Index Usage for Nested Logical Queries
Download as PPTX, PDF0 likes823 views

The document discusses MongoDB query systems, specifically focusing on nested logical queries like 'AND' and 'OR'. It explains the conditions under which queries have indexed solutions and when index bounds are considered 'tight'. The examples provided illustrate the challenges of indexing in compound queries and how outside predicates affect query optimization.



![#MDBW17
QUERY SYSTEM
{a: 1, $or: [{b: 1}, {c: 1}]}](https://image.slidesharecdn.com/crystaladay11440-1520tessavitabileindexusagefornested-170621222900/85/Index-Usage-for-Nested-Logical-Queries-4-320.jpg)
![#MDBW17
QUERY SYSTEM
Parsing
{a: 1, $or: [{b: 1}, {c: 1}]}](https://image.slidesharecdn.com/crystaladay11440-1520tessavitabileindexusagefornested-170621222900/85/Index-Usage-for-Nested-Logical-Queries-5-320.jpg)
![#MDBW17
QUERY SYSTEM
Parsing
{a: 1, $or: [{b: 1}, {c: 1}]}
Plan
Generation](https://image.slidesharecdn.com/crystaladay11440-1520tessavitabileindexusagefornested-170621222900/85/Index-Usage-for-Nested-Logical-Queries-6-320.jpg)
![#MDBW17
QUERY SYSTEM
Parsing Plan Selection
{a: 1, $or: [{b: 1}, {c: 1}]}
Plan
Generation](https://image.slidesharecdn.com/crystaladay11440-1520tessavitabileindexusagefornested-170621222900/85/Index-Usage-for-Nested-Logical-Queries-7-320.jpg)
![#MDBW17
QUERY SYSTEM
Parsing Plan Selection Plan
Execution
{a: 1, $or: [{b: 1}, {c: 1}]}
Plan
Generation](https://image.slidesharecdn.com/crystaladay11440-1520tessavitabileindexusagefornested-170621222900/85/Index-Usage-for-Nested-Logical-Queries-8-320.jpg)
![#MDBW17
QUERY SYSTEM
Plan
Generation
Parsing Plan Selection Plan
Execution
{a: 1, $or: [{b: 1}, {c: 1}]}](https://image.slidesharecdn.com/crystaladay11440-1520tessavitabileindexusagefornested-170621222900/85/Index-Usage-for-Nested-Logical-Queries-9-320.jpg)

![#MDBW17
WHAT IS A NESTED LOGICAL QUERY?
{beds: 2, $or: [{area: "Lake View"}, {el: "Red"}]}
AND
OR
beds: 2
area:
"Lake
View"
el:
"Red"](https://image.slidesharecdn.com/crystaladay11440-1520tessavitabileindexusagefornested-170621222900/85/Index-Usage-for-Nested-Logical-Queries-11-320.jpg)

![#MDBW17
An AND has an indexed solution when at least one child
has an indexed solution.
beds: 1
IXSCAN:
beds: [2, 2]
AND
beds: 2
el:
"Red"
WHEN DOES A LOGICAL QUERY HAVE AN
INDEXED SOLUTION?](https://image.slidesharecdn.com/crystaladay11440-1520tessavitabileindexusagefornested-170621222900/85/Index-Usage-for-Nested-Logical-Queries-13-320.jpg)
![#MDBW17
An AND has an indexed solution when at least one child
has an indexed solution.
beds: 1
IXSCAN:
beds: [2, 2]
FETCH:
filter: {el: "Red"}
AND
beds: 2
el:
"Red"
WHEN DOES A LOGICAL QUERY HAVE AN
INDEXED SOLUTION?](https://image.slidesharecdn.com/crystaladay11440-1520tessavitabileindexusagefornested-170621222900/85/Index-Usage-for-Nested-Logical-Queries-14-320.jpg)

![#MDBW17
An OR has an indexed solution when all children have
indexed solutions.
OR
area:
"Lake
View"
el:
"Red"
WHEN DOES A LOGICAL QUERY HAVE AN
INDEXED SOLUTION?
area: 1
el: 1
IXSCAN:
area: ["Lake View", "Lake View"]](https://image.slidesharecdn.com/crystaladay11440-1520tessavitabileindexusagefornested-170621222900/85/Index-Usage-for-Nested-Logical-Queries-16-320.jpg)
![#MDBW17
An OR has an indexed solution when all children have
indexed solutions.
OR
area:
"Lake
View"
el:
"Red"
WHEN DOES A LOGICAL QUERY HAVE AN
INDEXED SOLUTION?
area: 1
el: 1
IXSCAN:
area: ["Lake View", "Lake View"] IXSCAN:
el: ["Red", "Red"]](https://image.slidesharecdn.com/crystaladay11440-1520tessavitabileindexusagefornested-170621222900/85/Index-Usage-for-Nested-Logical-Queries-17-320.jpg)
![#MDBW17
An OR has an indexed solution when all children have
indexed solutions.
OR
OR
area:
"Lake
View"
el:
"Red"
WHEN DOES A LOGICAL QUERY HAVE AN
INDEXED SOLUTION?
area: 1
el: 1
IXSCAN:
area: ["Lake View", "Lake View"] IXSCAN:
el: ["Red", "Red"]](https://image.slidesharecdn.com/crystaladay11440-1520tessavitabileindexusagefornested-170621222900/85/Index-Usage-for-Nested-Logical-Queries-18-320.jpg)

![#MDBW17
Index bounds are "tight" when all documents in the index
bounds match the query.
beds: 1, el: 1
IXSCAN:
beds: [2, 2],
el: [MinKey, MaxKey]
AND
beds: 2
el:
"Red"
WHEN ARE INDEX BOUNDS "TIGHT"?](https://image.slidesharecdn.com/crystaladay11440-1520tessavitabileindexusagefornested-170621222900/85/Index-Usage-for-Nested-Logical-Queries-20-320.jpg)
![#MDBW17
Index bounds are "tight" when all documents in the index
bounds match the query.
beds: 1, el: 1
IXSCAN:
beds: [2, 2],
el: [MinKey, MaxKey]
FETCH:
filter: {el: "Red"}
AND
beds: 2
el:
"Red"
WHEN ARE INDEX BOUNDS "TIGHT"?](https://image.slidesharecdn.com/crystaladay11440-1520tessavitabileindexusagefornested-170621222900/85/Index-Usage-for-Nested-Logical-Queries-21-320.jpg)
![#MDBW17
Index bounds are "tight" when all documents in the index
bounds match the query.
beds: 1, el: 1
IXSCAN:
beds: [2, 2],
el: [MinKey, MaxKey]
FETCH:
filter: {el: "Red"}
AND
beds: 2
el:
"Red"
WHEN ARE INDEX BOUNDS "TIGHT"?
AND
beds: 2
el:
"Red"](https://image.slidesharecdn.com/crystaladay11440-1520tessavitabileindexusagefornested-170621222900/85/Index-Usage-for-Nested-Logical-Queries-22-320.jpg)
![#MDBW17
Index bounds are "tight" when all documents in the index
bounds match the query.
beds: 1, el: 1
IXSCAN:
beds: [2, 2],
el: [MinKey, MaxKey]
FETCH:
filter: {el: "Red"}
AND
beds: 2
el:
"Red"
WHEN ARE INDEX BOUNDS "TIGHT"?
AND
beds: 2
el:
"Red"
IXSCAN:
beds: [2, 2],
el: ["Red", "Red"]](https://image.slidesharecdn.com/crystaladay11440-1520tessavitabileindexusagefornested-170621222900/85/Index-Usage-for-Nested-Logical-Queries-23-320.jpg)
![#MDBW17
WHEN ARE INDEX BOUNDS "TIGHT"?
"executionStats": {
"nReturned": 10
"totalKeysExamined": 10000,
"totalDocsExamined": 10000,
"executionStages": {
"stage": "FETCH",
"filter": {"el": {"$eq" : "Red"}},
"nReturned": 10,
"docsExamined": 10000,
"inputStage": {
"stage": "IXSCAN",
"nReturned": 10000,
"keyPattern": {"beds": 1, "el": 1},
"indexBounds": {"beds": ["[2.0, 2.0]"], "el": ["[MinKey, MaxKey]"]},
"keysExamined": 10000}}}](https://image.slidesharecdn.com/crystaladay11440-1520tessavitabileindexusagefornested-170621222900/85/Index-Usage-for-Nested-Logical-Queries-24-320.jpg)
![#MDBW17
WHEN ARE INDEX BOUNDS "TIGHT"?
