Information Extraction from Web-Scale N-Gram Data
3 likes1,843 views

The document discusses information extraction from web-scale n-gram data, emphasizing user preferences for structured data that provides direct answers rather than unstructured documents. It outlines the challenges of extraction, such as rare pattern matches and the need for larger corpora, while introducing n-gram statistics derived from extensive textual data as a potential solution. The document also describes an extraction algorithm that relies on seed tuples and n-gram patterns to identify and rank candidate tuples for structured data.











![Information Extraction
Introduction
and the love of friends' [p] Happy as the grass was green' [p] Come live with me, and be my
lawns swoop around the sunken garden. The grass is emerald green and perfect-a tribute to
overlooking the silver river. All round her the grass stretched green, but stunted, browning in the
the ground steadied beneath them, and the grass turned green, swishing high around their
to see the sun shine, the flowers blossom, the grass grow green. I could not bear to hear the
are quite dwarf. M. sinensis. Chinese silver grass. Ample green- and silver-striped foliage but
in either of them." It was summer and the grass was green. Clive Rappaport was a solicitor,
however, each bank is lined with stands of grass that remain green and stand taller than the
groaned and farted and schemed for snatches of grass that showed green at the corners of his bits,
the flowers were blossoming profusely and the grass was richly green. The people of the village
Song. [f] He is dead and gone; At his head a grass-green turf, At his heels a stone." O, ho! [f]
hard thoughts I stand by popple scrub, in tall grass, blown over and harsh, green and dry. From my
Well the sky is blue and er [tc text=pause] the grass is green and [tc text=pause] there's
Yes. Yes. [F01] Dreadful things. Erm so the grass was never quite as green [ZF1] as [ZF0] as
be beautiful on there really beautiful. All the grass lush and green not a car parked on it
Information Extraction
Users generally want
information,
not documents
Structured data
Direct, instant answers
... and more
Where do we obtain
such data?
3 / 27
Information Extraction from Web-Scale N-Gram Data](https://image.slidesharecdn.com/informationextractionfromweb-scalen-gramdata-140618124855-phpapp01/85/Information-Extraction-from-Web-Scale-N-Gram-Data-12-320.jpg)





























































Information Extraction from Web-Scale N-Gram Data
- 1. Information Extraction from Web-Scale N-Gram Data Niket Tandon and Gerard de Melo 2010-07-23 Max Planck Institute for Informatics Saarbr¨ucken, Germany 1 / 27 Information Extraction from Web-Scale N-Gram Data
- 2. Information Extraction Outline 1 Information Extraction 2 N-Gram Information Extraction 3 Experiments 4 Conclusion 2 / 27 Information Extraction from Web-Scale N-Gram Data
- 3. Information Extraction Introduction Information Extraction Users generally want information, not documents 3 / 27 Information Extraction from Web-Scale N-Gram Data
- 4. Information Extraction Introduction Information Extraction Users generally want information, not documents Structured data Direct, instant answers 3 / 27 Information Extraction from Web-Scale N-Gram Data
- 5. Information Extraction Introduction Information Extraction Users generally want information, not documents Structured data Direct, instant answers 3 / 27 Information Extraction from Web-Scale N-Gram Data
- 6. Information Extraction Introduction Information Extraction Users generally want information, not documents Structured data Direct, instant answers 3 / 27 Information Extraction from Web-Scale N-Gram Data
- 7. Information Extraction Introduction Information Extraction Users generally want information, not documents Structured data Direct, instant answers 3 / 27 Information Extraction from Web-Scale N-Gram Data
- 8. Information Extraction Introduction Other Applications Query expansion Semantic analysis Faceted search Entity Tracking Document Enrichment Mobile Services Visual Object Recognition etc. Information Extraction Users generally want information, not documents Structured data Direct, instant answers ... and more 3 / 27 Information Extraction from Web-Scale N-Gram Data
