IMC Summit 2016 Breakout - Yanping Wang - Non-volatile Generic Object Programming Model for In-Memory Computing (Spark) Performance Improvement
1 like414 views

The document introduces Apache Mnemonic, a non-volatile programming model aimed at improving in-memory computing performance for Java applications by leveraging advanced storage media. It focuses on creating a non-volatile object model that allows Java programmers to manage data in place, minimizing serialization costs and improving performance in big data frameworks like Spark. The document also outlines practical use cases and provides insights into performance improvements, particularly in machine learning applications.



















IMC Summit 2016 Breakout - Yanping Wang - Non-volatile Generic Object Programming Model for In-Memory Computing (Spark) Performance Improvement
- 1. INTRODUCING A NON-VOLATILE GENERIC OBJECT PROGRAMMING MODEL FOR IN-MEMORY COMPUTING (SPARK) PERFORMANCE IMPROVEMENT YANPING WANG APACHE MNEMONIC (INCUBATING) PROJECT LEADER [email protected]
- 2. STORAGE MEDIA EVOLUTION IS CHANGING FUTURE SW PROGRAMING
- 3. STORAGE MEDIA EVOLUTION Storage Media Evolution: NAND and 3D XPoint are filling the Speed and Capacity gap between DRAM and Hard Disk Drives Software is facing the challenge on how to use them
- 4. STORAGE MEDIA EVOLUTION IS CHANGING FUTURE SW PROGRAMING
- 5. FROM IN-MEMORY TO IN-PLACE Moving from In-Memory Computing to In-Place Computing Mnemonic is a pioneering project to extend in-memory computing to in-place computing using next generation NVM storage media. (Picture was taken from Ken Gibson’s Storage Industry Summit January, 20, 2016)
- 6. A NON-VOLATILE PROGRAMMING MODEL FOR JAVA APPLICATION DEVELOPERS
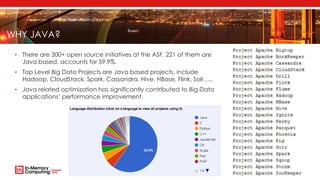
- 7. WHY JAVA? • There are 300+ open source initiatives at the ASF. 221 of them are Java based, accounts for 59.9%. • Top Level Big Data Projects are Java based projects, include Hadoop, CloudStack, Spark, Cassandra, Hive, HBase, Flink, Solr….. • Java related optimization has significantly contributed to Big Data applications’ performance improvement.
- 8. TRADITIONAL JAVA BASED BIG DATA FRAMEWORKS AND APPLICATIONS
- 9. OUR PROPOSAL: OFF-HEAP, LEAVE DATA IN-PLACE
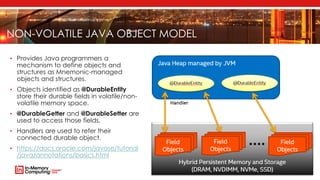
- 10. NON-VOLATILE JAVA OBJECT MODEL • Provides Java programmers a mechanism to define objects and structures as Mnemonic-managed objects and structures. • Objects identified as @DurableEntity store their durable fields in volatile/non- volatile memory space. • @DurableGetter and @DurableSetter are used to access those fields. • Handlers are used to refer their connected durable object. • https://docs.oracle.com/javase/tutorial /java/annotations/basics.html
- 11. AN EXAMPLE OF NON-VOLATILE LINKED LIST (LAZY LOADING)
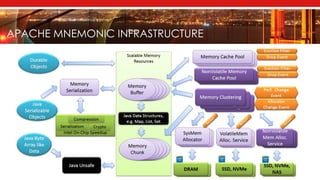
- 13. APACHE MNEMONIC STRUCTURE • Performance oriented architecture • Unified platform enabling Framework • Unique non-volatile object model • Flexible & extensible focal point for optimization
- 14. MNEMONIC SEARCH EXAMPLE • Traditional search: SerDes, caching, pack/unpack, burst temp objects creation and destruction cost can be as high as 70-80% • Mnemonic Search: in- place creation & update, no SerDes, load on demand, no need to normalize
- 15. MNEMONIC PROJECT POSITIONING • Apache Mnemonic (Incubating) is a Java based non-volatile memory library (API) for in-place structured data processing and computing • Addresses Big Data performance issues • High cost of Serialization/De-serialization • Frequent unpredicted long Garbage Collection pauses • Burst temporary object creation/destruction • Frequent high cost JNI call with stack marshalling • System paging and kernel structure updating due to massive data processing
- 16. USE CASE EXAMPLE: SPARK + MNEMONIC =IN-PLACE MACHINE LEARNING COMPUTING
- 17. NON-VOLATILE RDD CODE FOR SPARK • ~600 line of Non-Volatile RDD code is added into Spark, to alter data flow from Spark RDD via JVM heap to Mnemonic. • Spill RDDs to off-heap and disk can be avoid. • RDD data cache and local checkpoints can also be avoided when using Nonvolatile or Durable objects.
- 18. INTERNAL STRUCTURED DATA REPRESENTATION Spark experiment uses: 2D Linked List data structure to store data in persistent memory and storage. N nodes: represent the first level of linked list. V nodes: represent the values of first level of linked list that still is a linked list. Only N2 and V1 (methods & volatile fields) are instantiated on heap.
- 20. SPARK MLLIB KMEANS PERFORMANCE IMPROVEMENT • SPARK ML Kmeans implements one of the most popular clustering algorithms • Exp1: spark.storage.memoryFraction 0.6 • Exp2: spark.storage.memoryFraction 0.2
- 21. CONFIGURATION FOR PERFORMANCE MEASUREMENT Platform Software Configuration OS: CentOS 7 JVM: JDK8 update 60 ParallelOldGC is used for Spark ML throughput workload Kmeans Spark1.5.0 Platform Hardware Haswell EP (72 cores, E5-2699 v3 @ 2.3GHz) 256GB DDR4-2133 on-board Memory Storage media: SATA SSD Device Model: INTEL SSDSC2BB016T4 Serial Number: BTWD442601311P6HGN User Capacity: 1.60 TB SATA Version is: SATA 3.0, 6.0 Gb/s Spark Kmeans Experiments Setting: – System memory is reduced to 128G via static dummy ramfile occupancy – 20 executors with 4 GB JVM heap, 3 cores – Both of datasets are stored on SSD – Experiment 1 – spark.storage.memoryFraction 0.6 – 100,000,000 records with vector in 12 dimension (20 partitions) – Experiment 2 – spark.storage.memoryFraction 0.2 – 100,000,000 records with vector in 6 dimension (20 partitions)
- 22. DISCLAIMERS Apache Mnemonic is an effort undergoing incubation at The Apache Software Foundation (ASF), sponsored by Apache Incubator PMC. Incubation is required of all newly accepted projects until a further review indicates that the infrastructure, communications, and decision making process have stabilized in a manner consistent with other successful ASF projects. While incubation status is not necessarily a reflection of the completeness or stability of the code, it does indicate that the project has yet to be fully endorsed by the ASF. While Mnemonic is operating within the time period where the application is processing their durable data, Mnemonic guarantees the persistency once Mnemonic is closed gracefully.
- 23. PROJECT LINKS Mnemonic Community: [email protected] Source Code: https://github.com/apache/incubator-mnemonic JIRA Tracking: https://issues.apache.org/jira/browse/MNEMONIC Website: http://mnemonic.incubator.apache.org/ Contact: [email protected]; [email protected]