"executionStats": {
"nReturned": 10
"totalKeysExamined": 10,
"totalDocsExamined": 10,
"executionStages": {
"stage": "FETCH”,
"nReturned": 10,
"docsExamined": 10,
"inputStage": {
"stage": "IXSCAN",
"nReturned": 10,
"keyPattern": {"beds": 1, "el": 1},
"indexBounds": {"beds": ["[2.0, 2.0]"], "el": ["["Red", "Red"]"]},
"keysExamined": 10}}}](https://image.slidesharecdn.com/crystaladay11440-1520tessavitabileindexusagefornested-170621222900/85/Index-Usage-for-Nested-Logical-Queries-25-320.jpg)


![#MDBW17
IXSCAN:
area: ["Lake View", "Lake View"],
beds: [MinKey, MaxKey]
AND
OR
beds: 2
area:
"Lake
View"
el:
"Red"
EXAMPLE #1
We do not get tight index bounds for an OR child because we do not
use outside predicates to tighten bounds in a compound index.
area: 1, beds: 1
el: 1, beds: 1](https://image.slidesharecdn.com/crystaladay11440-1520tessavitabileindexusagefornested-170621222900/85/Index-Usage-for-Nested-Logical-Queries-28-320.jpg)
![#MDBW17
IXSCAN:
el: ["Red", "Red"],
beds: [MinKey, MaxKey]
IXSCAN:
area: ["Lake View", "Lake View"],
beds: [MinKey, MaxKey]
AND
OR
beds: 2
area:
"Lake
View"
el:
"Red"
EXAMPLE #1
We do not get tight index bounds for an OR child because we do not
use outside predicates to tighten bounds in a compound index.
area: 1, beds: 1
el: 1, beds: 1](https://image.slidesharecdn.com/crystaladay11440-1520tessavitabileindexusagefornested-170621222900/85/Index-Usage-for-Nested-Logical-Queries-29-320.jpg)
![#MDBW17
IXSCAN:
el: ["Red", "Red"],
beds: [MinKey, MaxKey]
IXSCAN:
area: ["Lake View", "Lake View"],
beds: [MinKey, MaxKey]
AND
OR
beds: 2
area:
"Lake
View"
el:
"Red"
OR
EXAMPLE #1
We do not get tight index bounds for an OR child because we do not
use outside predicates to tighten bounds in a compound index.
area: 1, beds: 1
el: 1, beds: 1](https://image.slidesharecdn.com/crystaladay11440-1520tessavitabileindexusagefornested-170621222900/85/Index-Usage-for-Nested-Logical-Queries-30-320.jpg)
![#MDBW17
IXSCAN:
el: ["Red", "Red"],
beds: [MinKey, MaxKey]
IXSCAN:
area: ["Lake View", "Lake View"],
beds: [MinKey, MaxKey]
AND
OR
beds: 2
area:
"Lake
View"
el:
"Red"
OR
FETCH:
filter: {beds:
2}
EXAMPLE #1
We do not get tight index bounds for an OR child because we do not
use outside predicates to tighten bounds in a compound index.
area: 1, beds: 1
el: 1, beds: 1](https://image.slidesharecdn.com/crystaladay11440-1520tessavitabileindexusagefornested-170621222900/85/Index-Usage-for-Nested-Logical-Queries-31-320.jpg)
![#MDBW17
.EXPLAIN() OUTPUT
"winningPlan": {
"stage": "FETCH",
"filter": {"beds": {"$eq" : 2}},
"inputStage": {
"stage": "OR",
inputStages": [
{
"stage": "IXSCAN",
"keyPattern": {"area": 1, "beds": 1},
"indexBounds": {"area": ["["Lake View", "Lake View"]"], "beds": ["[MinKey, MaxKey]"]}
},
{
"stage": "IXSCAN",
"keyPattern": {"el": 1, "beds": 1},
"indexBounds": {"el": ["["Red", "Red"]"], "beds": ["[MinKey, MaxKey]"]}}]}}](https://image.slidesharecdn.com/crystaladay11440-1520tessavitabileindexusagefornested-170621222900/85/Index-Usage-for-Nested-Logical-Queries-32-320.jpg)


![#MDBW17
IXSCAN:
beds: [2, 2],
area: [MinKey, MaxKey]
AND
OR
beds: 2
area:
"Lake
View"
el:
"Red"
EXAMPLE #2
An OR child cannot have an indexed solution because we do not use
an outside predicate to fulfill the first position in a compound index.
beds: 1, area: 1
beds: 1, el: 1](https://image.slidesharecdn.com/crystaladay11440-1520tessavitabileindexusagefornested-170621222900/85/Index-Usage-for-Nested-Logical-Queries-35-320.jpg)
![#MDBW17
IXSCAN:
beds: [2, 2],
area: [MinKey, MaxKey]
AND
OR
beds: 2
area:
"Lake
View"
el:
"Red"
FETCH:
filter: {$or: [{area: "Lake View"}, {el: "Red"}]}
EXAMPLE #2
An OR child cannot have an indexed solution because we do not use
an outside predicate to fulfill the first position in a compound index.
beds: 1, area: 1
beds: 1, el: 1](https://image.slidesharecdn.com/crystaladay11440-1520tessavitabileindexusagefornested-170621222900/85/Index-Usage-for-Nested-Logical-Queries-36-320.jpg)
![#MDBW17
.EXPLAIN() OUTPUT
"winningPlan": {
"stage": "FETCH",
"filter": {$or": [{"area": {"$eq": "Lake View"}}, {"el": {"$eq": "Red"}}]},
"inputStage": {
"stage": "IXSCAN",
"keyPattern": {"beds": 1, "area": 1},
"indexBounds": {"beds": ["[2.0, 2.0]"], "area": ["[MinKey, MaxKey]"]}}}](https://image.slidesharecdn.com/crystaladay11440-1520tessavitabileindexusagefornested-170621222900/85/Index-Usage-for-Nested-Logical-Queries-37-320.jpg)




![#MDBW17
DISJUNCTIVE NORMAL FORM
OR
AND AND
beds:
2
beds:
2
area:
"Lake
View"
el:
"Red"
area: 1, beds: 1
el: 1, beds: 1
IXSCAN:
area: ["Lake View", "Lake View"],
beds: [2, 2]
Fixed!](https://image.slidesharecdn.com/crystaladay11440-1520tessavitabileindexusagefornested-170621222900/85/Index-Usage-for-Nested-Logical-Queries-42-320.jpg)
![#MDBW17
DISJUNCTIVE NORMAL FORM
OR
AND AND
beds:
2
beds:
2
area:
"Lake
View"
el:
"Red"
area: 1, beds: 1
el: 1, beds: 1
IXSCAN:
area: ["Lake View", "Lake View"],
beds: [2, 2]
IXSCAN:
el: ["Red", "Red"],
beds: [2, 2]
Fixed!](https://image.slidesharecdn.com/crystaladay11440-1520tessavitabileindexusagefornested-170621222900/85/Index-Usage-for-Nested-Logical-Queries-43-320.jpg)
![#MDBW17
DISJUNCTIVE NORMAL FORM
OR
AND AND
beds:
2
beds:
2
area:
"Lake
View"
el:
"Red"
area: 1, beds: 1
el: 1, beds: 1
IXSCAN:
area: ["Lake View", "Lake View"],
beds: [2, 2]
IXSCAN:
el: ["Red", "Red"],
beds: [2, 2]
OR
Fixed!](https://image.slidesharecdn.com/crystaladay11440-1520tessavitabileindexusagefornested-170621222900/85/Index-Usage-for-Nested-Logical-Queries-44-320.jpg)
![#MDBW17
DISJUNCTIVE NORMAL FORM
OR
AND AND
beds:
2
beds:
2
area:
"Lake
View"
el:
"Red"
area: 1, beds: 1
el: 1, beds: 1
IXSCAN:
area: ["Lake View", "Lake View"],
beds: [2, 2]
IXSCAN:
el: ["Red", "Red"],
beds: [2, 2]
OR
Fixed!](https://image.slidesharecdn.com/crystaladay11440-1520tessavitabileindexusagefornested-170621222900/85/Index-Usage-for-Nested-Logical-Queries-45-320.jpg)


![#MDBW17
DISJUNCTIVE NORMAL FORM
area: 1
el: 1
beds: 1
Previously…
AND
beds: 2 OR
area:
"Lake
View"
el:
"Red"
IXSCAN:
beds: [2, 2]](https://image.slidesharecdn.com/crystaladay11440-1520tessavitabileindexusagefornested-170621222900/85/Index-Usage-for-Nested-Logical-Queries-48-320.jpg)
![#MDBW17
DISJUNCTIVE NORMAL FORM
area: 1
el: 1
beds: 1
Previously…
AND
beds: 2 OR
area:
"Lake
View"
el:
"Red"
IXSCAN:
beds: [2, 2]
FETCH:
filter: {$or: [{area: "Lake View"}, {el: "Red"}]}](https://image.slidesharecdn.com/crystaladay11440-1520tessavitabileindexusagefornested-170621222900/85/Index-Usage-for-Nested-Logical-Queries-49-320.jpg)
![#MDBW17
DISJUNCTIVE NORMAL FORM
AND
beds: 2 OR
area:
"Lake
View"
el:
"Red"
area: 1
el: 1
beds: 1
AND
beds: 2 OR
area:
"Lake
View"
el:
"Red"
IXSCAN:
beds: [2, 2]
FETCH:
filter: {$or: [{area: "Lake View"}, {el: "Red"}]}
Previously…](https://image.slidesharecdn.com/crystaladay11440-1520tessavitabileindexusagefornested-170621222900/85/Index-Usage-for-Nested-Logical-Queries-50-320.jpg)
![#MDBW17
DISJUNCTIVE NORMAL FORM
AND
beds: 2 OR
area:
"Lake
View"
el:
"Red"
area: 1
el: 1
beds: 1
IXSCAN:
area: ["Lake View", "Lake View"]
AND
beds: 2 OR
area:
"Lake
View"
el:
"Red"
IXSCAN:
beds: [2, 2]
FETCH:
filter: {$or: [{area: "Lake View"}, {el: "Red"}]}
Previously…](https://image.slidesharecdn.com/crystaladay11440-1520tessavitabileindexusagefornested-170621222900/85/Index-Usage-for-Nested-Logical-Queries-51-320.jpg)
![#MDBW17
DISJUNCTIVE NORMAL FORM
AND
beds: 2 OR
area:
"Lake
View"
el:
"Red"
area: 1
el: 1
beds: 1
IXSCAN:
area: ["Lake View", "Lake View"]
IXSCAN:
el: ["Red", "Red"]
AND
beds: 2 OR
area:
"Lake
View"
el:
"Red"
IXSCAN:
beds: [2, 2]
FETCH:
filter: {$or: [{area: "Lake View"}, {el: "Red"}]}
Previously…](https://image.slidesharecdn.com/crystaladay11440-1520tessavitabileindexusagefornested-170621222900/85/Index-Usage-for-Nested-Logical-Queries-52-320.jpg)
![#MDBW17
DISJUNCTIVE NORMAL FORM
AND
beds: 2 OR
area:
"Lake
View"
el:
"Red"
area: 1
el: 1
beds: 1
IXSCAN:
area: ["Lake View", "Lake View"]
IXSCAN:
el: ["Red", "Red"]
OR
AND
beds: 2 OR
area:
"Lake
View"
el:
"Red"
IXSCAN:
beds: [2, 2]
FETCH:
filter: {$or: [{area: "Lake View"}, {el: "Red"}]}
Previously…](https://image.slidesharecdn.com/crystaladay11440-1520tessavitabileindexusagefornested-170621222900/85/Index-Usage-for-Nested-Logical-Queries-53-320.jpg)
![#MDBW17
DISJUNCTIVE NORMAL FORM
AND
beds: 2 OR
area:
"Lake
View"
el:
"Red"
area: 1
el: 1
beds: 1
IXSCAN:
area: ["Lake View", "Lake View"]
IXSCAN:
el: ["Red", "Red"]
OR
FETCH:
filter: {beds: 2}
AND
beds: 2 OR
area:
"Lake
View"
el:
"Red"
IXSCAN:
beds: [2, 2]
FETCH:
filter: {$or: [{area: "Lake View"}, {el: "Red"}]}
Previously…](https://image.slidesharecdn.com/crystaladay11440-1520tessavitabileindexusagefornested-170621222900/85/Index-Usage-for-Nested-Logical-Queries-54-320.jpg)














![#MDBW17
OR-PUSHDOWNS: EXAMPLE #1
area: 1, beds: 1
el: 1, beds: 1
AND
AND AND
beds:
2
beds:
2
beds:
2
OR
area:
"Lake
View"
el:
"Red"
IXSCAN:
area: ["Lake View", "Lake View"],
beds: [2, 2]](https://image.slidesharecdn.com/crystaladay11440-1520tessavitabileindexusagefornested-170621222900/85/Index-Usage-for-Nested-Logical-Queries-70-320.jpg)
![#MDBW17
OR-PUSHDOWNS: EXAMPLE #1
area: 1, beds: 1
el: 1, beds: 1
AND
AND AND
beds:
2
beds:
2
beds:
2
OR
area:
"Lake
View"
el:
"Red"
IXSCAN:
area: ["Lake View", "Lake View"],
beds: [2, 2]
IXSCAN:
el: ["Red", "Red"],
beds: [2, 2]](https://image.slidesharecdn.com/crystaladay11440-1520tessavitabileindexusagefornested-170621222900/85/Index-Usage-for-Nested-Logical-Queries-71-320.jpg)
![#MDBW17
OR-PUSHDOWNS: EXAMPLE #1
area: 1, beds: 1
el: 1, beds: 1
AND
AND AND
beds:
2
beds:
2
beds:
2
OR
area:
"Lake
View"
el:
"Red"
IXSCAN:
area: ["Lake View", "Lake View"],
beds: [2, 2]
IXSCAN:
el: ["Red", "Red"],
beds: [2, 2]
OR](https://image.slidesharecdn.com/crystaladay11440-1520tessavitabileindexusagefornested-170621222900/85/Index-Usage-for-Nested-Logical-Queries-72-320.jpg)
![#MDBW17
OR-PUSHDOWNS: EXAMPLE #1
area: 1, beds: 1
el: 1, beds: 1
AND
AND AND
beds:
2
beds:
2
beds:
2
OR
area:
"Lake
View"
el:
"Red"
IXSCAN:
area: ["Lake View", "Lake View"],
beds: [2, 2]
IXSCAN:
el: ["Red", "Red"],
beds: [2, 2]
OR
FETCH:
filter: {beds: 2}](https://image.slidesharecdn.com/crystaladay11440-1520tessavitabileindexusagefornested-170621222900/85/Index-Usage-for-Nested-Logical-Queries-73-320.jpg)
![#MDBW17
OR-PUSHDOWNS: EXAMPLE #1
area: 1, beds: 1
el: 1, beds: 1
AND AND
beds:
2
beds:
2
OR
area:
"Lake
View"
el:
"Red"
IXSCAN:
area: ["Lake View", "Lake View"],
beds: [2, 2]
IXSCAN:
el: ["Red", "Red"],
beds: [2, 2]
OR](https://image.slidesharecdn.com/crystaladay11440-1520tessavitabileindexusagefornested-170621222900/85/Index-Usage-for-Nested-Logical-Queries-74-320.jpg)
![#MDBW17
.EXPLAIN() OUTPUT
"winningPlan": {
"stage": "FETCH",
"inputStage": {
"stage": "OR",
inputStages": [
{
"stage": "IXSCAN",
"keyPattern": {"area": 1, "beds": 1},
"indexBounds": {"area": ["["Lake View", "Lake View"]"], "beds": ["[2, 2]"]}
},
{
"stage": "IXSCAN",
"keyPattern": {"el": 1, "beds": 1},
"indexBounds": {"el": ["["Red", "Red"]"], "beds": ["[2, 2]"]}}]}}](https://image.slidesharecdn.com/crystaladay11440-1520tessavitabileindexusagefornested-170621222900/85/Index-Usage-for-Nested-Logical-Queries-75-320.jpg)







![#MDBW17
OR-PUSHDOWNS: EXAMPLE #2
AND
AND AND
beds:
2
beds:
2
beds:
2
OR
area:
"Lake
View"
el:
"Red"
IXSCAN:
beds: [2, 2],
area: ["Lake View", "Lake View"]
beds: 1, area: 1
beds: 1, el: 1](https://image.slidesharecdn.com/crystaladay11440-1520tessavitabileindexusagefornested-170621222900/85/Index-Usage-for-Nested-Logical-Queries-83-320.jpg)
![#MDBW17
OR-PUSHDOWNS: EXAMPLE #2
AND
AND AND
beds:
2
beds:
2
beds:
2
OR
area:
"Lake
View"
el:
"Red"
IXSCAN:
beds: [2, 2],
area: ["Lake View", "Lake View"]
IXSCAN:
beds: [2, 2],
el: ["Red", "Red"]
beds: 1, area: 1
beds: 1, el: 1](https://image.slidesharecdn.com/crystaladay11440-1520tessavitabileindexusagefornested-170621222900/85/Index-Usage-for-Nested-Logical-Queries-84-320.jpg)
![#MDBW17
OR-PUSHDOWNS: EXAMPLE #2
AND
AND AND
beds:
2
beds:
2
beds:
2
OR
area:
"Lake
View"
el:
"Red"
IXSCAN:
beds: [2, 2],
area: ["Lake View", "Lake View"]
IXSCAN:
beds: [2, 2],
el: ["Red", "Red"]
OR
beds: 1, area: 1
beds: 1, el: 1](https://image.slidesharecdn.com/crystaladay11440-1520tessavitabileindexusagefornested-170621222900/85/Index-Usage-for-Nested-Logical-Queries-85-320.jpg)
![#MDBW17
OR-PUSHDOWNS: EXAMPLE #2
AND
AND AND
beds:
2
beds:
2
beds:
2
OR
area:
"Lake
View"
el:
"Red"
IXSCAN:
beds: [2, 2],
area: ["Lake View", "Lake View"]
IXSCAN:
beds: [2, 2],
el: ["Red", "Red"]
OR
FETCH:
filter: {beds: 2}
beds: 1, area: 1
beds: 1, el: 1](https://image.slidesharecdn.com/crystaladay11440-1520tessavitabileindexusagefornested-170621222900/85/Index-Usage-for-Nested-Logical-Queries-86-320.jpg)
![#MDBW17
OR-PUSHDOWNS: EXAMPLE #2
area: 1, beds: 1
el: 1, beds: 1
AND AND
beds:
2
beds:
2
OR
area:
"Lake