- 9. Information Extraction Introduction Information Extraction Users generally want information, not documents Structured data Direct, instant answers ... and more Where do we obtain such data? 3 / 27 Information Extraction from Web-Scale N-Gram Data
- 10. Information Extraction Introduction Information Extraction Users generally want information, not documents Structured data Direct, instant answers ... and more Where do we obtain such data? 3 / 27 Information Extraction from Web-Scale N-Gram Data
- 11. Information Extraction Introduction Information Extraction Users generally want information, not documents Structured data Direct, instant answers ... and more Where do we obtain such data? 3 / 27 Information Extraction from Web-Scale N-Gram Data
- 12. Information Extraction Introduction and the love of friends' [p] Happy as the grass was green' [p] Come live with me, and be my lawns swoop around the sunken garden. The grass is emerald green and perfect-a tribute to overlooking the silver river. All round her the grass stretched green, but stunted, browning in the the ground steadied beneath them, and the grass turned green, swishing high around their to see the sun shine, the flowers blossom, the grass grow green. I could not bear to hear the are quite dwarf. M. sinensis. Chinese silver grass. Ample green- and silver-striped foliage but in either of them." It was summer and the grass was green. Clive Rappaport was a solicitor, however, each bank is lined with stands of grass that remain green and stand taller than the groaned and farted and schemed for snatches of grass that showed green at the corners of his bits, the flowers were blossoming profusely and the grass was richly green. The people of the village Song. [f] He is dead and gone; At his head a grass-green turf, At his heels a stone." O, ho! [f] hard thoughts I stand by popple scrub, in tall grass, blown over and harsh, green and dry. From my Well the sky is blue and er [tc text=pause] the grass is green and [tc text=pause] there's Yes. Yes. [F01] Dreadful things. Erm so the grass was never quite as green [ZF1] as [ZF0] as be beautiful on there really beautiful. All the grass lush and green not a car parked on it Information Extraction Users generally want information, not documents Structured data Direct, instant answers ... and more Where do we obtain such data? 3 / 27 Information Extraction from Web-Scale N-Gram Data
- 13. Information Extraction How do we get Structured Data? Structured Data isA(Guggenheim,Museum) locatedIn(Guggenheim,Manhattan) partOf(Manhattan,NewYork) . . . 4 / 27 Information Extraction from Web-Scale N-Gram Data
- 14. Information Extraction How do we get Structured Data? Pattern-Based Approaches Use simple textual patterns to extract information (Lyons 1977, Cruse 1986, Hearst 1992) 5 / 27 Information Extraction from Web-Scale N-Gram Data
- 15. Information Extraction How do we get Structured Data? Pattern-Based Approaches Use simple textual patterns to extract information (Lyons 1977, Cruse 1986, Hearst 1992) e.g. “<Y> such as <X>” “cities such as Salem” isA(Salem,City) 5 / 27 Information Extraction from Web-Scale N-Gram Data
- 16. Information Extraction How do we get Structured Data? Pattern-Based Approaches Use simple textual patterns to extract information (Lyons 1977, Cruse 1986, Hearst 1992) e.g. “<Y> such as <X>” “cities such as Salem” isA(Salem,City) e.g. “<X> and other <Y>” “Lausanne and other cities” isA(Lausanne,City) 5 / 27 Information Extraction from Web-Scale N-Gram Data
- 17. Information Extraction How do we get Structured Data? Problem: Pattern Matches are Rare Hearst found only 46 facts in 20 million word New York Times article collection 6 / 27 Information Extraction from Web-Scale N-Gram Data
- 18. Information Extraction How do we get Structured Data? Problem: Pattern Matches are Rare Hearst found only 46 facts in 20 million word New York Times article collection One Possibility: Sophisticated NLP (1990s) MUC evaluation initiative CRF-style segmentation methods etc. 6 / 27 Information Extraction from Web-Scale N-Gram Data
