implementation details and provides guidance on setting up the system, including HAProxy configuration and user-defined scripts.



















![http -f PUT http://127.0.0.1:2379/v2/keys/service/fosdem/leader?prevValue="bar" value="bar"
HTTP/1.1 412 Precondition Failed
Content-Length: 89
Content-Type: application/json
Date: Thu, 28 Jan 2016 13:45:27 GMT
X-Etcd-Cluster-Id: 7e27652122e8b2ae
X-Etcd-Index: 2090
{
"cause": "[bar != postgresql0]",
"errorCode": 101,
"index": 2090,
"message": "Compare failed"
}
Only the leader can update the lock](https://image.slidesharecdn.com/hapostgresqlwithpatroni-160203093005/85/High-Availability-PostgreSQL-with-Zalando-Patroni-22-320.jpg)


























High Availability PostgreSQL with Zalando Patroni
- 1. HA PostgreSQL with Patroni Oleksii Kliukin, Zalando SE @alexeyklyukin FOSDEM PGDay 2016 January 29th, 2016, Brussels
- 2. What happens if the master is down? ● Built-in streaming replication is great! ● Only one writable node (primary, master) ● Multiple read-only standbys (replicas) ● Manual failover pg_ctl promote -D /home/postgres/data
- 3. Re-joining the former master Before 9.3: rm -rf /home/postgres/data && pg_basebackup … Before 9.5 git clone -b PGREWIND1_0_0_PG9_4 --depth 1 https://github. com/vmware/pg_rewind.git && cd pg_rewind && apt-get source postgresql-9.4 -y && USE_PGXS=1 make top_srcdir=$(find . -name "postgresql*" -type d) install;
- 4. pg_rewind in 9.5 and above ● pg_rewind available in contrib (apt-get install postgresql-contrib-9.5) ● wal_log_hints = ‘on’ or enable data checksums ● rewind your former master to be able to follow the current one: pg_rewind -D /home/postgres/data --source-server=’ host=localhost port=5433 sslmode=prefer’ ● requires superuser access
- 5. No fixed address ● Pgbouncer ● Pgpool ● HAProxy ● Floating IP/DNS
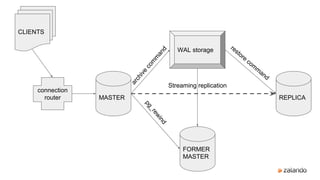
- 6. MASTER REPLICA FORMER MASTER WAL storage connection router CLIENTS Streaming replication pg_rewind archive com m and restore com m and
- 7. How much downtime can you tolerate?
- 10. What about an arbiter? replica master arbiter ping ping master master arbiter vote master replica
- 11. Do we need a distributed consensus? Master election
- 12. The consensus problem requires agreement among a number of processes (or agents) for a single data value. ● leader (master) value defines the current master ● no leader - which node takes the master key ● leader is present - should be the same for all nodes ● leader has disappeared - should be the same for all nodes
- 13. ● etcd from CoreOS ● distributed key-value storage ● directory-tree like ● implements RAFT ● talks REST ● key expiration with TTL and test and set operations 3-rd party to enforce a consensus
- 14. RAFT ● Distributed consensus algorithm (like Paxos) ● Achieves consensus by directing all changes to the leader ● Only commit the change if it’s acknowledged by the majority of nodes ● 2 stages ○ leader election ○ log replication ● Implemented in etcd, consul. http://thesecretlivesofdata.com/raft/
- 15. Patroni ● Manages a single PostgreSQL node ● Commonly runs on the same host as PostgreSQL ● Talks to etcd ● Promotes/demotes the managed node depending on the leader key
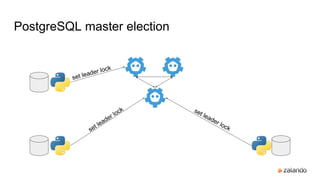
- 16. PostgreSQL master election set leader lock set leader lock set leader lock
- 17. ● every node tries to set the leader lock (key) ● the leader lock can only be set when it’s not present ● once the leader lock is set - no one else can obtain it PostgreSQL master election