View"
el:
"Red"
IXSCAN:
beds: [2, 2],
area: ["Lake View", "Lake View"]
IXSCAN:
beds: [2, 2],
el: ["Red", "Red"]
OR
beds: 1, area: 1
beds: 1, el: 1](https://image.slidesharecdn.com/crystaladay11440-1520tessavitabileindexusagefornested-170621222900/85/Index-Usage-for-Nested-Logical-Queries-87-320.jpg)
![#MDBW17
.EXPLAIN() OUTPUT
"winningPlan": {
"stage": "FETCH",
"inputStage": {
"stage": "OR",
inputStages": [
{
"stage": "IXSCAN",
"keyPattern": {"beds": 1, "area": 1},
"indexBounds": {"beds": ["[2, 2]"], "area": ["["Lake View", "Lake View"]"]}
},
{
"stage": "IXSCAN",
"keyPattern": {"beds": 1, "el": 1},
"indexBounds": {"beds": ["[2, 2]"], "el": ["["Red", "Red"]"]}}]}}](https://image.slidesharecdn.com/crystaladay11440-1520tessavitabileindexusagefornested-170621222900/85/Index-Usage-for-Nested-Logical-Queries-88-320.jpg)







![#MDBW17
OR-PUSHDOWNS: NO REGRESSION
AND
AND AND
beds:
2
beds:
2
beds:
2
OR
area:
"Lake
View"
el:
"Red"
IXSCAN:
area: ["Lake View", "Lake View"]
area: 1
el: 1
beds: 1](https://image.slidesharecdn.com/crystaladay11440-1520tessavitabileindexusagefornested-170621222900/85/Index-Usage-for-Nested-Logical-Queries-96-320.jpg)
![#MDBW17
OR-PUSHDOWNS: NO REGRESSION
AND
AND
beds:
2
beds:
2
OR
area:
"Lake
View"
el:
"Red"
IXSCAN:
area: ["Lake View", "Lake View"]
area: 1
el: 1
beds: 1](https://image.slidesharecdn.com/crystaladay11440-1520tessavitabileindexusagefornested-170621222900/85/Index-Usage-for-Nested-Logical-Queries-97-320.jpg)
![#MDBW17
OR-PUSHDOWNS: NO REGRESSION
AND
AND
beds:
2
beds:
2
OR
area:
"Lake
View"
el:
"Red"
IXSCAN:
area: ["Lake View", "Lake View"]
IXSCAN:
el: ["Red", "Red"]
area: 1
el: 1
beds: 1](https://image.slidesharecdn.com/crystaladay11440-1520tessavitabileindexusagefornested-170621222900/85/Index-Usage-for-Nested-Logical-Queries-98-320.jpg)
![#MDBW17
OR-PUSHDOWNS: NO REGRESSION
AND
beds:
2
OR
area:
"Lake
View"
el:
"Red"
IXSCAN:
area: ["Lake View", "Lake View"]
IXSCAN:
el: ["Red", "Red"]
area: 1
el: 1
beds: 1](https://image.slidesharecdn.com/crystaladay11440-1520tessavitabileindexusagefornested-170621222900/85/Index-Usage-for-Nested-Logical-Queries-99-320.jpg)
![#MDBW17
OR-PUSHDOWNS: NO REGRESSION
AND
beds:
2
OR
area:
"Lake
View"
el:
"Red"
IXSCAN:
area: ["Lake View", "Lake View"]
IXSCAN:
el: ["Red", "Red"]
OR
area: 1
el: 1
beds: 1](https://image.slidesharecdn.com/crystaladay11440-1520tessavitabileindexusagefornested-170621222900/85/Index-Usage-for-Nested-Logical-Queries-100-320.jpg)
![#MDBW17
OR-PUSHDOWNS: NO REGRESSION
AND
beds:
2
OR
area:
"Lake
View"
el:
"Red"
IXSCAN:
area: ["Lake View", "Lake View"]
IXSCAN:
el: ["Red", "Red"]
OR
FETCH:
filter: {beds: 2}
area: 1
el: 1
beds: 1](https://image.slidesharecdn.com/crystaladay11440-1520tessavitabileindexusagefornested-170621222900/85/Index-Usage-for-Nested-Logical-Queries-101-320.jpg)
![#MDBW17
OR-PUSHDOWNS: NO REGRESSION
AND
beds:
2
OR
area:
"Lake
View"
el:
"Red"
IXSCAN:
area: ["Lake View", "Lake View"]
IXSCAN:
el: ["Red", "Red"]
OR
FETCH:
filter: {beds: 2}
AND
beds:
2
OR
area:
"Lake
View"
el:
"Red"
IXSCAN:
beds: [2, 2]
FETCH:
filter: {$or: [{area: "Lake View"}, {el: "Red"}]}
area: 1
el: 1
beds: 1](https://image.slidesharecdn.com/crystaladay11440-1520tessavitabileindexusagefornested-170621222900/85/Index-Usage-for-Nested-Logical-Queries-102-320.jpg)








Index Usage for Nested Logical Queries
- 1. #MDBW17 Tess Avitabile, MongoDB Software Engineer INDEX USAGE FOR NESTED LOGICAL QUERIES
- 2. #MDBW17 I AM THE LORAX I speak for the trees.
- 4. #MDBW17 QUERY SYSTEM {a: 1, $or: [{b: 1}, {c: 1}]}
- 5. #MDBW17 QUERY SYSTEM Parsing {a: 1, $or: [{b: 1}, {c: 1}]}
- 6. #MDBW17 QUERY SYSTEM Parsing {a: 1, $or: [{b: 1}, {c: 1}]} Plan Generation
- 7. #MDBW17 QUERY SYSTEM Parsing Plan Selection {a: 1, $or: [{b: 1}, {c: 1}]} Plan Generation
- 8. #MDBW17 QUERY SYSTEM Parsing Plan Selection Plan Execution {a: 1, $or: [{b: 1}, {c: 1}]} Plan Generation
- 9. #MDBW17 QUERY SYSTEM Plan Generation Parsing Plan Selection Plan Execution {a: 1, $or: [{b: 1}, {c: 1}]}
- 10. #MDBW17 DATASET: CHICAGO APARTMENTS { beds: 2, // 2-bedroom apartment area: "Lake View", // Lake View neighborhood el: "Red", // Red el line ... }
- 11. #MDBW17 WHAT IS A NESTED LOGICAL QUERY? {beds: 2, $or: [{area: "Lake View"}, {el: "Red"}]} AND OR beds: 2 area: "Lake View" el: "Red"
- 12. #MDBW17 An AND has an indexed solution when at least one child has an indexed solution. beds: 1 AND beds: 2 el: "Red" WHEN DOES A LOGICAL QUERY HAVE AN INDEXED SOLUTION?
- 13. #MDBW17 An AND has an indexed solution when at least one child has an indexed solution. beds: 1 IXSCAN: beds: [2, 2] AND beds: 2 el: "Red" WHEN DOES A LOGICAL QUERY HAVE AN INDEXED SOLUTION?
- 14. #MDBW17 An AND has an indexed solution when at least one child has an indexed solution. beds: 1 IXSCAN: beds: [2, 2] FETCH: filter: {el: "Red"} AND beds: 2 el: "Red" WHEN DOES A LOGICAL QUERY HAVE AN INDEXED SOLUTION?
- 15. #MDBW17 An OR has an indexed solution when all children have indexed solutions. OR area: "Lake View" el: "Red" WHEN DOES A LOGICAL QUERY HAVE AN INDEXED SOLUTION? area: 1 el: 1
- 16. #MDBW17 An OR has an indexed solution when all children have indexed solutions. OR area: "Lake View" el: "Red" WHEN DOES A LOGICAL QUERY HAVE AN INDEXED SOLUTION? area: 1 el: 1 IXSCAN: area: ["Lake View", "Lake View"]
- 17. #MDBW17 An OR has an indexed solution when all children have indexed solutions. OR area: "Lake View" el: "Red" WHEN DOES A LOGICAL QUERY HAVE AN INDEXED SOLUTION? area: 1 el: 1 IXSCAN: area: ["Lake View", "Lake View"] IXSCAN: el: ["Red", "Red"]
- 18. #MDBW17 An OR has an indexed solution when all children have indexed solutions. OR OR area: "Lake View" el: "Red" WHEN DOES A LOGICAL QUERY HAVE AN INDEXED SOLUTION? area: 1 el: 1 IXSCAN: area: ["Lake View", "Lake View"] IXSCAN: el: ["Red", "Red"]
- 19. #MDBW17 Index bounds are "tight" when all documents in the index bounds match the query. beds: 1, el: 1 AND beds: 2 el: "Red" WHEN ARE INDEX BOUNDS "TIGHT"?
- 20. #MDBW17 Index bounds are "tight" when all documents in the index bounds match the query. beds: 1, el: 1 IXSCAN: beds: [2, 2], el: [MinKey, MaxKey] AND beds: 2 el: "Red" WHEN ARE INDEX BOUNDS "TIGHT"?
- 21. #MDBW17 Index bounds are "tight" when all documents in the index bounds match the query. beds: 1, el: 1 IXSCAN: beds: [2, 2], el: [MinKey, MaxKey] FETCH: filter: {el: "Red"} AND beds: 2 el: "Red" WHEN ARE INDEX BOUNDS "TIGHT"?
