Berlin Buzzwords 2013 - How does lucene store your data?
27 likes•6,679 views

This document summarizes how Lucene stores data in segments. It explains that each segment is a fully functional index that stores metadata, inverted indexes, norms, doc values, stored fields, and term vectors. It describes how these components are stored efficiently using techniques like fixed-length data, variable-length data, string compression, and bit packing. The document also outlines improvements to Lucene's storage since version 4.0, including better compression and no seeking on write. Finally, it provides a benchmark showing storage improvements between Lucene 4.0 and 4.4.












![Copyright Elasticsearch 2013. Copying, publishing and/or distributing without written permission is strictly prohibited
Inverted index
●Terms index: map a term prefix to a block in the dict
○ FST
●Terms dictionary: statistics + pointer in postings lists
●Postings lists: encodes matching docs in sorted order
○ + positions + offsets
Original data 1 2 4 11 42 43 (6 * 4 = 32 bytes)
Split into blocks of 3
(128 in practice)
1 2 4 | 11 42 43
Delta-encode 1 1 2 | 11 31 1
Pack values 3 [1 1 2] | 5 [11 31 1] (1+1+1+2 = 5 bytes)](https://image.slidesharecdn.com/howdoeslucenestoreyourdata-130610085548-phpapp02/85/Berlin-Buzzwords-2013-How-does-lucene-store-your-data-14-320.jpg)







