Hive join optimizations
9 likes•2,116 views

The document discusses various types of join optimizations in Hive, focusing on their implementation in MapReduce (MR) and Spark. It covers common, map, bucket, sort-merge bucket joins, as well as skew joins, detailing their mechanisms, performance considerations, and the decision-making process for choosing which join to use. Additionally, the document highlights optimizers involved in both MR and Spark that facilitate these join transformations based on query hints and runtime conditions.




























Hive join optimizations
- 1. Hive Join Optimizations: MR and Spark Szehon Ho @hkszehon Cloudera Software Engineer, Hive Committer and PMC
- 2. 2© 2014 Cloudera, Inc. All rights reserved. Background • Joins were one of the more challenging pieces of the Hive on Spark project • Many joins added throughout the years in Hive • Common (Reduce-side) Join • Broadcast (Map-side) Join • Bucket Map Join • Sort Merge Bucket Join • Skew Join • More to come • Share our research on how different joins work in MR • Share how joins are implemented in Hive on Spark
- 3. 3© 2014 Cloudera, Inc. All rights reserved. Common Join • Known as Reduce-side join • Background: Hive (Equi) Join High-Level Requirement: • Scan n tables • Rows with same value on joinKeys are combined -> Result • Process: • Mapper: scan, process n tables and produces HiveKey = {JoinKey, TableAlias}, Value = {row} • Shuffle Phase: • JoinKey used to hash rows of same joinKey value to same reducer • TableAlias makes sure reducers gets rows in sorted order by origin table • Reducer: Join operator combine rows from different tables to produce JoinResult • Worst performance • All table data is shuffled around
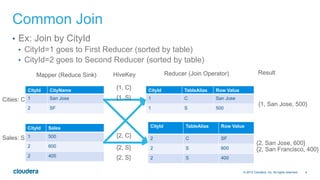
- 4. 4© 2014 Cloudera, Inc. All rights reserved. Common Join • Ex: Join by CityId • CityId=1 goes to First Reducer (sorted by table) • CityId=2 goes to Second Reducer (sorted by table) CityId CityName 1 San Jose 2 SF CityId Sales 1 500 2 600 2 400 CityId TableAlias Row Value 1 C San Jose 1 S 500 CityId TableAlias Row Value 2 C SF 2 S 600 2 S 400 {1, San Jose, 500} {2, San Jose, 600} {2, San Francisco, 400} Mapper (Reduce Sink) Reducer (Join Operator) Cities: C Sales: S {1, C} {1, S} {2, C} {2, S} {2, S} HiveKey Result
- 5. 5© 2014 Cloudera, Inc. All rights reserved. Common Join (MR) TS Sel/FIl RS TS Sel/FIl RS Join Sel/FIl FileSinkOperator Tree MR Work Tree MapRedWork ReduceWorkMapWork TS Sel/FIl RS TS Sel/FIl RS Join Sel/FIl FileSink Produces HIveKey Execute on Mapper Execute on Reducer
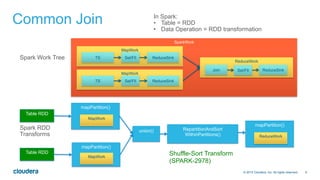
- 6. 6© 2014 Cloudera, Inc. All rights reserved. Common Join Spark Work Tree SparkWork MapWork TS Sel/FIl ReduceSink MapWork TS Sel/FIl ReduceSink ReduceWork Join Sel/FIl ReduceSink union() RepartitionAndSort WithinPartitions() Shuffle-Sort Transform (SPARK-2978) mapPartition() mapPartition() MapWork MapWork mapPartition() ReduceWork Spark RDD Transforms In Spark: • Table = RDD • Data Operation = RDD transformation Table RDD Table RDD
- 7. 7© 2014 Cloudera, Inc. All rights reserved. MapJoin • Known as Broadcast join • Create hashtable from (n-1) small table(s) keyed by Joinkey, broadcasted them in-memory to mappers processing big-table. • Each big-table mapper does lookup of joinkey in small table(s) hashmap -> Join Result • Ex: Join by “CityId” CityId CityName 1 San Jose 2 San Francisco CityId Sales 1 500 2 600 2 400 CityId Sales 1 700 2 200 2 100 Small Table (HashTable) Big Table (Mapper) {1, San Jose, 500} {2, San Francisco, 600} {2, San Francisco, 400} {1, San Jose, 700} {2, San Francisco, 200} {2, San Francisco, 200}
- 8. 8© 2014 Cloudera, Inc. All rights reserved. MapJoin Overview (MR) HS2 Node1 (Small Table Data) Node2 (Small Table Data) Node3 Node4 1. Local Work read, process small table HS2 Node3 Node4 2. Create/Upload hashtable file to distributed cache Node1 Node2 HS2 Node1 (Big Table) 3. Big Table Mapper Reads hashTable from Distributed Cache Node2 Node3 (Big Table) Node4 (Big Table) LocalWork MapWork MapWork MapWork LocalWork • More efficient than common join • Only small-table(s) are moved around