- 19. Information Extraction How do we get Structured Data? Problem: Pattern Matches are Rare Hearst found only 46 facts in 20 million word New York Times article collection Alternative: Use Larger Corpora American National Corpus: 22 million words 6 / 27 Information Extraction from Web-Scale N-Gram Data
- 20. Information Extraction How do we get Structured Data? Problem: Pattern Matches are Rare Hearst found only 46 facts in 20 million word New York Times article collection Alternative: Use Larger Corpora American National Corpus: 22 million words British National Corpus: 100 million words 6 / 27 Information Extraction from Web-Scale N-Gram Data
- 21. Information Extraction How do we get Structured Data? Problem: Pattern Matches are Rare Hearst found only 46 facts in 20 million word New York Times article collection Alternative: Use Larger Corpora American National Corpus: 22 million words British National Corpus: 100 million words English Wikipedia: 1 000 million words 6 / 27 Information Extraction from Web-Scale N-Gram Data
- 22. Information Extraction How do we get Structured Data? Problem: Pattern Matches are Rare Hearst found only 46 facts in 20 million word New York Times article collection Alternative: Use Larger Corpora American National Corpus: 22 million words British National Corpus: 100 million words English Wikipedia: 1 000 million words Agichtein (2005), Pantel (2004): scalable IE, but still only a small fraction of the entire Web 6 / 27 Information Extraction from Web-Scale N-Gram Data
- 23. Information Extraction Web Search Engines 7 / 27 Information Extraction from Web-Scale N-Gram Data
- 24. Information Extraction Web Search Engines Problems Need to know what you’re looking for. Can only retrieve top-k results Very slow: days instead of minutes – Cafarella (2005) 7 / 27 Information Extraction from Web-Scale N-Gram Data
- 25. Information Extraction Web Search Engines Problems Need to know what you’re looking for. Can only retrieve top-k results Very slow: days instead of minutes – Cafarella (2005) Instead Use n-gram statistics derived from very large parts of the Web! 7 / 27 Information Extraction from Web-Scale N-Gram Data
- 26. N-Gram Information Extraction Outline 1 Information Extraction 2 N-Gram Information Extraction 3 Experiments 4 Conclusion 8 / 27 Information Extraction from Web-Scale N-Gram Data
- 27. N-Gram Information Extraction N-Gram Data Web-Scale N-Gram Datasets Web-scale n-gram statistics derived from around 1012 words of text are available 9 / 27 Information Extraction from Web-Scale N-Gram Data
- 28. N-Gram Information Extraction N-Gram Data Web-Scale N-Gram Datasets Web-scale n-gram statistics derived from around 1012 words of text are available Provides: Frequencies/Language model for strings Example: f(“cities such as Geneva”)=... f(“Z¨urich and other cities”)=... f(“Lausanne and other Swiss cities”)=... 9 / 27 Information Extraction from Web-Scale N-Gram Data
- 29. N-Gram Information Extraction N-Gram Information Extraction Requirements usually binary relationships between entities ok: if independently extractable, e.g. founding year and location of organization not ok: “<V> imported <W> dollars worth of <X> from <Y> in year <Z>” 10 / 27 Information Extraction from Web-Scale N-Gram Data
- 30. N-Gram Information Extraction N-Gram Information Extraction Requirements usually binary relationships between entities short items of interest ok: birthYear(Mozart,1756) 10 / 27 Information Extraction from Web-Scale N-Gram Data
- 31. N-Gram Information Extraction N-Gram Information Extraction Requirements usually binary relationships between entities short items of interest ok: birthYear(Mozart,1756) not: fatherOf(Wolfgang Amadeus Mozart,F. X. Mozart) 10 / 27 Information Extraction from Web-Scale N-Gram Data
- 32. N-Gram Information Extraction N-Gram Information Extraction Requirements usually binary relationships between entities short items of interest no way: fatherOf(Johannes Chrysostomus Wolfgangus Theophilus Mozart, Franz Xaver Wolfgang Mozart) 10 / 27 Information Extraction from Web-Scale N-Gram Data
- 33. N-Gram Information Extraction N-Gram Information Extraction Requirements usually binary relationships between entities short items of interest short patterns ok: “<X> and other <Y>” not: “<X> has an inflation rate of <Y>” 10 / 27 Information Extraction from Web-Scale N-Gram Data