Berlin Buzzwords 2013 - How does lucene store your data?
- 1. Copyright Elasticsearch 2013. Copying, publishing and/or distributing without written permission is strictly prohibited How does Lucene store your data? Adrien Grand @jpountz Apache Lucene/Solr committer Software engineer @ Elasticsearch
- 2. Copyright Elasticsearch 2013. Copying, publishing and/or distributing without written permission is strictly prohibited Outline ●Segments ●What does a segment store? ●Improvements since Lucene 4.0
- 3. Copyright Elasticsearch 2013. Copying, publishing and/or distributing without written permission is strictly prohibited Segments
- 4. Copyright Elasticsearch 2013. Copying, publishing and/or distributing without written permission is strictly prohibited Segments ●Every segment is a fully functional index ●High numbers of segments trigger merges ●Merge: Copy all live data from several segments into a new one
- 5. Copyright Elasticsearch 2013. Copying, publishing and/or distributing without written permission is strictly prohibited Segments ●Immutable (up to deletes) ● SSD-friendly (no write amplification) ● great for caches (including the FS cache) ● easy incremental backups ●Merged together when they are too many of them ● Expunges deleted documents ●An IndexReader is a point-in-time view over a fixed number of segments ● Need to reopen to see changes
- 6. Copyright Elasticsearch 2013. Copying, publishing and/or distributing without written permission is strictly prohibited What does a segment store?
- 7. Copyright Elasticsearch 2013. Copying, publishing and/or distributing without written permission is strictly prohibited What is in a segment? Stores Useful for Segment & Field infos Metadata Getting doc count / index options Live docs Non-deleted docs Excluding deleted docs from results Inverted index The mapping from terms to docs and positions Finding matching docs Norms Index-time boosts Scoring Doc values Any number or (small) bytes Sorting, faceting, custom scoring Stored fields The original doc Result summaries Term vectors Single doc inverted index Highlighting, MoreLikeThis
- 8. Copyright Elasticsearch 2013. Copying, publishing and/or distributing without written permission is strictly prohibited What is in a segment? API Field infos AtomicReader.getFieldInfos() Live docs AtomicReader.getLiveDocs() Inverted index AtomicReader.fields() Norms AtomicReader.getNormValues(String field) Doc values AtomicReader.get*Values(String field) Stored fields AtomicReader.document(int docID, FieldVisitor visitor) Term vectors AtomicReader.getTermVectors()
- 9. Copyright Elasticsearch 2013. Copying, publishing and/or distributing without written permission is strictly prohibited Doc IDs ●Lucene gives sequential doc IDs to all documents in a segment, from 0 (inclusive) to AtomicReader.maxDoc() (exclusive) ●Uniquely identifies documents inside a segment ● ie. if the inverted index API says that document 42 matches the term "bbuzz", I can query the stored fields API with the same ID ●Allows for efficient storage ● doc IDs can be used as ordinals ● Small & dense ints are easy to compress
- 10. Copyright Elasticsearch 2013. Copying, publishing and/or distributing without written permission is strictly prohibited Detour: bit packing ●Efficient technique to store blocks of small ints ● Supports random access ● Special case: bits per value = 1 is a bit set ●Say you want to store ● 5 30 1 1 10 12 ● Raw data: 6 * 32 = 192 bits ● Packed : 6 * 5 = 30 bits (84% size reduction!) 00000000000000000000000000000101 = 5 00000000000000000000000000011110 = 30 00000000000000000000000000000001 = 1 00000000000000000000000000000001 = 1 00000000000000000000000000001010 = 10 00000000000000000000000000001100 = 12
- 11. Copyright Elasticsearch 2013. Copying, publishing and/or distributing without written permission is strictly prohibited Fixed-length data ●Dense doc IDs are great for single-valued fixed-length data ● Store data sequentially ● Data for doc N is at offset N * dataLength ● Allows for fast and memory-efficient lookups ●Live docs (1 bit per value) ●Norms (1 byte per value) ●Numeric doc values ● Blocks with independent numbers of bits per value 4096 values 4096 values 4096 values ● Block idx ○ docID / 4096 ● Idx in block ○ docID % 4096
- 12. Copyright Elasticsearch 2013. Copying, publishing and/or distributing without written permission is strictly prohibited Variable-length data end addresses bytes ●Binary doc values ●Stored fields ●Term vectors ●Need one level of indirection: store end addresses ● Easy to compress since end addresses are increasing ● Only store endAddress - (docID+1) * avgLength
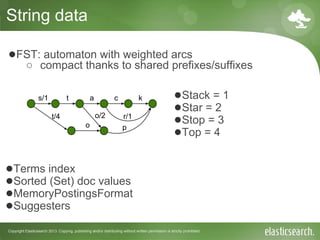
- 13. Copyright Elasticsearch 2013. Copying, publishing and/or distributing without written permission is strictly prohibited String data ●Terms index ●Sorted (Set) doc values ●MemoryPostingsFormat ●Suggesters s/1 t a c k r/1o/2 p t/4 ●FST: automaton with weighted arcs ○ compact thanks to shared prefixes/suffixes ●Stack = 1 ●Star = 2 ●Stop = 3 ●Top = 4 o
- 14. Copyright Elasticsearch 2013. Copying, publishing and/or distributing without written permission is strictly prohibited Inverted index ●Terms index: map a term prefix to a block in the dict ○ FST ●Terms dictionary: statistics + pointer in postings lists ●Postings lists: encodes matching docs in sorted order ○ + positions + offsets Original data 1 2 4 11 42 43 (6 * 4 = 32 bytes) Split into blocks of 3 (128 in practice) 1 2 4 | 11 42 43 Delta-encode 1 1 2 | 11 31 1 Pack values 3 [1 1 2] | 5 [11 31 1] (1+1+1+2 = 5 bytes)
- 15. Copyright Elasticsearch 2013. Copying, publishing and/or distributing without written permission is strictly prohibited Improvements since Lucene 4.0
- 16. Copyright Elasticsearch 2013. Copying, publishing and/or distributing without written permission is strictly prohibited Improvements since Lucene 4.0 ●LUCENE-4399 (4.1): no seek on write ●LUCENE-4498 (4.1): terms "pulsed" when freq=1 ●Compression: ● LUCENE-3892 (4.1): postings encoding moved from vInt to packed ints: smaller & faster! ● LUCENE-4226 (4.1): compressed stored fields ● LUCENE-4599 (4.2): compressed term vectors ● LUCENE-4547 (4.2): better doc values: ● blocks of packed ints for numbers ● compression of addresses for binary ● FST for Sorted (Set) ● LUCENE-4936 (4.4): compression for date DV
- 17. Copyright Elasticsearch 2013. Copying, publishing and/or distributing without written permission is strictly prohibited Performance ●http://people.apache.org/~mikemccand/lucenebench/Term.html
- 18. Copyright Elasticsearch 2013. Copying, publishing and/or distributing without written permission is strictly prohibited Detour: LZ4 ●Super simple, blazing fast compression codec ●http://code.google.com/p/lz4/ ●https://github.com/jpountz/lz4-java ●Example ● L: literals ● R: reference = (offset decrement, length) ● 1 2 3 6 7 6 7 6 7 6 7 8 9 1 2 3 6 7 10 ● L 1 2 3 6 7 R(2,6) L 8 9 R(13,5) L 10
- 19. Copyright Elasticsearch 2013. Copying, publishing and/or distributing without written permission is strictly prohibited Detour: LZ4 ●https://github.com/ning/jvm-compressor-benchmark
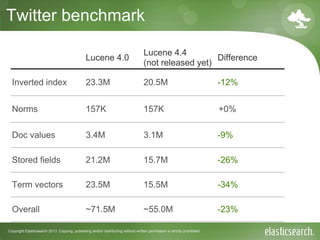
- 20. Copyright Elasticsearch 2013. Copying, publishing and/or distributing without written permission is strictly prohibited Twitter benchmark ●Quick benchmark on a Twitter corpus ● 160908 tweets ● WhitespaceAnalyzer Type Indexed Stored Doc values Term vectors id long yes yes - - created_at long - yes numeric - user.name string yes yes sorted - text text yes yes - yes
- 21. Copyright Elasticsearch 2013. Copying, publishing and/or distributing without written permission is strictly prohibited Twitter benchmark Lucene 4.0 Lucene 4.4 (not released yet) Difference Inverted index 23.3M 20.5M -12% Norms 157K 157K +0% Doc values 3.4M 3.1M -9% Stored fields 21.2M 15.7M -26% Term vectors 23.5M 15.5M -34% Overall ~71.5M ~55.0M -23%
- 22. Copyright Elasticsearch 2013. Copying, publishing and/or distributing without written permission is strictly prohibited Questions?