- 9. 9© 2014 Cloudera, Inc. All rights reserved. MapJoin Overview (Spark) • Spark Work for Mapjoin very similar to MR Version, use hashtable file with high replication factor • Note1: We run the small-table processing non-local (parallel) • Note2: Consideration of Spark broadcast variables for broadcast
- 10. 10© 2014 Cloudera, Inc. All rights reserved. MapJoin Decision Implementation • Memory req: N-1 tables need to fit into mapper memory • Two ways Hive decides a mapjoin • Query Hints: • SELECT /*+ MAPJOIN(cities) */ * FROM cities JOIN sales on cities.cityId=sales.cityId; • Auto-converesion based on file-size (“hive.auto.convert.join”) • If N-1 small tables smaller than: “hive.mapjoin.smalltable.filesize”
- 11. 11© 2014 Cloudera, Inc. All rights reserved. MapJoin Optimizers • Multiple decision-points in query-planning = Different Optimizer Paths • MapJoin Optimizers are processors that convert Query Plan • “Logical (Compile-time) optimizers” modify a operator-tree, if known at compile-time how to optimize to mapjoin • “Physical (Runtime) optimizers” modify a physical work (MapRedWork, TezWork, SparkWork), involves more-complex conditional task, when Hive has no info at compile-time MapRedLocalWork TS (Small Table) Sel/FIl HashTableSink MapRedWork MapWork TS (Big Table) Sel/ FIl MapJoin Sel/ FIl FileSink HashTableDummy Local Work Logical Optimizers => TS (Big Table) Sel/FIl TS (Small Table) Sel/FIl RS MapJoin Sel/FIl FileSink Physical Optimizers =>
- 12. 12© 2014 Cloudera, Inc. All rights reserved. MapJoin Optimizers (MR) • Query Hint: Big/Small Table(s) known at compile-time from hints. • Logical Optimizer: MapJoinProcessor • Auto-conversion: Table size not known at compile-time • Physical Optimizer: CommonJoinResolver, MapJoinResolver. • Create Conditional Tasks with all big/small table possibilities: one picked at runtime • Noconditional mode: For some cases, table file-size is known at compile-time and can skip conditional task, but cannot do this for all queries (join of intermediate results..) MapRedLocalWork Cities to HashTable MapRedWork Sales to MapJoin MapRedLocalWork Sales to HashTable MapRedWork Cities to MapJoin MapRedLocalWork Cities Sales Join Condition1 (Cities Small) Condition2 (Sales Small) Condition3 (Neither Small Enough)
- 13. 13© 2014 Cloudera, Inc. All rights reserved. MapJoin Optimizers: Spark • Spark Plan: Support for both query-hints and auto-conversion decisions. • Query Hints • Logical Optimizer: Reuse MapJoinProcessor • Auto-conversion: Use statistics annotated on operators that give estimated output size (like Tez, CBO), so big/small tables known at compile-time too • Logical Optimizer: SparkMapJoinOptimizer Logical Optimizers => MapJoin Operators TS (Big Table) Sel/FIl TS (Small Table) Sel/FIl RS MapJoin Sel/FIl FileSink
- 14. 14© 2014 Cloudera, Inc. All rights reserved. BucketMapJoin • Bucketed tables: rows hash to different bucket files based on bucket-key • CREATE TABLE cities (cityid int, value string) CLUSTERED BY (cityId) INTO 2 BUCKETS; • Join tables bucketed on join key: For each bucket of table, rows with matching joinKey values will be in corresponding bucket of other table • Like Mapjoin, but big-table mappers load to memory only relevant small-table bucket’s hashmap • Ex: Bucketed by “CityId”, Join by “CityId” CityId CityName 3 New York 1 San Jose CityId CityName 2 San Francisco 4 Los Angeles CityId Sales 1 500 3 6000 1 400 CityId Sales 4 50 2 200 4 45 {1, San Jose, 500} {3, New York, 6000} {1, San Jose, 400} {4, Los Angeles, 50} {2, San Francisco, 200} {4, Los Angeles, 45}
- 15. 15© 2014 Cloudera, Inc. All rights reserved. Bucket MapJoin Execution • Very similar to MapJoin • HashTableSink (small-table) writes per-bucket instead of per-table • HashTableLoader (big-table mapper) reads per-bucket