- 34. N-Gram Information Extraction N-Gram Information Extraction Risks Influence of spam and boilerplate text 11 / 27 Information Extraction from Web-Scale N-Gram Data
- 35. N-Gram Information Extraction N-Gram Information Extraction Risks Influence of spam and boilerplate text Less control over the selection of input documents 11 / 27 Information Extraction from Web-Scale N-Gram Data
- 36. N-Gram Information Extraction N-Gram Information Extraction Risks Influence of spam and boilerplate text Less control over the selection of input documents Less context information (WSD, POS tagging, parsing) 11 / 27 Information Extraction from Web-Scale N-Gram Data
- 37. N-Gram Information Extraction N-Gram Information Extraction Then why use n-grams? much larger input (petabytes of original data) better coverage higher precision (more evidence, more redundancy) Pantel (2004): more data allows a rather simple technique to outperform much more sophisticated algorithms 12 / 27 Information Extraction from Web-Scale N-Gram Data
- 38. N-Gram Information Extraction N-Gram Information Extraction Then why use n-grams? much larger input (petabytes of original data) better coverage higher precision (more evidence, more redundancy) Pantel (2004): more data allows a rather simple technique to outperform much more sophisticated algorithms availability larger than available document collections crawling the Web: slow, requires link farm detection, high bandwidth 12 / 27 Information Extraction from Web-Scale N-Gram Data
- 39. N-Gram Information Extraction Information Extraction Algorithm 1 collect patterns 13 / 27 Information Extraction from Web-Scale N-Gram Data
- 40. N-Gram Information Extraction Information Extraction Algorithm 1 collect patterns input: seed tuples for a relation e.g. for isA relation: (dogs,animals), (gold,metal) e.g. for partOf: (finger,hand), (leaves,trees), (windows,houses) 13 / 27 Information Extraction from Web-Scale N-Gram Data
- 41. N-Gram Information Extraction Information Extraction Algorithm 1 collect patterns input: seed tuples for a relation find n-grams containing seeds query n-gram dataset: “dogs * animals” (and “animals * dogs”) alternatively: “dogs ? animals”, “dogs ? ? animals”, . . . alternatively: fall back to separate document collection 13 / 27 Information Extraction from Web-Scale N-Gram Data
- 42. N-Gram Information Extraction Information Extraction Algorithm 1 collect patterns input: seed tuples for a relation find n-grams containing seeds generalize to textual patterns (dogs,animals) found in “.... dogs and other animals ...” “<X> and other <Y>” 13 / 27 Information Extraction from Web-Scale N-Gram Data
- 43. N-Gram Information Extraction Information Extraction Algorithm 1 collect patterns input: seed tuples for a relation find n-grams containing seeds generalize to textual patterns 2 Search for patterns in n-grams data candidate tuples “<X> and other <Y>” finds (Z¨urich,cities) “Z¨urich and other cities” (apples,fruits) “apples and other fruits” 13 / 27 Information Extraction from Web-Scale N-Gram Data
- 44. N-Gram Information Extraction Information Extraction Algorithm 1 collect patterns input: seed tuples for a relation find n-grams containing seeds generalize to textual patterns 2 Search for patterns in n-grams data candidate tuples 3 Finally, rank the candidate tuples, choose output tuples Supervised learning based on labeled set of tuples Output: Accepted tuples like (Geneva,city). 13 / 27 Information Extraction from Web-Scale N-Gram Data
- 45. N-Gram Information Extraction Information Extraction Algorithm 1 collect patterns input: seed tuples for a relation find n-grams containing seeds generalize to textual patterns 2 Search for patterns in n-grams data candidate tuples 3 Finally, rank the candidate tuples, choose output tuples Features: for a tuple (x, y) fi (p(x, y)) for each datasource i and pattern p p∈P fi (p(x, y)) for each datasource i 13 / 27 Information Extraction from Web-Scale N-Gram Data
- 46. Experiments Outline 1 Information Extraction 2 N-Gram Information Extraction 3 Experiments 4 Conclusion 14 / 27 Information Extraction from Web-Scale N-Gram Data
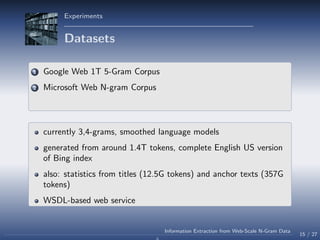