- 22. #MDBW17 Index bounds are "tight" when all documents in the index bounds match the query. beds: 1, el: 1 IXSCAN: beds: [2, 2], el: [MinKey, MaxKey] FETCH: filter: {el: "Red"} AND beds: 2 el: "Red" WHEN ARE INDEX BOUNDS "TIGHT"? AND beds: 2 el: "Red"
- 23. #MDBW17 Index bounds are "tight" when all documents in the index bounds match the query. beds: 1, el: 1 IXSCAN: beds: [2, 2], el: [MinKey, MaxKey] FETCH: filter: {el: "Red"} AND beds: 2 el: "Red" WHEN ARE INDEX BOUNDS "TIGHT"? AND beds: 2 el: "Red" IXSCAN: beds: [2, 2], el: ["Red", "Red"]
- 24. #MDBW17 WHEN ARE INDEX BOUNDS "TIGHT"? "executionStats": { "nReturned": 10 "totalKeysExamined": 10000, "totalDocsExamined": 10000, "executionStages": { "stage": "FETCH", "filter": {"el": {"$eq" : "Red"}}, "nReturned": 10, "docsExamined": 10000, "inputStage": { "stage": "IXSCAN", "nReturned": 10000, "keyPattern": {"beds": 1, "el": 1}, "indexBounds": {"beds": ["[2.0, 2.0]"], "el": ["[MinKey, MaxKey]"]}, "keysExamined": 10000}}}
- 25. #MDBW17 WHEN ARE INDEX BOUNDS "TIGHT"? "executionStats": { "nReturned": 10 "totalKeysExamined": 10, "totalDocsExamined": 10, "executionStages": { "stage": "FETCH”, "nReturned": 10, "docsExamined": 10, "inputStage": { "stage": "IXSCAN", "nReturned": 10, "keyPattern": {"beds": 1, "el": 1}, "indexBounds": {"beds": ["[2.0, 2.0]"], "el": ["["Red", "Red"]"]}, "keysExamined": 10}}}
- 26. PROBLEM
- 27. #MDBW17 AND OR beds: 2 area: "Lake View" el: "Red" EXAMPLE #1 We do not get tight index bounds for an OR child because we do not use outside predicates to tighten bounds in a compound index. area: 1, beds: 1 el: 1, beds: 1
- 28. #MDBW17 IXSCAN: area: ["Lake View", "Lake View"], beds: [MinKey, MaxKey] AND OR beds: 2 area: "Lake View" el: "Red" EXAMPLE #1 We do not get tight index bounds for an OR child because we do not use outside predicates to tighten bounds in a compound index. area: 1, beds: 1 el: 1, beds: 1
- 29. #MDBW17 IXSCAN: el: ["Red", "Red"], beds: [MinKey, MaxKey] IXSCAN: area: ["Lake View", "Lake View"], beds: [MinKey, MaxKey] AND OR beds: 2 area: "Lake View" el: "Red" EXAMPLE #1 We do not get tight index bounds for an OR child because we do not use outside predicates to tighten bounds in a compound index. area: 1, beds: 1 el: 1, beds: 1
- 30. #MDBW17 IXSCAN: el: ["Red", "Red"], beds: [MinKey, MaxKey] IXSCAN: area: ["Lake View", "Lake View"], beds: [MinKey, MaxKey] AND OR beds: 2 area: "Lake View" el: "Red" OR EXAMPLE #1 We do not get tight index bounds for an OR child because we do not use outside predicates to tighten bounds in a compound index. area: 1, beds: 1 el: 1, beds: 1
- 31. #MDBW17 IXSCAN: el: ["Red", "Red"], beds: [MinKey, MaxKey] IXSCAN: area: ["Lake View", "Lake View"], beds: [MinKey, MaxKey] AND OR beds: 2 area: "Lake View" el: "Red" OR FETCH: filter: {beds: 2} EXAMPLE #1 We do not get tight index bounds for an OR child because we do not use outside predicates to tighten bounds in a compound index. area: 1, beds: 1 el: 1, beds: 1
- 32. #MDBW17 .EXPLAIN() OUTPUT "winningPlan": { "stage": "FETCH", "filter": {"beds": {"$eq" : 2}}, "inputStage": { "stage": "OR", inputStages": [ { "stage": "IXSCAN", "keyPattern": {"area": 1, "beds": 1}, "indexBounds": {"area": ["["Lake View", "Lake View"]"], "beds": ["[MinKey, MaxKey]"]} }, { "stage": "IXSCAN", "keyPattern": {"el": 1, "beds": 1}, "indexBounds": {"el": ["["Red", "Red"]"], "beds": ["[MinKey, MaxKey]"]}}]}}
- 33. #MDBW17 7 KNOWN CUSTOMER SUPPORT CASES
- 34. #MDBW17 AND OR beds: 2 area: "Lake View" el: "Red" EXAMPLE #2 An OR child cannot have an indexed solution because we do not use an outside predicate to fulfill the first position in a compound index. beds: 1, area: 1 beds: 1, el: 1
- 35. #MDBW17 IXSCAN: beds: [2, 2], area: [MinKey, MaxKey] AND OR beds: 2 area: "Lake View" el: "Red" EXAMPLE #2 An OR child cannot have an indexed solution because we do not use an outside predicate to fulfill the first position in a compound index. beds: 1, area: 1 beds: 1, el: 1
- 36. #MDBW17 IXSCAN: beds: [2, 2], area: [MinKey, MaxKey] AND OR beds: 2 area: "Lake View" el: "Red" FETCH: filter: {$or: [{area: "Lake View"}, {el: "Red"}]} EXAMPLE #2 An OR child cannot have an indexed solution because we do not use an outside predicate to fulfill the first position in a compound index. beds: 1, area: 1 beds: 1, el: 1
- 37. #MDBW17 .EXPLAIN() OUTPUT "winningPlan": { "stage": "FETCH", "filter": {$or": [{"area": {"$eq": "Lake View"}}, {"el": {"$eq": "Red"}}]}, "inputStage": { "stage": "IXSCAN", "keyPattern": {"beds": 1, "area": 1}, "indexBounds": {"beds": ["[2.0, 2.0]"], "area": ["[MinKey, MaxKey]"]}}}
- 38. #MDBW17 6 KNOWN CUSTOMER SUPPORT CASES
- 40. #MDBW17 AND beds: 2 OR DISJUNCTIVE NORMAL FORM area: "Lake View" el: "Red" OR AND AND area: "Lake View" el: "Red" beds: 2 beds: 2
- 41. #MDBW17 DISJUNCTIVE NORMAL FORM OR AND AND beds: 2 beds: 2 area: "Lake View" el: "Red" area: 1, beds: 1 el: 1, beds: 1 Fixed!
- 42. #MDBW17 DISJUNCTIVE NORMAL FORM OR AND AND beds: 2 beds: 2 area: "Lake View" el: "Red" area: 1, beds: 1 el: 1, beds: 1 IXSCAN: area: ["Lake View", "Lake View"], beds: [2, 2] Fixed!
- 43. #MDBW17 DISJUNCTIVE NORMAL FORM OR AND AND beds: 2 beds: 2 area: "Lake View" el: "Red" area: 1, beds: 1 el: 1, beds: 1 IXSCAN: area: ["Lake View", "Lake View"], beds: [2, 2] IXSCAN: el: ["Red", "Red"], beds: [2, 2] Fixed!
- 44. #MDBW17 DISJUNCTIVE NORMAL FORM OR AND AND beds: 2 beds: 2 area: "Lake View" el: "Red" area: 1, beds: 1 el: 1, beds: 1 IXSCAN: area: ["Lake View", "Lake View"], beds: [2, 2] IXSCAN: el: ["Red", "Red"], beds: [2, 2] OR Fixed!
- 45. #MDBW17 DISJUNCTIVE NORMAL FORM OR AND AND beds: 2 beds: 2 area: "Lake View" el: "Red" area: 1, beds: 1 el: 1, beds: 1 IXSCAN: area: ["Lake View", "Lake View"], beds: [2, 2] IXSCAN: el: ["Red", "Red"], beds: [2, 2] OR Fixed!
- 46. #MDBW17 DISJUNCTIVE NORMAL FORM area: 1 el: 1 beds: 1 AND beds: 2 OR area: "Lake View" el: "Red"
- 47. #MDBW17 DISJUNCTIVE NORMAL FORM area: 1 el: 1 beds: 1 Previously… AND beds: 2 OR area: "Lake View" el: "Red"
- 48. #MDBW17 DISJUNCTIVE NORMAL FORM area: 1 el: 1 beds: 1 Previously… AND beds: 2 OR area: "Lake View" el: "Red" IXSCAN: beds: [2, 2]
- 49. #MDBW17 DISJUNCTIVE NORMAL FORM area: 1 el: 1 beds: 1 Previously… AND beds: 2 OR area: "Lake View" el: "Red" IXSCAN: beds: [2, 2] FETCH: filter: {$or: [{area: "Lake View"}, {el: "Red"}]}
- 50. #MDBW17 DISJUNCTIVE NORMAL FORM AND beds: 2 OR area: "Lake View" el: "Red" area: 1 el: 1 beds: 1 AND beds: 2 OR area: "Lake View" el: "Red" IXSCAN: beds: [2, 2] FETCH: filter: {$or: [{area: "Lake View"}, {el: "Red"}]} Previously…
- 51. #MDBW17 DISJUNCTIVE NORMAL FORM AND beds: 2 OR area: "Lake View" el: "Red" area: 1 el: 1 beds: 1 IXSCAN: area: ["Lake View", "Lake View"] AND beds: 2 OR area: "Lake View" el: "Red" IXSCAN: beds: [2, 2] FETCH: filter: {$or: [{area: "Lake View"}, {el: "Red"}]} Previously…
- 52. #MDBW17 DISJUNCTIVE NORMAL FORM AND beds: 2 OR area: "Lake View" el: "Red" area: 1 el: 1 beds: 1 IXSCAN: area: ["Lake View", "Lake View"] IXSCAN: el: ["Red", "Red"] AND beds: 2 OR area: "Lake View" el: "Red" IXSCAN: beds: [2, 2] FETCH: filter: {$or: [{area: "Lake View"}, {el: "Red"}]} Previously…
- 53. #MDBW17 DISJUNCTIVE NORMAL FORM AND beds: 2 OR area: "Lake View" el: "Red" area: 1 el: 1 beds: 1 IXSCAN: area: ["Lake View", "Lake View"] IXSCAN: el: ["Red", "Red"] OR AND beds: 2 OR area: "Lake View" el: "Red" IXSCAN: beds: [2, 2] FETCH: filter: {$or: [{area: "Lake View"}, {el: "Red"}]} Previously…
- 54. #MDBW17 DISJUNCTIVE NORMAL FORM AND beds: 2 OR area: "Lake View" el: "Red" area: 1 el: 1 beds: 1 IXSCAN: area: ["Lake View", "Lake View"] IXSCAN: el: ["Red", "Red"] OR FETCH: filter: {beds: 2} AND beds: 2 OR area: "Lake View" el: "Red" IXSCAN: beds: [2, 2] FETCH: filter: {$or: [{area: "Lake View"}, {el: "Red"}]} Previously…
- 55. #MDBW17 DISJUNCTIVE NORMAL FORM • Exponential explosion of plans. Regression … area: 1 el: 1 beds: 1 OR OR OR OR AND AND AND AND AND AND AND AND beds: 2 beds: 2 beds: 2 beds: 2 beds: 2 beds: 2 beds: 2 beds: 2 el: "Red" el: "Red" el: "Red" el: "Red" area: "Lake View" area: "Lake View" area: "Lake View" area: "Lake View"
- 56. #MDBW17 DISJUNCTIVE NORMAL FORM • Exponential explosion of plans. • We may lose the best plan. Regression … area: 1 el: 1 beds: 1 OR OR OR OR AND AND AND AND AND AND AND AND beds: 2 beds: 2 beds: 2 beds: 2 beds: 2 beds: 2 beds: 2 beds: 2 el: "Red" el: "Red" el: "Red" el: "Red" area: "Lake View" area: "Lake View" area: "Lake View" area: "Lake View" AND ORbeds: 2 area: "Lake View" el: "Red" AND ORbeds: 2 area: "Lake View" el: "Red" versus
- 58. #MDBW17 OR-PUSHDOWNS Predicates are pulled up to the AND parent and pushed down into the OR children if they can be used to tighten index bounds.