- 16. 16© 2014 Cloudera, Inc. All rights reserved. BucketMapJoin Optimizers (MR, Spark) • Memory Req: Corresponding bucket(s) of small table(s) fit into memory of big table mapper (less than mapjoin) • MR: • Query hint && “hive.optimize.bucket.mapjoin”, all information known at compile-time • Logical Optimizer: MapJoinProcessor (intermediate operator tree) • Spark: • Query hint && “hive.optimize.buckert.mapjoin” • Logical Optimizer: Reuse MapJoinProcessor • Auto-Trigger, done via stats like mapjoin (size calculation estimated to be size/numBuckets) • Logical Optimizer: SparkMapJoinOptimizer, does size calculation of small tables via statistics, divides original number by numBuckets
- 17. 17© 2014 Cloudera, Inc. All rights reserved. SMB Join • CREATE TABLE cities (cityid int, cityName string) CLUSTERED BY (cityId) SORTED BY (cityId) INTO 2 BUCKETS; • Join tables are bucketed and sorted (per bucket) • This allows sort-merge join per bucket. • Advance table until find a match CityId CityName 1 San Jose 3 New York CityId Sales 1 500 1 400 3 6000 CityId Sales 2 200 4 50 4 45 CityId CityName 2 San Francisco 4 Los Angeles {1, San Jose, 500} {1, San Jose, 400} {3, New York, 6000} {2, San Francisco, 200} {4, Los Angeles, 50} {4, Los Angeles, 45}
- 18. 18© 2014 Cloudera, Inc. All rights reserved. SMB Join • Same Execution in MR and Spark • Run mapper process against a “big-table”, which loads corresponding small-table buckets • Mapper reads directly from small-table, no need to create, broadcast small-table hashmap. • No size limit on small table (no need to load table into memory) Node: Small Table Bucket 2 Node: Small Table Bucket 1 Node: Big Table Bucket 1 Node: Big Table Bucket 2 MR: Mappers Spark: MapPartition() Transform MapWork MapWork HS2
- 19. 19© 2014 Cloudera, Inc. All rights reserved. SMB Join Optimizers: MR • SMB plan needs to identify ‘big-table’: one that mappers run against, will load ‘small-tables’. Generally can be determined at compile-time • User gives query-hints to identify small-tables • Triggered by “hive.optimize.bucketmapjoin.sortedmerge” • Logical Optimizer: SortedMergeBucketMapJoinProc • Auto-trigger: “hive.auto.convert.sortmerge.join.bigtable.selection.policy” class chooses big-table • Triggered by “hive.auto.convert.sortmerge.join” • Logical Optimizer: SortedBucketMapJoinProc TS (Big Table) Sel/FIl TS (Small Table) Sel/FIl DummyStore SMBMapJoin Sel/FIl FileSink Logical Optimizers: SMB Join Operator
- 20. 20© 2014 Cloudera, Inc. All rights reserved. SMB Join Optimizers: Spark • Query-hints • Logical Optimizer: SparkSMBJoinHintOptimizer • Auto-Conversion • Logical Optimizer: SparkSortMergeJoinOptimizer TS (Big Table) Sel/FIl TS (Small Table) Sel/FIl DummyStore SMBMapJoin Sel/FIl FileSink Logical Optimizers: SMB Join Operator
- 21. 21© 2014 Cloudera, Inc. All rights reserved. SMB vs MapJoin Decision (MR) • SMB->MapJoin path • In many cases, mapjoin is faster than SMB join so we choose mapjoin if possible • We spawn 1 mapper per bucket = large overhead if table has huge number bucket files • Enabled by “hive.auto.convert.sortmerge.join.to.mapjoin” • Physical Optimizer: SortMergeJoinResolver MapRedWork MapWork SMB Join Work MapRedLocalWork MapRedWork MapRedLocalWork MapRedWork Conditional MapJoin Work MapRedWork MapWork MapJoin Option MapJoin Option SMB Option
- 22. 22© 2014 Cloudera, Inc. All rights reserved. SMB vs MapJoin Decision (Spark) • Make decision at compile-time via stats and config for Mapjoin vs SMB join (can determine mapjoin at compile-time) • Logical Optimizer: SparkJoinOptimizer • If hive.auto.convert.join && hive.auto.convert.sortmerge.join.to.mapjoin and tables fit into memory, delegate to MapJoin logical optimizers • If SMB enabled && (! hive.auto.convert.sortmerge.join.to.mapjoin or tables do not fit into memory) , delegate to SMB Join logical optimizers.
- 23. 23© 2014 Cloudera, Inc. All rights reserved. Skew Join • Skew keys = key with high frequencies, will overwhelm that key’s reducer in common join • Perform a common join for non-skew keys, and perform map join for skewed keys. • A join B on A.id=B.id, with A skewing for id=1, becomes • A join B on A.id=B.id and A.id!=1 union • A join B on A.id=B.id and A.id=1 • If B doesn’t skew on id=1, then #2 will be a map join.