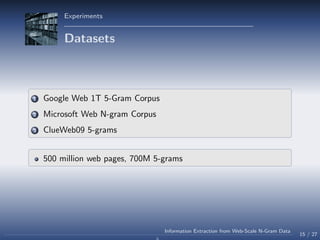
- 47. Experiments Datasets 1 Google Web 1T 5-Gram Corpus contains n-gram statistics for n = 1 . . . 5 15 / 27 Information Extraction from Web-Scale N-Gram Data
- 48. Experiments Datasets 1 Google Web 1T 5-Gram Corpus contains n-gram statistics for n = 1 . . . 5 generated from around 1012 words of text 15 / 27 Information Extraction from Web-Scale N-Gram Data
- 49. Experiments Datasets 1 Google Web 1T 5-Gram Corpus contains n-gram statistics for n = 1 . . . 5 generated from around 1012 words of text positive: distributed (around 60GB uncompressed) 15 / 27 Information Extraction from Web-Scale N-Gram Data
- 50. Experiments Datasets 1 Google Web 1T 5-Gram Corpus contains n-gram statistics for n = 1 . . . 5 generated from around 1012 words of text positive: distributed (around 60GB uncompressed) negative: cut-off frequency 40 15 / 27 Information Extraction from Web-Scale N-Gram Data
- 51. Experiments Datasets 1 Google Web 1T 5-Gram Corpus 2 Microsoft Web N-gram Corpus currently 3,4-grams, smoothed language models 15 / 27 Information Extraction from Web-Scale N-Gram Data
- 52. Experiments Datasets 1 Google Web 1T 5-Gram Corpus 2 Microsoft Web N-gram Corpus currently 3,4-grams, smoothed language models generated from around 1.4T tokens, complete English US version of Bing index 15 / 27 Information Extraction from Web-Scale N-Gram Data
- 53. Experiments Datasets 1 Google Web 1T 5-Gram Corpus 2 Microsoft Web N-gram Corpus currently 3,4-grams, smoothed language models generated from around 1.4T tokens, complete English US version of Bing index also: statistics from titles (12.5G tokens) and anchor texts (357G tokens) 15 / 27 Information Extraction from Web-Scale N-Gram Data
- 54. Experiments Datasets 1 Google Web 1T 5-Gram Corpus 2 Microsoft Web N-gram Corpus currently 3,4-grams, smoothed language models generated from around 1.4T tokens, complete English US version of Bing index also: statistics from titles (12.5G tokens) and anchor texts (357G tokens) WSDL-based web service 15 / 27 Information Extraction from Web-Scale N-Gram Data
- 55. Experiments Datasets 1 Google Web 1T 5-Gram Corpus 2 Microsoft Web N-gram Corpus 3 ClueWeb09 5-grams 500 million web pages, 700M 5-grams 15 / 27 Information Extraction from Web-Scale N-Gram Data
- 56. Experiments Seeds and Patterns Patterns Relation Seeds discovered isA 100 2991 partOf 100 3883 hasProperty 100 3175 seeds from MIT ConceptNet even among highest-ranked: partOf(children,parents) and isA(winning,everything) 16 / 27 Information Extraction from Web-Scale N-Gram Data
- 57. Experiments Pattern Examples: isA Pattern PMI range <X> and almost any <Y> high <X> betting basketball betting <Y> high <X> is my favorite <Y> high <X> shoes online shoes <Y> high <X> is a <Y> medium <X> is the best <Y> medium <X> or any other <Y> medium <X> , and <Y> medium <X> and other smart <Y> medium <X> and grammar <Y> low <X> content of the <Y> low <X> when it changes <Y> low 17 / 27 Information Extraction from Web-Scale N-Gram Data
- 58. Experiments Pattern Examples: partOf Pattern PMI range <X> with the other <Y> high <X> of the top <Y> high <X> online <Y> high <X> shoes online shoes <Y> high <X> from the <Y> medium <X> or even entire <Y> medium <X> of host <Y> medium <X> from <Y> medium <X> of a different <Y> medium <X> entertainment and <Y> low <X> Download for thou <Y> low <X> company home in <Y> low 18 / 27 Information Extraction from Web-Scale N-Gram Data
- 59. Experiments Pattern: Microsoft Document Body 3- grams vs. Anchor 3-grams (each point represents the sum of pattern scores for a tuple) 19 / 27 Information Extraction from Web-Scale N-Gram Data
- 60. Experiments Patterns: Microsoft Document Body 3- grams vs. Title 3-grams (each point represents the sum of pattern scores for a tuple) 20 / 27 Information Extraction from Web-Scale N-Gram Data
- 61. Experiments Patterns: Microsoft Document Body 3- grams vs. Google Body 3-grams (each point represents the sum of pattern scores for a tuple) 21 / 27 Information Extraction from Web-Scale N-Gram Data
- 62. Experiments Overall Results (all data sources simultaneously) Approach learning: RBF-kernel SVMs, also: random forests, C4.5, AdaBoost 22 / 27 Information Extraction from Web-Scale N-Gram Data