- 59. #MDBW17 OR-PUSHDOWNS Predicates are pulled up to the AND parent and pushed down into the OR children if they can be used to tighten index bounds.
- 60. #MDBW17 OR-PUSHDOWNS Predicates are pulled up to the AND parent and pushed down into the OR children if they can be used to tighten index bounds.
- 61. #MDBW17 OR-PUSHDOWNS Predicates are pulled up to the AND parent and pushed down into the OR children if they can be used to tighten index bounds.
- 62. #MDBW17 OR-PUSHDOWNS Predicates are pulled up to the AND parent and pushed down into the OR children if they can be used to tighten index bounds.
- 63. #MDBW17 OR-PUSHDOWNS Predicates are pulled up to the AND parent and pushed down into the OR children if they can be used to tighten index bounds.
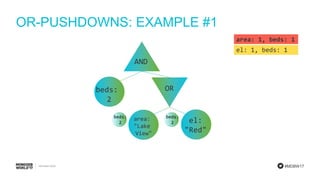
- 64. #MDBW17 OR-PUSHDOWNS: EXAMPLE #1 area: 1, beds: 1 el: 1, beds: 1 AND ORbeds: 2 area: "Lake View" el: "Red"
- 65. #MDBW17 OR-PUSHDOWNS: EXAMPLE #1 area: 1, beds: 1 el: 1, beds: 1 AND ORbeds: 2 area: "Lake View" el: "Red" beds: 2
- 66. #MDBW17 OR-PUSHDOWNS: EXAMPLE #1 area: 1, beds: 1 el: 1, beds: 1 AND ORbeds: 2 area: "Lake View" el: "Red" beds: 2
- 67. #MDBW17 OR-PUSHDOWNS: EXAMPLE #1 area: 1, beds: 1 el: 1, beds: 1 AND ORbeds: 2 area: "Lake View" el: "Red" beds: 2
- 68. #MDBW17 OR-PUSHDOWNS: EXAMPLE #1 area: 1, beds: 1 el: 1, beds: 1 AND ORbeds: 2 area: "Lake View" el: "Red" beds: 2 beds: 2
- 69. #MDBW17 OR-PUSHDOWNS: EXAMPLE #1 area: 1, beds: 1 el: 1, beds: 1 AND AND AND beds: 2 beds: 2 beds: 2 OR area: "Lake View" el: "Red"
- 70. #MDBW17 OR-PUSHDOWNS: EXAMPLE #1 area: 1, beds: 1 el: 1, beds: 1 AND AND AND beds: 2 beds: 2 beds: 2 OR area: "Lake View" el: "Red" IXSCAN: area: ["Lake View", "Lake View"], beds: [2, 2]
- 71. #MDBW17 OR-PUSHDOWNS: EXAMPLE #1 area: 1, beds: 1 el: 1, beds: 1 AND AND AND beds: 2 beds: 2 beds: 2 OR area: "Lake View" el: "Red" IXSCAN: area: ["Lake View", "Lake View"], beds: [2, 2] IXSCAN: el: ["Red", "Red"], beds: [2, 2]
- 72. #MDBW17 OR-PUSHDOWNS: EXAMPLE #1 area: 1, beds: 1 el: 1, beds: 1 AND AND AND beds: 2 beds: 2 beds: 2 OR area: "Lake View" el: "Red" IXSCAN: area: ["Lake View", "Lake View"], beds: [2, 2] IXSCAN: el: ["Red", "Red"], beds: [2, 2] OR
- 73. #MDBW17 OR-PUSHDOWNS: EXAMPLE #1 area: 1, beds: 1 el: 1, beds: 1 AND AND AND beds: 2 beds: 2 beds: 2 OR area: "Lake View" el: "Red" IXSCAN: area: ["Lake View", "Lake View"], beds: [2, 2] IXSCAN: el: ["Red", "Red"], beds: [2, 2] OR FETCH: filter: {beds: 2}
- 74. #MDBW17 OR-PUSHDOWNS: EXAMPLE #1 area: 1, beds: 1 el: 1, beds: 1 AND AND beds: 2 beds: 2 OR area: "Lake View" el: "Red" IXSCAN: area: ["Lake View", "Lake View"], beds: [2, 2] IXSCAN: el: ["Red", "Red"], beds: [2, 2] OR
- 75. #MDBW17 .EXPLAIN() OUTPUT "winningPlan": { "stage": "FETCH", "inputStage": { "stage": "OR", inputStages": [ { "stage": "IXSCAN", "keyPattern": {"area": 1, "beds": 1}, "indexBounds": {"area": ["["Lake View", "Lake View"]"], "beds": ["[2, 2]"]} }, { "stage": "IXSCAN", "keyPattern": {"el": 1, "beds": 1}, "indexBounds": {"el": ["["Red", "Red"]"], "beds": ["[2, 2]"]}}]}}
- 77. #MDBW17 OR-PUSHDOWNS: EXAMPLE #2 beds: 1, area: 1 beds: 1, el: 1 AND ORbeds: 2 area: "Lake View" el: "Red"
- 78. #MDBW17 OR-PUSHDOWNS: EXAMPLE #2 AND ORbeds: 2 area: "Lake View" el: "Red" beds: 2 beds: 1, area: 1 beds: 1, el: 1
- 79. #MDBW17 OR-PUSHDOWNS: EXAMPLE #2 AND ORbeds: 2 area: "Lake View" el: "Red" beds: 2 beds: 1, area: 1 beds: 1, el: 1
- 80. #MDBW17 OR-PUSHDOWNS: EXAMPLE #2 AND ORbeds: 2 area: "Lake View" el: "Red" beds: 2 beds: 1, area: 1 beds: 1, el: 1
- 81. #MDBW17 OR-PUSHDOWNS: EXAMPLE #2 AND ORbeds: 2 area: "Lake View" el: "Red" beds: 2 beds: 2 beds: 1, area: 1 beds: 1, el: 1
- 82. #MDBW17 OR-PUSHDOWNS: EXAMPLE #2 AND AND AND beds: 2 beds: 2 beds: 2 OR area: "Lake View" el: "Red" beds: 1, area: 1 beds: 1, el: 1
- 83. #MDBW17 OR-PUSHDOWNS: EXAMPLE #2 AND AND AND beds: 2 beds: 2 beds: 2 OR area: "Lake View" el: "Red" IXSCAN: beds: [2, 2], area: ["Lake View", "Lake View"] beds: 1, area: 1 beds: 1, el: 1
- 84. #MDBW17 OR-PUSHDOWNS: EXAMPLE #2 AND AND AND beds: 2 beds: 2 beds: 2 OR area: "Lake View" el: "Red" IXSCAN: beds: [2, 2], area: ["Lake View", "Lake View"] IXSCAN: beds: [2, 2], el: ["Red", "Red"] beds: 1, area: 1 beds: 1, el: 1
- 85. #MDBW17 OR-PUSHDOWNS: EXAMPLE #2 AND AND AND beds: 2 beds: 2 beds: 2 OR area: "Lake View" el: "Red" IXSCAN: beds: [2, 2], area: ["Lake View", "Lake View"] IXSCAN: beds: [2, 2], el: ["Red", "Red"] OR beds: 1, area: 1 beds: 1, el: 1
- 86. #MDBW17 OR-PUSHDOWNS: EXAMPLE #2 AND AND AND beds: 2 beds: 2 beds: 2 OR area: "Lake View" el: "Red" IXSCAN: beds: [2, 2], area: ["Lake View", "Lake View"] IXSCAN: beds: [2, 2], el: ["Red", "Red"] OR FETCH: filter: {beds: 2} beds: 1, area: 1 beds: 1, el: 1
- 87. #MDBW17 OR-PUSHDOWNS: EXAMPLE #2 area: 1, beds: 1 el: 1, beds: 1 AND AND beds: 2 beds: 2 OR area: "Lake View" el: "Red" IXSCAN: beds: [2, 2], area: ["Lake View", "Lake View"] IXSCAN: beds: [2, 2], el: ["Red", "Red"] OR beds: 1, area: 1 beds: 1, el: 1
- 88. #MDBW17 .EXPLAIN() OUTPUT "winningPlan": { "stage": "FETCH", "inputStage": { "stage": "OR", inputStages": [ { "stage": "IXSCAN", "keyPattern": {"beds": 1, "area": 1}, "indexBounds": {"beds": ["[2, 2]"], "area": ["["Lake View", "Lake View"]"]} }, { "stage": "IXSCAN", "keyPattern": {"beds": 1, "el": 1}, "indexBounds": {"beds": ["[2, 2]"], "el": ["["Red", "Red"]"]}}]}}
- 90. #MDBW17 OR-PUSHDOWNS: NO REGRESSION AND ORbeds: 2 area: "Lake View" el: "Red" area: 1 el: 1 beds: 1
- 91. #MDBW17 OR-PUSHDOWNS: NO REGRESSION AND ORbeds: 2 area: "Lake View" el: "Red" beds: 2 area: 1 el: 1 beds: 1
- 92. #MDBW17 OR-PUSHDOWNS: NO REGRESSION AND ORbeds: 2 area: "Lake View" el: "Red" beds: 2 area: 1 el: 1 beds: 1
- 93. #MDBW17 OR-PUSHDOWNS: NO REGRESSION AND ORbeds: 2 area: "Lake View" el: "Red" beds: 2 area: 1 el: 1 beds: 1
- 94. #MDBW17 OR-PUSHDOWNS: NO REGRESSION AND ORbeds: 2 area: "Lake View" el: "Red" beds: 2 beds: 2 area: 1 el: 1 beds: 1
- 95. #MDBW17 OR-PUSHDOWNS: NO REGRESSION AND AND AND beds: 2 beds: 2 beds: 2 OR area: "Lake View" el: "Red" area: 1 el: 1 beds: 1
- 96. #MDBW17 OR-PUSHDOWNS: NO REGRESSION AND AND AND beds: 2 beds: 2 beds: 2 OR area: "Lake View" el: "Red" IXSCAN: area: ["Lake View", "Lake View"] area: 1 el: 1 beds: 1
- 97. #MDBW17 OR-PUSHDOWNS: NO REGRESSION AND AND beds: 2 beds: 2 OR area: "Lake View" el: "Red" IXSCAN: area: ["Lake View", "Lake View"] area: 1 el: 1 beds: 1
- 98. #MDBW17 OR-PUSHDOWNS: NO REGRESSION AND AND beds: 2 beds: 2 OR area: "Lake View" el: "Red" IXSCAN: area: ["Lake View", "Lake View"] IXSCAN: el: ["Red", "Red"] area: 1 el: 1 beds: 1
- 99. #MDBW17 OR-PUSHDOWNS: NO REGRESSION AND beds: 2 OR area: "Lake View" el: "Red" IXSCAN: area: ["Lake View", "Lake View"] IXSCAN: el: ["Red", "Red"] area: 1 el: 1 beds: 1
- 100. #MDBW17 OR-PUSHDOWNS: NO REGRESSION AND beds: 2 OR area: "Lake View" el: "Red" IXSCAN: area: ["Lake View", "Lake View"] IXSCAN: el: ["Red", "Red"] OR area: 1 el: 1 beds: 1
- 101. #MDBW17 OR-PUSHDOWNS: NO REGRESSION AND beds: 2 OR area: "Lake View" el: "Red" IXSCAN: area: ["Lake View", "Lake View"] IXSCAN: el: ["Red", "Red"] OR FETCH: filter: {beds: 2} area: 1 el: 1 beds: 1
- 102. #MDBW17 OR-PUSHDOWNS: NO REGRESSION AND beds: 2 OR area: "Lake View" el: "Red" IXSCAN: area: ["Lake View", "Lake View"] IXSCAN: el: ["Red", "Red"] OR FETCH: filter: {beds: 2} AND beds: 2 OR area: "Lake View" el: "Red" IXSCAN: beds: [2, 2] FETCH: filter: {$or: [{area: "Lake View"}, {el: "Red"}]} area: 1 el: 1 beds: 1
- 103. #MDBW17
- 104. TAKE-AWAYS
- 105. #MDBW17 TAKE-AWAYS
- 106. #MDBW17 TAKE-AWAYS • Only add plans, don’t subtract.
- 107. #MDBW17 TAKE-AWAYS • Only add plans, don’t subtract. • Do your research first.
