Ibis: operating the Python data ecosystem at Hadoop scale by Wes McKinney
1 like1,131 views

Wes McKinney gave a presentation on scaling Python analytics on Hadoop and Impala. He discussed how Python has become popular for data science but does not currently scale to large datasets. The Ibis project aims to address this by providing a composable Python API that removes the need for hand-coding SQL and allows analysts to interact with distributed SQL engines like Impala from Python. Ibis expressions are compiled to optimized SQL queries for efficient execution on large datasets.




























Ibis: operating the Python data ecosystem at Hadoop scale by Wes McKinney
- 1. 1 © Cloudera, Inc. All rights reserved. Ibis: Scaling Python Analy=cs on Hadoop and Impala Wes McKinney, SF Data Mining Meetup 2015-‐10-‐22 @wesmckinn
- 2. 2 © Cloudera, Inc. All rights reserved. Me • R&D at Cloudera • Serial creator of structured data tools / user interfaces • Mathema=cian — MIT ‘07 • “Professional SQL programmer” 2007-‐2010 (@ AQR) • Created pandas (Python library) in 2008 • Wrote bestseller Python for Data Analysis 2012 • Founder of DataPad
- 3. 3 © Cloudera, Inc. All rights reserved. Python is popular… • Python has become a standard language of data science • Why is it popular? • Maximizes produc=vity for data engineers and data scien=sts • Build robust sobware and do interac=ve data analysis with 100% Python code • Easy-‐to-‐learn and makes happy and produc=ve data teams • Large, diverse open source development community • Comprehensive libraries: data wrangling, ML, visualiza=on, etc. • Main use case: data science & engineering swiss army knife on small-‐to-‐medium size data
- 4. 4 © Cloudera, Inc. All rights reserved. …but Python does not scale today • Python ecosystem confined to single-‐node analysis • Great for smaller data sets • Requires sampling or aggrega=ons for larger data • Distributed tools compromise in various ways • Extrac=ng samples or aggrega=ons for larger data means: • “Scales” by losing more fidelity • Addi=onal ETL overhead to extract samples/aggrega=ons • Loss of produc=vity with mul=ple languages, tools, etc • Blocks certain analysis and use cases
- 5. 5 © Cloudera, Inc. All rights reserved. Industry Analy=cs Scien=fic Compu=ng Heterogeneous data Flat tables and JSON Spark / MapReduce SQL DFS-‐friendly / streaming data formats More physical machines Homogeneous data Mul=dimensional arrays HPC tools Linear algebra Scien=fic data formats Fewer physical machines Some simplis=c generaliza=ons
- 6. 6 © Cloudera, Inc. All rights reserved. Industry Analy=cs Scien=fic Compu=ng Heterogeneous data Flat tables and JSON Spark / MapReduce SQL DFS-‐friendly / streaming data formats More physical machines Homogeneous data Mul=dimensional arrays HPC tools Linear algebra Scien=fic data formats (e.g. HDF5) Fewer physical machines Some simplis=c generaliza=ons Python: heavy investment, generally Python: light investment, generally
- 7. 7 © Cloudera, Inc. All rights reserved. pandas • Hugely popular Python table / “data frame” library • Labeled table, array, and =me series data structures • Popular for data prepara=on, ETL, and in-‐memory analy=cs • Built using Python’s scien=fic compu=ng stack • User API / domain specific language • Bespoke in-‐memory analy=cs / rela=onal algebra engine • IO interfaces (CSV, SQL, etc.) • Expanded data type system (beyond NumPy) • Supports flat data only (or semi-‐structured data that can be flaqened)
- 8. 8 © Cloudera, Inc. All rights reserved. Many SQL engines … and more
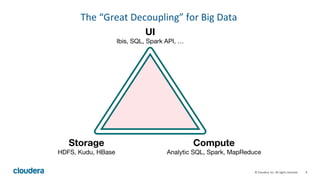
- 9. 9 © Cloudera, Inc. All rights reserved. The “Great Decoupling” for Big Data UI Ibis, SQL, Spark API, … Compute Analytic SQL, Spark, MapReduce Storage HDFS, Kudu, HBase
- 10. 10 © Cloudera, Inc. All rights reserved. A sample big data architecture Kafka Kafka Kafka Kafka Application data HDFS JSON Spark/MapReduce Columnar storage Analytic SQL Engine User SQL
- 11. 11 © Cloudera, Inc. All rights reserved. Nested / Complex types support • Arrays, structs, maps, and unions as first-‐class value types • Analyze JSON-‐like data directly without flaqening or normaliza=on • Most new SQL engines have some level of support • Impala • Presto • Drill • BigQuery • Spark SQL • Hive • …
- 12. 12 © Cloudera, Inc. All rights reserved. Ibis in a nutshell • For Python programmers doing analy=cs in industry • Project Blog: hqp://blog.ibis-‐project.org • Joint project with Impala team @ Cloudera • Apache-‐licensed, open source hqp://github.com/cloudera/ibis • Crabing a compelling Python-‐on-‐Hadoop user experience • Remove SQL coding from user workflows • Develop high performance Python extension APIs
- 13. 13 © Cloudera, Inc. All rights reserved. Ibis in a nutshell, cont’d • Composable Python DSL (“Ibis expressions”) makes hand-‐coding SQL SELECT statements unnecessary • Ibis for SQL Programmers: hqp://docs.ibis-‐project.org/sql.html • Development roadmap targets Impala (C++ / LLVM) query engine • … but SQL compiler toolchain is general purpose • Current supports Impala and SQLite, but soon other dialects • We welcome external contributors for other Analy=c SQL engines
- 14. 14 © Cloudera, Inc. All rights reserved.