- 63. Experiments Overall Results (all data sources simultaneously) Approach learning: RBF-kernel SVMs, also: random forests, C4.5, AdaBoost ∼ 500 random labelled examples per relation (matching any of the patterns) 22 / 27 Information Extraction from Web-Scale N-Gram Data
- 64. Experiments Overall Results (all data sources simultaneously) Approach learning: RBF-kernel SVMs, also: random forests, C4.5, AdaBoost ∼ 500 random labelled examples per relation (matching any of the patterns) 10-fold leave one out cross-validation 22 / 27 Information Extraction from Web-Scale N-Gram Data
- 65. Experiments Overall Results (all data sources simultaneously) Approach learning: RBF-kernel SVMs, also: random forests, C4.5, AdaBoost ∼ 500 random labelled examples per relation (matching any of the patterns) 10-fold leave one out cross-validation =⇒ Recall is relative to union of pattern matches 22 / 27 Information Extraction from Web-Scale N-Gram Data
- 66. Experiments Overall Results (all data sources simultaneously) Relation Precision Recall F1 Output per million n-grams1 isA 88.9% 8.1% 14.8% 983 partOf 80.5% 34.0% 47.8% 7897 hasProperty 75.3% 99.3% 85.6% 26180 1: the expected number of distinct accepted tuples per million input n-grams (the total number of 5-grams in the Google Web 1T dataset is ∼1,176 million) 22 / 27 Information Extraction from Web-Scale N-Gram Data
- 67. Experiments Overall Results (all data sources simultaneously) Relation Precision Recall F1 Output per million n-grams1 isA 88.9% 8.1% 14.8% 983 partOf 80.5% 34.0% 47.8% 7897 hasProperty 75.3% 99.3% 85.6% 26180 1: the expected number of distinct accepted tuples per million input n-grams (the total number of 5-grams in the Google Web 1T dataset is ∼1,176 million) linguistic information implicitly captured via combinations of patterns! 22 / 27 Information Extraction from Web-Scale N-Gram Data
- 68. Experiments Detailed Results (partOf relation) Dataset Source Prec. Recall F1 Google 3-grams Document Body 55.9% 38.5% 45.6% Google 4-grams Document Body 52.6% 43.3% 47.5% Google 5-grams Document Body 48.1% 42.8% 45.3% ClueWeb 5-grams Document Body 51.7% 35.6% 42.2% Google 3-/4- grams Document Body 53.9% 42.8% 47.7% Google 3-/4-/5- grams Document Body 58.7% 43.8% 50.1% 23 / 27 Information Extraction from Web-Scale N-Gram Data
- 69. Experiments Detailed Results (partOf relation) Dataset Source Prec. Recall F1 Microsoft 3-grams Document Body 58.5% 33.2% 42.3% Microsoft 3-grams Document Title 51.7% 29.8% 37.8% Microsoft 3-grams Anchor Text 57.3% 36.1% 44.2% Microsoft 3-grams Body / Title / Anchor 40.4% 100.0% 57.5% Google 3-grams Document Body 55.9% 38.5% 45.6% Microsoft 3/4- grams Body (3-grams only) / Title / Anchor 40.5% 98.1% 57.3% Google 3/4- grams Document Body 53.9% 42.8% 47.7% Google 3/4/5- grams Document Body 58.7% 43.8% 50.1% All 3/4/5- grams Body / Title / Anchor 80.5% 34.0% 47.8% 24 / 27 Information Extraction from Web-Scale N-Gram Data
- 70. Experiments Example: hasProperty Properties of “flowers” 25 / 27 Information Extraction from Web-Scale N-Gram Data
- 71. Conclusion Outline 1 Information Extraction 2 N-Gram Information Extraction 3 Experiments 4 Conclusion 26 / 27 Information Extraction from Web-Scale N-Gram Data
- 72. Conclusion Summary Lessons Learnt N-grams datasets allow for Information Extraction from petabytes of original data 27 / 27 Information Extraction from Web-Scale N-Gram Data
- 73. Conclusion Summary Lessons Learnt N-grams datasets allow for Information Extraction from petabytes of original data Requirements: short entity names, short patterns 27 / 27 Information Extraction from Web-Scale N-Gram Data
- 74. Conclusion Summary Lessons Learnt N-grams datasets allow for Information Extraction from petabytes of original data Requirements: short entity names, short patterns more data helps (even at very large scales) 27 / 27 Information Extraction from Web-Scale N-Gram Data
- 75. Conclusion Summary Lessons Learnt N-grams datasets allow for Information Extraction from petabytes of original data Requirements: short entity names, short patterns more data helps (even at very large scales) diversity of data sources helps 27 / 27 Information Extraction from Web-Scale N-Gram Data