- 18. http -f PUT http://127.0.0.1:2379/v2/keys/service/fosdem/leader?prevExist=false value="postgresql0" ttl=30 HTTP/1.1 201 Created ... X-Etcd-Cluster-Id: 7e27652122e8b2ae X-Etcd-Index: 2045 X-Raft-Index: 13006 X-Raft-Term: 2 { "action": "create", "node": { "createdIndex": 2045, "expiration": "2016-01-28T13:38:19.717822356Z", "key": "/service/fosdem/leader", "modifiedIndex": 2045, "ttl": 30, "value": "postgresql0" } } ELECTED
- 19. http -f PUT http://127.0.0.1:2379/v2/keys/service/fosdem/leader?prevExist=false value="postgresql1" ttl=30 HTTP/1.1 412 Precondition Failed ... X-Etcd-Cluster-Id: 7e27652122e8b2ae X-Etcd-Index: 2047 { "cause": "/service/fosdem/leader", "errorCode": 105, "index": 2047, "message": "Key already exists" } Only one leader at a time
- 20. PostgreSQL master election I’m the member I’m the leader with the lock I’m the member Streaming replication
- 21. How do you know the leader is alive? ● leader updates its key periodically (by default every 10 seconds) ● only the leader is allowed to update the key (via compare and swap) ● if the key is not updated in 30 seconds - it expires (via TTL)
- 22. http -f PUT http://127.0.0.1:2379/v2/keys/service/fosdem/leader?prevValue="bar" value="bar" HTTP/1.1 412 Precondition Failed Content-Length: 89 Content-Type: application/json Date: Thu, 28 Jan 2016 13:45:27 GMT X-Etcd-Cluster-Id: 7e27652122e8b2ae X-Etcd-Index: 2090 { "cause": "[bar != postgresql0]", "errorCode": 101, "index": 2090, "message": "Compare failed" } Only the leader can update the lock
- 23. http -f PUT http://127.0.0.1:2379/v2/keys/service/fosdem/leader?prevValue="postgresql0" value=" postgresql0" ttl=30 { "action": "compareAndSwap", "node": { "createdIndex": 2052, "expiration": "2016-01-28T13:47:05.38531821Z", "key": "/service/fosdem/leader", "modifiedIndex": 2119, "ttl": 30, "value": "postgresql0" }, "prevNode": { "createdIndex": 2052, "expiration": "2016-01-28T13:47:05.226784451Z", "key": "/service/fosdem/leader", "modifiedIndex": 2116, "ttl": 22, "value": "postgresql0" } }
- 24. How do you know where to connect? $ etcdctl ls --recursive /service/fosdem /service/fosdem/members /service/fosdem/members/postgresql0 /service/fosdem/members/postgresql1 /service/fosdem/initialize /service/fosdem/leader /service/fosdem/optime /service/fosdem/optime/leader
- 25. $ http http://127.0.0.1:2379/v2/keys/service/fosdem/members/postgresql0 HTTP/1.1 200 OK ... X-Etcd-Cluster-Id: 7e27652122e8b2ae X-Etcd-Index: 3114 X-Raft-Index: 20102 X-Raft-Term: 2 { "action": "get", "node": { "createdIndex": 3111, "expiration": "2016-01-28T14:28:25.221011955Z", "key": "/service/fosdem/members/postgresql0", "modifiedIndex": 3111, "ttl": 22, "value": "{"conn_url":"postgres://replicator:[email protected]:5432/postgres"," api_url":"http://127.0.0.1:8008/patroni","tags":{"nofailover":false,"noloadbalance":false, "clonefrom":false},"state":"running","role":"master","xlog_location":234881568}" } }
- 26. Avoiding the split brain
- 28. Streaming replication in 140 characters
- 29. Patroni configuration parameters ● YAML file with sections ● general parameters ○ ttl: time to leave for the leader and member keys ○ loop_wait: minimum time one iteration of the eventloop takes ○ scope: name of the cluster to run ○ auth: ‘username:password’ string for the REST API ● postgresql section ○ name - name of the postgresql member (should be unique) ○ listen - address:port to listen to (or multiple, i.e. 127.0.0.1,127.0.0.2:5432) ○ connect_address: address:port to advertise to other members (only one, i.e. 127.0.0.5:5432) ○ data_dir: PGDATA (can be initially not empty) ○ maximum_lag_on_failover: do not failover if slave is more than this number of bytes behind ○ use_slots: whether to use replication slots (9.4 and above)