- 108. #MDBW17 TAKE-AWAYS • Only add plans, don’t subtract. • Do your research first. • You can use your knowledge of the query planner to ensure queries will utilize indexes.
- 109. #MDBW17 TAKE-AWAYS • Only add plans, don’t subtract. • Do your research first. • You can use your knowledge of the query planner to ensure queries will utilize indexes. • In MongoDB 3.6, we do a better job of finding indexed solutions for nested logical queries!
Editor's Notes
- #2: You will learn what a nested logical query is. You will learn why it’s challenging to get tight index bounds for nested logical queries. You will hear how this created a problem for customers in the real world. You will see how we solved this problem using tree algorithms. Throughout the course of the talk, you will learn a lot about the internals of the query planner. This will give you a better understanding of when your queries are fully utilizing indexes.
- #3: The reason I was so excited to not only do this project, but also give this talk, is that I was one of those people in college who loved algorithms classes and recursion, but I never imagined you would use these things in the real world. It was amazing to see that we call solve a real-world problem by performing recursive manipulations of trees.
- #4: First let me give you an overview of the query system, so that we can zoom in on the part of the query system we’re going to discuss today. The query team owns the whole process from when a query comes in, to when the results are returned back to the user.
- #5: First a query comes in as BSON.
- #6: We parse it into an abstract syntax tree, where ANDs and ORs become internal nodes, and predicates become leaf nodes.
- #7: Next we generate all possible plans for this query. A plan here is a tagging of leaf nodes with which indexes can be used to answer the predicate.
- #8: Then we do plan selection, where we take each of the plans we generated and run the for a trial period. We pick the plan that produced the most results in the trial period.
- #9: Then we execute the winning plan until it’s done and return all the results to the user.
- #10: The problem we’re going to talk about today is in Plan Generation. Essentially we were failing to generate the best possible plan, and if we don’t generate the best plan in Plan Generation, we can’t pick the best plan in Plan Selection.
- #12: A nested logical query just means that we have ORs inside of ANDs or ANDs inside of ORs. However, the difficult case for us is when we have ORs inside of ANDs, so that’s what we’re going to focus on for this talk. Nested logical queries come up all the time. [Explain apartment example.] [Explain view example.]
- #13: By indexed solution, I mean that we can find the documents to return using index scans. That is, we don’t have to do a full collection scan and check whether each document in the collection matches the query. A nested logical query can be an arbitrarily nested tree of ANDs and ORs, but there are just two base cases to consider, and from there, we can tell whether the whole query has an indexed solution. We’ll start with AND. An AND has an indexed solution when at least one child has an indexed solution. The index catalog is on the right. We have an index on the field ‘beds’ in increasing order.
- #14: When the query planner recursively visits this tree, it will see that it can answer the predicate in the left child of the AND using an index scan on the blue index, with index bounds ‘beds’ from 2 to 2.
- #15: Then to answer the AND, it can add a FETCH with a filter for the predicate {el: “Red”}.
- #16: An OR has an indexed solution when all children have indexed solutions. Here we have two indexes, on the fields ‘area’ and ‘el’.
- #17: When the query planner recursively visits this tree, it will see that it can answer the predicate in the left child of the OR using an index scan on the red index, with index bounds ‘area’ from “Lake View” to “Lake View”.
- #18: When the query planner recursively visits this tree, it will see that it can answer the predicate in the right child of the OR using an index scan on the yellow index, with index bounds ‘el’ from “Red” to “Red.
- #19: Then to answer the OR, it needs to output each document from the two index scans, without output the same document twice. It can do this by storing the RecordIDs of the documents it outputs in a hash set, and checking whether it’s already output a document before returning it. This deduplication process is called an OR stage. Why is it important that all children of an OR have an indexed solution? If only the left child had an indexed solution, then we have all of the “Lake View” documents, but we still need all of the Red line documents that are not in Lake View. The only we to get that is by a collection scan. And once we’re doing a collection scan for part of the query, we might as well do a collection scan for the whole query.
- #20: I said it was challenging to get “tight index bounds” for nested logical queries, but what exactly does “tight index bounds” mean? We say that index bounds are “tight” when all documents in the index bounds are guaranteed to match the query and be returned to the user. Here we have an AND query and a compound index the fields ‘beds’, ‘el’. Let’s look at two possible plans for this query.
- #21: We could answer the left child with an index scan on the blue index with bounds ‘beds’ from 2 to 2, and ‘el’ from MinKey to MaxKey. This means that we do not constrain the value of ‘el’ at all in our index scan.
- #22: Then to answer the AND, we can add a FETCH with a filter {el: “Red”}.
- #23: Another plan…
- #24: We can answer the entire AND using an index scan on the blue index with bounds ‘beds’ from 2 to 2 and ‘el’ from ‘Red’ to ‘Red’. Which plan do you think is better? The plan on the left examines far more documents than it needs to. It looks at all the 2 bedroom apartments, then filters down to those on the Red line, whereas the plan on the right only examines the 2 bedroom apartments on the Red line. We say that the plan on the right has “tight index bounds”.
- #25: Let’s look at the explain output for the plan on the left. [If you want to learn more about explain plans, go to Charlie’s talk at 4:20 today in Crystal C.] It performs an index scan for all 2 bedroom apartments, with no constraint on the value of ‘el’. There might be 10000 such apartments. Then it uses a a FETCH with a filter {el: “Red”} to filter down to only 10 apartments. And 10000 was arbitrary, it could be 100000, or a million…
- #26: Here is the explain plan for the plan on the right. It only scans for 2 bedroom apartments on the Red line, so the index scan gets exactly the 10 documents that it wants.
- #27: Putting it all together, the problem that we’re going to talk about is that in MongoDB 3.4, we sometimes fail to get tight index bounds for nested logical queries.
- #28: There are two examples I would like to look at. In the first example, we do not get tight index bounds for an OR child because we do not use outside predicates to tighten bounds in a compound index. We have two compound indexes, one on ‘area’ followed by ‘beds’, the other on ‘el’ followed by ‘beds’.
- #29: When the query planner recursively visits this query, it will see that it can answer the left child of the OR using an index scan on the red index with bounds ‘area’ from ‘Lake View’ to ‘Lake View’ and ‘beds’ from MinKey to MaxKey. It can’t constrain the bounds on ‘beds’ because it doesn’t know about the predicate {beds: 2}.
- #30: It can answer the right child of the OR using an index scan on the yellow index with bounds ‘el’ from ‘Red’ to ‘Red’ and ‘beds’ from MinKey to MaxKey. Similarly, it can’t constrain the bounds on ‘beds’.