- 15. 15 © Cloudera, Inc. All rights reserved. Benefits of Ibis • Maximize developer produc=vity • Mirrors single-‐node Python experience • Solve big data problems without leaving Python • Leverage Python skills, ecosystem, and tools • Python as first-‐class language for Hadoop • Full-‐fidelity analysis without extrac=ons • Python analysis at any scale • Na=ve hardware speeds for a broad set of use cases
- 16. 16 © Cloudera, Inc. All rights reserved. Brief interac=ve demo
- 17. 17 © Cloudera, Inc. All rights reserved. Ibis/Impala Joint Roadmap • More natural data modeling • Complex types support • Integra=on with full Python data ecosystem • Advanced analy=cs + machine learning • Enable use of performance compu=ng tools • User extensibility with na=ve performance • In-‐memory columnar format • Python-‐to-‐LLVM IR compila=on • Workflow and usability tools
- 18. 18 © Cloudera, Inc. All rights reserved. Execu=ng data science languages in the compute layer UI Ibis, SQL, Spark API, … Compute Analytic SQL, Spark, MapReduce Storage HDFS, Kudu, HBase Python, R, Julia, …?
- 19. 19 © Cloudera, Inc. All rights reserved. Enabling interoperability with big data systems • Distributed / MPP query engines: implemented in a host language • Typically C/C++ or Java/Scala • User-‐defined func=ons (UDFs) through various means • Implement in host language • Implement in user language through some external language protocol (oben RPC-‐based) • External UDFs are usually very slow (cf: PL/Python, PySpark, etc.)
- 20. 20 © Cloudera, Inc. All rights reserved. What are UDFs good for? • Note: industry data scien=sts have libraries containing 100s of UDFs for Hive or other distributed query engines • Custom data transforma=ons • Custom domain logic (date / =me / data types) • Custom data types • Custom aggrega=ons (incl. machine learning / sta=s=cs expressible as reduc=ons)
- 21. 21 © Cloudera, Inc. All rights reserved. Why are external UDFs slow? • Serializa=on / deserializa=on overhead • Scalar vs vectorized computa=ons • RPC overhead
- 22. 22 © Cloudera, Inc. All rights reserved. Example: Vectoriza=on for interpreted languages SUM(CASE WHEN x > y THEN x ELSE x + y END)
- 23. 23 © Cloudera, Inc. All rights reserved. Vectorized vs Interpreted perf
- 24. 24 © Cloudera, Inc. All rights reserved. How to make them fast? • Common run=me memory representa=on for tabular data • Share-‐memory (zero-‐copy or memcpy-‐only) external UDF protocol • Vectorized UDF interface (for interpreted languages) • Impala is uniquely posi=oned to play well with Ibis • Best-‐in-‐class performance and scalability • C++ and LLVM-‐based (JIT compiler) run=me • Unified, efficient data interchange amongst Ibis, Impala, and Kudu will enable high performance real =me analy=cs from Python
- 25. 25 © Cloudera, Inc. All rights reserved. Memory representa=on • Many query engines are standardizing on in-‐memory columnar rep’n of materialized transient data • Impala: hqp://blog.cloudera.com/blog/2015/07/whats-‐next-‐for-‐impala-‐more-‐ reliability-‐usability-‐and-‐performance-‐at-‐even-‐greater-‐scale/ • Apache Drill: hqps://drill.apache.org/faq/ • Industry-‐standard serializa=on format: Apache Parquet • hqps://parquet.apache.org/
- 26. 26 © Cloudera, Inc. All rights reserved. Serializa=on vs In-‐memory • Serializa=on formats (e.g. Parquet) • Op=mize for IO / DFS throughput at expense of CPU/memory bus throughput • Do not consider random access or in-‐memory analy=cs as a goal • No standardized in-‐memory containers for materialized data from file / RPC protocols (Parquet, Thrib, protobuf, Avro, etc.)
- 27. 27 © Cloudera, Inc. All rights reserved. Standardized in-‐memory columnar (IMC) • Compact in-‐memory representa=on for semistructured data • Part of Impala’s upcoming dev roadmap • Some prior IMC-‐for-‐SQL work: Apache Drill • Standardized memory representa=on means data can be shared without serializa=on • Create a canonical C/C++ implementa=on for use in Python / R / Julia
- 28. 28 © Cloudera, Inc. All rights reserved. Ibis’s Vision • Uncompromised Python experience • 100% Python end-‐to-‐end user workflows • Enable integra=on with the exis=ng Python data ecosystem (pandas, scikit-‐ learn, NumPy, etc) • Interac=ve at big data scale • Full-‐fidelity analysis without extrac=ons • Scalability for big data • Na=ve hardware speeds for a broad set of use cases
- 29. 29 © Cloudera, Inc. All rights reserved. Thank you Wes McKinney @wesmckinn Views are my own