Hybrid Apache Spark Architecture with YARN and Kubernetes
0 likes449 views

The document details a hybrid architecture for deploying Spark at Lyft using both YARN and Kubernetes, highlighting the advantages and challenges of each model. Key discussions include deployment processes, infrastructure management, and future plans for consolidating batch compute on Spark. The authors, Catalin Toda and Rohit Menon, share their experiences with scaling, IAM roles, and addressing resource management challenges within this hybrid setup.






















Hybrid Apache Spark Architecture with YARN and Kubernetes
- 1. Hybrid Spark Architecture with Yarn and Kubernetes Catalin Toda (Sr Engineer @ Lyft) Rohit Menon (Staff Engineer @ Lyft)
- 2. Agenda ▪ Spark @ Lyft ▪ Challenges with K8s ▪ Hybrid Model ▪ Spark Operator ▪ Image Hierarchy ▪ Spark Wrapper ▪ Progress & Future Plans
- 3. What is Spark Used For @ Lyft • Primarily Python Shop with some Scala • Running in AWS with S3 as permanent storage • Interactive Development & ML with Jupyter and Spark • ML Batch Use Cases • Pricing • ETA/Routing • Mapping • ETL Use Cases • Event Ingestion • GraphQL Offline Model • Financial Datasets / SOX Complaint Datasets / Experimentation Offline Batch Analysis and many more • HiveQL to Spark-SQL Migration
- 4. 2018 Spark on Yarn • Every major use case had its own ephemeral yarn cluster • Management overhead for infra team • Custom Dependency management per cluster to pull in python dependencies • Tough to test/maintain cluster bootstrap scripts • Custom IAM role/permission overhead
- 5. 2019 Spark On Kubernetes • Lyft Infra supported Kubernetes deployment • Google OSS spark-on-k8s operator availability • Flyte (Container native scheduler) took off in Lyft for ML use case • Containerized workloads with easier python dependency management • Simpler support for per job IAM roles
- 6. Spark On Kubernetes Architecture
- 7. 2020 Spark on Kubernetes • Maturing support for Spark on K8s • Lyft Hadoop/Hive infrastructure as K8s deployment • Auto-scaling handled for YARN cluster based on RM load • Spark ETL workloads move over from Yarn to Spark on k8s • Start hitting limits with Lyft k8s Infra setup • Custom solutions required to support growing scale • Group jobs to reduce spiky requests to k8s and AWS control plane • Add new k8s clusters to support stronger isolation model
- 8. Current Spark Scale on K8s - 1000 concurrent jobs - 5 Kubernetes Clusters - 20k executors at peak - 1 AWS region - 5 AWS Availability Zones
- 9. Challenges with K8s Model • IPv4 Address Shortage • Shortage across all 5 AZs • Leads to driver and executors startup delays - IAM Wait Delays - AWS IAM assignment could be throttled - IAM wait to assure assignment increasing delays - Infrastructure issues - Etcd size tuning - Impact of bad k8s node
- 10. Challenges with K8s Model • Image Overheads • Every project has their own image • Registration of images for different environments • Startup delays caused by uncached image • New nodes • New image releases • Release model • Infra prepares a base image with Spark latest changes • Customers manage final release when the image is tested • Leads to maximum 1 month rollout time due to several images to be updated
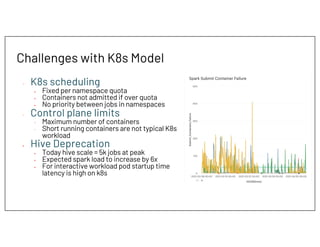
- 11. Challenges with K8s Model - K8s scheduling • Fixed per namespace quota • Containers not admitted if over quota • No priority between jobs in namespaces - Control plane limits - Maximum number of containers - Short running containers are not typical K8s workload • Hive Deprecation • Today hive scale = 5k jobs at peak • Expected spark load to increase by 6x • For interactive workload pod startup time latency is high on k8s
- 12. 2021 Hybrid Model (YARN + K8s) Separation by Workload Type • Containerized (K8s) • Pyspark + Custom Dependencies • ML interactive • Non-containerized (YARN) • SQL Interactive • SQL Batch • Scala Workloads • Simple Pyspark with no dependencies
- 14. Advantages of Hybrid Model • YARN executors have low startup latency and can handle spikes • Easier Queue and Resource management • Workloads without custom dependencies do not get penalized with k8s infra overheads • Mature support for dynamic allocation and external shuffle service
- 15. Single Entry Point • Spark-on-k8s-operator as single entry point for both YARN and K8s • Integrates easily open source • Compatibility with Flyte • No Lyft specific code • Multi version branch by default • Driver runs on k8s in client mode • We plan to contribute this to OSS • Current OSS design add overhead of spark submit pod • Sets us infra team to move workloads seamlessly between resource managers
- 16. Spark Wrapper Design Stage 1 - Part of base image - Downloads and runs stage2 Stage 2 - Manipulate configs - Run spark driver - Capture job logs and results - Push application metrics
- 17. Spark Wrapper • Custom image entry point • Allows config management based on environments • Allows switching between resource managers • Metrics • Push to events - queryable/dashboard using lyft stack • Push to statsd for real time monitoring/alerting • Integrates well with Lyft Infra • Spark on k8s operator remains in sync with upstream • Lyft specific logic that integrates with in-house tools • Adds runtime controller to images
- 18. Image Hierarchy/Distribution • One base image for spark per spark version • Containerized spark extends base image • Users can further extend containerized base image to add custom dependencies • ML base image • Users maintain their own image • Non-containerized use the base image directly • Infra updates the image • Consistent experience across use cases
- 19. Progress so far - Best of Both Worlds - Spark driver startup < 1s - Resource allocation managed in YARN - K8s scale reduced by 20x - IP addresses requirement reduced by 20x - Per job IAM Roles using Web Identity provider
- 20. Progress so far - Best of Both Worlds - No migration needed for containerized customers - Python dependency management using an utility library - The latest version is synced in all environments (adhoc, k8s, YARN)
- 21. Future Plans - Consolidate Batch Compute on Spark (Hive -> Spark) - Evaluate Data Lake technologies - Continue to scale k8s and Spark Infrastructure
- 22. Conclusion - YARN vs K8s - Workload analysis is required before identifying the best solution - For Lyft - existing YARN infrastructure helped choosing a hybrid model - Fixing K8s model requires: - K8s supports to IPv6 in the latest versions - Scaling - Number of k8s clusters and a gateway to perform the routing between them - Image - Design considerations/overheads with high number of images - Quota - Investing in projects trying to solve this aspect - Web Identity Provider - Custom Roles in K8s
- 23. Q & A Contact Info: [email protected] [email protected]