- #31: Then to answer the OR, it can use an OR stage to deduplicate the documents from these two index scans, as we discussed.
- #32: Then to answer the whole query, we add a FETCH with a filter on {beds: 2}. So this plan does not have tight index bounds. We look at all the apartments in Lake View or on the Red line, and then filter down to just the two bedroom apartments.
- #33: If you run explain on this query with this set of indexes on MongoDB 3.4, this is exactly the plan you will see. We have two index scans, on {area: 1, beds: 1}, and {el: 1, beds: 1}, where the bounds on beds go from MinKey to MaxKey.
- #34: This problem comes up in the real world. We know of at least 7 customers who have run into exactly this issue. There are probably a lot more—these are just the 7 that a friendly support engineer pulled up as motivation for this project. And many people may not even know they are running into this issue because they might not know that they could have a query that be faster. Possibly someone in the room has run into this issue.
- #35: The second example looks similar, but is subtly different. We have the same query, but we have reversed the order of the fields in the compound indexes. Here an OR *cannot* have an indexed solution because we do not use an outside predicate to fulfill the first position in a compound index.
- #36: When the query planner visits the children of the OR, it can’t uses indexes to answer them, because it doesn’t have bounds on the first field in the index. Instead, it can answer the left child of the AND using the red index with bounds ‘beds’ from 2 to 2 and area from MinKey to MaxKey. I picked red here, but it could also use the yellow index.
- #37: Then to answer the AND, it adds a FETCH with the entire OR predicate as a filter. So it looks at ALL the two bedroom apartments in Chicago, then narrows down to just those in Lake View or on the Red line.
- #38: If you run explain on this query with these indexes on MongoDB 3.4, this is exactly what you’ll see. We have a single index scan, on {beds: 1, area: 1}, with ‘beds’ from 2 to 2 and no constraint on ‘area’, then we filter down to just the documents with {area: “Lake View”} or {el: “Red”}.
- #39: And our friendly support engineer easily found 6 customers who have run into this particular issue. So now we have 13 unhappy customers with slow queries! But don’t worry, we’ll get back to them.
- #40: We encountered this issue a few years ago. In trying to solve it, we thought, “Okay, we are computer scientists. We know what to do with boolean formulas. Let’s try to put the query in a normal form so that we can get predictable query planning.” We decided to use disjunctive normal form, which is just a fancy way to say an OR of ANDs.
- #41: To transform the query into disjuntive normal form, we take each predicate child of the AND and we AND it with each child of the OR.
- #42: Let’s see whether this fixed the problem. We’ve transformed the query into disjunctive normal form. We have the two compound indexes {area: 1, beds: 1}, and {el: 1, beds: 1}. Previously, we failed to get tight index bounds for this query.
- #43: When the query planner visits the first AND, it sees that it can answer this AND with an index scan on the red index with bounds ‘area’ from ‘Lake View’ to ‘Lake View’ and beds from 2 to 2. It can use the predicate {beds: 2}, because it’s right there.
- #44: Similarly, it can answer the right AND with an index scan on the yellow index with bounds ‘el’ from ‘Red’ to ‘Red’ and ‘beds’ from 2 to 2.
- #45: To answer the whole query, it can add an OR stage to deduplicate the results from the two children.
- #46: So we fixed it! We achieved tight index bounds for this query. But you’ve probably guessed that we haven’t fixed it, since I’m only halfway through my talk.
- #47: While we’ve fixed that query, we’ve introduced a regression in a different query. This is the same query, but I’ve changed the indexes. Instead of compound indexes, we just have an index on each field.
- #48: This is how the query planner used to work on this query. We did not transform it into disjunctive normal form.
- #49: When the query planner visits {beds: 2}, it can answer it with the blue index with bounds 2 to 2.
- #50: Then to answer the whole query, it adds a FETCH with a filter on the OR predicate.
- #51: In another branch of the recursion…
- #52: We can answer {area: “Lake View”} using the red index with bounds ‘area’ from ‘Lake View’ to ‘Lake View’.
- #53: We can answer {el: “Red”} using the yellow index with bounds ‘el’ from ‘Red’ to ‘Red’.
- #54: We can answer the OR using an OR stage.
- #55: Then we can answer the entire query by adding a FETCH with the filter {beds: 2}.
- #56: However, when we transform this query into disjuntive normal form, we get an exponential explosion of plans. Essentially, now we have two choices for indexing each child of the AND: the original predicate and the predicate {beds: 2} that we pulled in. Then if the OR has n children, we get 2^n plans.
- #57: And worse yet, we may lose the best plan. Suppose the best plan was the top right plan, which does a single index scan on the blue index. Every plan on the left that uses the blue index also does a second index scan, so it performs strictly more work. On the query team, we cannot cause regressions. If a customer upgrades to the latest version and suddenly one of their queries has worse performance, then they have to downgrade, which is a big hassle.
- #58: So, when it was clear that approach would cause a regression in some queries, we reverted the change and put this project on the back burner. In the meantime, we did a lot of other really cool stuff! We brought you collation, faceting, $lookup, $graphLookup, lots of great features. Finally this year we had the time to pick up the project again. My tech lead told me, just take the month of January and work on this and see what you can come up with. In coming up with an approach, I knew I couldn’t change lose any query plans, so I couldn’t change the shape of the query. So I thought back to the real problem we are trying to solve. We want to be able to use predicates outside of an OR to tighten index bounds or fulfill the first index position for children of the OR. So I set out to do exactly that. We call this solution Or-Pushdowns.
- #59: In the Or-Pushdown solution, predicates are pulled up to the AND parent, then pushed down into the OR children to be available to tighten index bounds or fulfill the first position in the index.
- #60: This predicate gets pulled out, let’s call it a “ghost predicate”…
- #61: It gets pulled up to its AND parent…
- #62: Then pushed down into the OR…
- #63: And each of the OR children…
- #64: Where it’s made available to tighten index bounds or fulfill the first position in the index. These ghost predicates are really just extra pieces of information that the query planner is carrying around as it recursively visits the tree. It’s remembering the predicates outside the OR so that they can be used inside the OR.
- #65: Let’s see this in action. This is our example of a nested logical query where we were not getting tight index bounds on the second fields in the compound indexes.
- #66: We create a ghost predicate for {beds: 2}.
- #67: We pull it up into its AND parent.
- #68: Then push it down into the OR.
- #69: And each of the OR’s children.
- #70: Where it’s made available to tighten index bounds.
- #71: We can answer the left child of the OR using the red index with bounds ‘area’ from ‘Lake View’ to ‘Lake View’ and ‘beds’ from 2 to 2. Since we used the ghost predicate to tighten index bounds, we leave it where it is.
- #72: We can answer the right child with an index scan on the yellow index with bounds ‘el’ from ‘Red’ to ‘Red’ and ‘beds’ from 2 to 2. Since the ghost predicate was useful, we leave it.
- #73: We can answer the OR using an OR stage.
- #74: Then we can answer the entire query by adding a FETCH with a filter on {beds: 2}. So we got tight index bounds for the query. But wait, we can do better. Do you see how? We don’t need the filter {beds: 2} because we know that every document coming out of the OR will satisfy {beds: 2}.
- #75: When that’s the case, when each child of the OR uses the ghost predicate, we remove the filter.
- #76: And if you download the latest development release, and run explain on this query, this is exactly what you’ll see. We do two index scans on {area: 1, beds: 1} and {el: 1, beds: 1}, with tight index bounds.
- #77: And we’ve made 7 customers happy! Or, we will when MongoDB 3.6 is released.
- #78: Let’s look at our second example. In this example, we were not able to get an indexed solution for the OR, because we could not use outside predicates to fulfill the first position in the compound indexes.
- #91: But let’s not get too excited, since last time we thought we had solved the problem too, when we put the query in disjunctive normal form. So let’s check the case where we saw a regression. Here we have an index on each field.
- #97: We answer the left child of the OR using the red index with bounds ‘area’ from ‘Lake View’ to ‘Lake View’.
- #98: Since we did not use the ghost predicate {beds: 2}, we remove it.
- #99: We can answer the right child of the OR using the yellow index with bounds ‘el’ from ‘Red’ to ‘Red’.
- #100: Since we did not use the ghost predicate {beds: 2}, we remove it. And we don’t consider index scans that use only the {beds: 2} predicate.
- #103: Through another branch of the recursion, we get the plan on the left using the blue index.
- #104: We have no regression! Moreover, we know that we won’t have a regression, because this approach does not take away any plans—it only adds a very targeted set of plans that we were missing.
- #105: We have some take-aways for us on the query team, and some take-aways for you.
- #107: By subtracting plans, we may lose the best plan and cause a regression. We keep the original query shape, so that we don’t lose any plans, but we make predicates available throughout the tree for tightening index bounds and fulfilling the first position in the index.
- #108: When the implementation was almost complete, I found this paper, Query Optimization by Predicate Move-Around, which contains the essence of the or-pushdown solution. While that gives a nice theoretical basis to our work, finding the paper earlier could have saved time in the design. However, the paper contains a lot of other good material, that may be helpful for aggregation optimization, so it was great to read it anyway.
- #109: A take-away for you. You’ve learned a lot about the query planner throughout the course of this talk! You now have a better understanding of when we can answer a nested logical query using indexes. You can use your knowledge of the query planner to ensure queries will fully utilize your indexes.
- #110: We take feedback from customers and the support team seriously to make the product better in meaningful ways. This project came entirely as a result of the support team reporting this issue. If you find you are not getting the query plan that you would expect, please file a ticket! We’re listening.
- #111: Thank you all for your attention. I’ll be around after the talk, if you have any questions.