- 24. 24© 2014 Cloudera, Inc. All rights reserved. Skew Join Optimizers (Compile Time, MR) • Skew keys identified by: create table … skewed by (key) on (key_value); • Activated by “hive.optimize.skewjoin.compiletime” • Logical Optimizer: SkewJoinOptimizer looks at table metadata • We fixed bug with converting to mapjoin for skewed rows, HIVE-8610 TS Fil (Skewed Rows) ReduceSink TS Fil (Skewed Rows) ReduceSink Join TS Fil (non-skewed) ReduceSink TS Fil (non-skewed) ReduceSink Join Union
- 25. 25© 2014 Cloudera, Inc. All rights reserved. Skew Join Optimizers (Runtime, MR) • Activated by “hive.optimize.skewjoin” • Physical Optimizer: SkewJoinResolver • During join operator, key is skewed if it passes “hive.skewjoin.key” threshold • Skew key is skipped and values are copied to separate directories • Those directories are processed by conditional mapjoin task. MapRedLocalWork Tab1 to HashTable MapRedWork Tab2 is bigtable MapRedLocalWork Tab2 to HashTable MapRedWork Tab1 is bigtable MapRedLocalWork Tab1 Tab2 Join Condition1(Skew Key Join) Condition2(Skew Key Join)Task3 Tab1 Skew Keys Tab2 Skew Keys
- 26. 26© 2014 Cloudera, Inc. All rights reserved. Skew Join (Spark) • Compile-time optimizer • Logical Optimizer: Re-use SkewJoinOptimizer • Runtime optimizer • Physical Optimizer: SparkSkewJoinResolver, similar to SkewJoinResolver. • Main challenge is to break up some SparkTask that involve aggregations follow by join, in skewjoin case, in order to insert conditional task.
- 27. 27© 2014 Cloudera, Inc. All rights reserved. MR Join Class Diagram (Enjoy) SkewJoinOptimizer (hive.optimize.skewjoin.compiletime) MapJoinProcessor BucketMapJoinOptimizer (hive.optimize.bucket.mapjoin) Tables are skewed N-1 join tables fit in memory User provides join hints && Tables bucketed Users provides Join hints && Tables bucketed && Tables Sorted User provides Join hints Tables are skewed, Skew metadata available Tables bucketed && Tables Sorted SortedMergeBucketMapJoinOptimizer (hive.optimize.bucketmapjoin.sortedmerge) SortedMergeBucketMapJoinProc (if contains MapJoin operator) SortedBucketMapJoinProc (ihive.auto.convert.sortmerge.join) MapJoinFactory (if contains MapJoin, SMBJoin operator) SortMergeJoinResolver (hive.auto.convert.join && hive.auto.convert.sortmerge.join.to.mapjoin) MapJoinResolver (if contains MapWork with MapLocalWork) SkewJoinResolver (hive.optimize.skew.join) CommonJoinResolver (hive.auto.convert.join) SMB MapJoin Skew Join With MapJoin Skew Join With MapJoin MapJoin MapJoin Bucket MapJoin Bucket MapJoin Bucket MapJoin
- 28. 28© 2014 Cloudera, Inc. All rights reserved. Spark Join Class Diagram (Enjoy) SkewJoinOptimizer (hive.optimize.skewjoin.compiletime) SparkMapJoinProcessor BucketMapJoinOptimizer (hive.optimize.bucket.mapjoin) Tables are skewed, Skew metadata available N-1 join tables fit in memory User provides join hints && Tables bucketed Users provides Join hints && Tables bucketed && Tables Sorted User provides Join hints Tables are skewed Tables bucketed && Tables Sorted SparkSMBJoinHintOptimizer (if contains MapJoin operator) SparkSortMergeJoinOptimizer (hive.auto.convert.sortmerge.join && ! hive.auto.convert.sortmerge.join.to.mapjoin) GenSparkWork SparkSortMergeMapJoinFactory (if contains SMBMapJoin operator) SparkMapJoinResolver (if SparkWork contains MapJoinOperator) SkewJoinResolver (hive.optimize.skew.join) Skew Join With MapJoin Skew Join With MapJoin MapJoin or Bucket Mapjoin MapJoin Bucket MapJoin SMB MapJoin SMB MapJoin SparkMapJoinOptimizer (hive.auto.convert.join && hive.auto.convert.sortmerge.join.to.mapjoin)
- 29. 29© 2014 Cloudera, Inc. All rights reserved. Hive on Spark Join Team • Szehon Ho (Cloudera) • Chao Sun (Cloudera) • Jimmy Xiang (Cloudera) • Rui Li (Intel) • Suhas Satish (MapR) • Na Yang (MapR)
- 30. Thank you.