- 30. postgresql subsections ● initdb: section to specify initdb options (i.e. encoding, default auth mode) ● pg_rewind: section with username/password for the user used by pg_rewind ● pg_hba: entries to be added to pg_hba.conf ● replication: replication user, password, and network (for pg_hba.conf) ● superuser: username/password for the superuser account (to be created) ● admin: username/password for the user with createdb/createrole permissions ● create_replica_methods: list of methods to image replicas from the master: ● recovery.conf: parameters put into the recovery.conf (primary_conninfo is written automatically) ● parameters: postgresql.conf parameters (i.e. wal_log_hints or shared_buffers)
- 31. tags (patroni configuration) tags modify behavior of the node they are applied to ● nofailover: the node should not participate in elections or ever become the master ● noloadbalance: the node should be excluded from the load balancer (TODO) ● clonefrom: this node should be bootstrapped from (TODO) ● replicatefrom: this node should do streaming replication from (pull request)
- 32. REST API ● command and control interface ● GET /master and /replica endpoints for the load balancer ● GET /patroni in order to get system information ● POST /restart in order to restart the node ● POST /reinitialize in order to remove the data directory and reinitialize from the master ● POST /failover with leader and optional member names in order to do a controlled failover ● patronictl to do it in a more user-friendly way
- 33. REST API (master) $ http http://127.0.0.1:8008/master HTTP/1.0 200 OK ... Server: BaseHTTP/0.3 Python/2.7.10 { "postmaster_start_time": "2016-01-27 23:23:21.873 CET", "role": "master", "state": "running", "tags": { "clonefrom": false, "nofailover": false, "noloadbalance": false }, "xlog": { "location": 301990984 } }
- 34. REST API (replica) http http://127.0.0.1:8009/master HTTP/1.0 503 Service Unavailable ... Server: BaseHTTP/0.3 Python/2.7.10 { "postmaster_start_time": "2016-01-27 23:23:24.367 CET", "role": "replica", "state": "running", "tags": { "clonefrom": false, "nofailover": false, "noloadbalance": false }, "xlog": { "paused": false, "received_location": 301990984, "replayed_location": 301990984 }
- 35. Configuring HA Proxy for Patroni global maxconn 100 defaults log global mode tcp retries 2 timeout client 30m timeout connect 4s timeout server 30m timeout check 5s frontend ft_postgresql bind *:5000 default_backend bk_db backend bk_db option httpchk server postgresql_127.0.0.1_5432 127.0.0.1:5432 maxconn 100 check port 8008 server postgresql_127.0.0.1_5433 127.0.0.1:5433 maxconn 100 check port 8009
- 37. Separate nodes for etcd and patroni
- 38. Multi-threading to avoid blocking the event loop
- 39. Use synchronous_standby_names=’*’ for synchronous replication
- 40. Use etcd/Zookeeper watches to speed up the failover
- 41. Callbacks Call monitoring code or do some application-specific actions (i.e. change pgbouncer configuration) User-defined scripts set in the configuration file. ● on start ● on stop ● on restart ● on change role
- 42. pg_rewind support ● remove recovery.conf if present ● run a checkpoint on a promoted master (due to the fast promote) ● remove archive status to avoid losing archived segments to be removed ● start in a single-user mode with archive_command set to false ● stop to produce a clean shutdown ● only if checksums or enabled or wal_log_hints are set (via pg_controldata)
- 43. ● Many installations already have Zookeeper running ● No TTL ● Session-specific (ephemeral) keys ● No dynamic nodes (use Exhibitor) Zookeeper support
- 44. Spilo: Patroni on AWS
- 46. Up next ● scheduled failovers ● full support for cascading replication ● consul joins etcd and zookeeper ● manage BDR nodes